
Hugging Face 是自然语言处理领域的金矿,它包含各种预先训练的语言模型,非常容易在不同应用程序中使用。说到大型语言模型 (LLM),Hugging Face 是首选。在本文中,我们将深入探讨 Hugging Face 上的十大 LLM,它们都在促进我们理解和生成语言的方式方面发挥着关键作用。

让我们开始吧!
什么是大型语言模型?
大型语言模型 (LLM) 是一种先进的人工智能,旨在理解和生成人类语言。它们是使用深度学习技术构建的,特别是一种称为 Transformer 的神经网络。
为了更清楚起见,我们来细分一下:
- 海量数据训练:法学硕士接受大量数据集的训练,这些数据集包括书籍、文章、网站等。这种广泛的训练有助于他们学习语言的细微差别,包括语法、上下文,甚至某种程度的推理。
- Transformers :大多数 LLM 背后的架构称为 Transformer。该模型使用注意力机制来衡量句子中不同单词的重要性,使其能够比以前的模型更好地理解上下文。
- 他们执行的任务:经过培训后,法学硕士可以执行各种语言任务。这些任务包括回答问题、总结文本、翻译语言、创作创意文章和编码。
- 热门模型:一些著名的 LLM 包括 GPT-3、BERT 和 T5。这些预训练模型可以针对特定任务进行微调,使其成为开发人员和研究人员的多功能工具。
- 应用:LLM 可用于聊天机器人、虚拟助手、自动内容创建等。它们通过使机器更自然地理解和响应人类语言来帮助改善用户与技术的交互。
本质上,大型语言模型就像计算机的增强型大脑,使它们能够以令人印象深刻的准确性和多功能性处理和生成人类语言。
HuggingFace 和法学硕士
Hugging Face 是一家公司和平台,已成为自然语言处理 (NLP) 和机器学习的中心。他们提供工具、库和资源,让开发人员和研究人员能够更轻松地构建和使用机器学习模型,尤其是与语言理解和生成相关的模型。
Hugging Face 以其开源库而闻名,尤其是Transformers ,它可以轻松访问各种预训练的语言模型。
Hugging Face 拥有许多最先进的 LLM,例如 GPT-3、BERT 和 T5。这些模型已在海量数据集上进行了预训练,可用于各种应用。
该平台提供了简单的 API 和工具,可将这些模型集成到应用程序中,而无需机器学习方面的深厚专业知识。
使用 Hugging Face 的工具,您可以轻松地根据自己的数据对这些预先训练的 LLM 进行微调,从而使它们适应特定的任务或领域。
研究人员和开发人员可以在 Hugging Face 平台上分享他们的模型和增强功能,加速 NLP 领域的创新和应用。
您应该使用的 Huggingface 上的 5 大 LLM 模型
让我们来探索一下 Hugging Face 上的一些擅长讲故事甚至超越 GPT 的顶级 LLM 模型。
米斯特拉尔-7B-v0.1
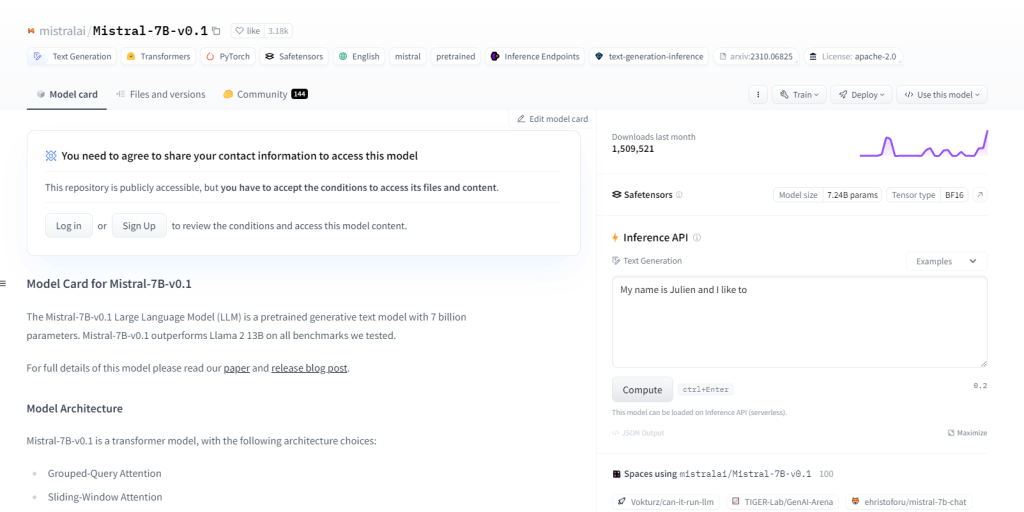
Mistral-7B-v0.1 是一个大型语言模型 (LLM),拥有 70 亿个参数,在各个领域的表现都优于 Llama 2 13B 等基准测试。它采用了具有特定注意机制的 Transformer 架构和字节回退 BPE 标记器。它在文本生成、自然语言理解、语言翻译方面表现出色,可作为 NLP 项目研发的基础模型。
主要特征
- 70 亿个参数
- 超越 Llama 213B 等基准
- Transformer 架构
- BPE 标记器
- NLP项目开发
- 自然语言理解
- 语言翻译
- 分组查询注意力机制
椋鸟-LM-11B-alpha
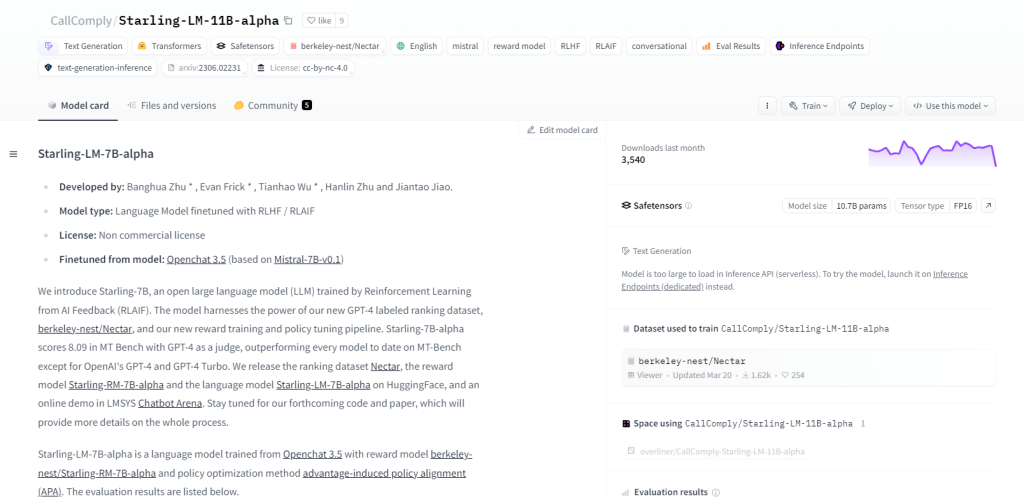
Starling-LM-11B-alpha 是一个大型语言模型 (LLM),拥有 110 亿个参数,由 NurtureAI 推出,以 OpenChat 3.5 模型为基础。微调是通过人工智能反馈强化学习 (RLAIF) 实现的,由人工标记的排名引导。该模型有望通过其开源框架和多种应用重塑人机交互,包括 NLP 任务、机器学习研究、教育和创意内容生成。
主要特征
- 110 亿个参数
- 由 NurtureAI 开发
- 基于OpenChat 3.5模型
- 通过 RLAIF 进行微调
- 用于训练的人工标记排名
- 开源特性
- 多样化能力
- 用于研究、教育和创意内容生成
Yi-34B-骆驼
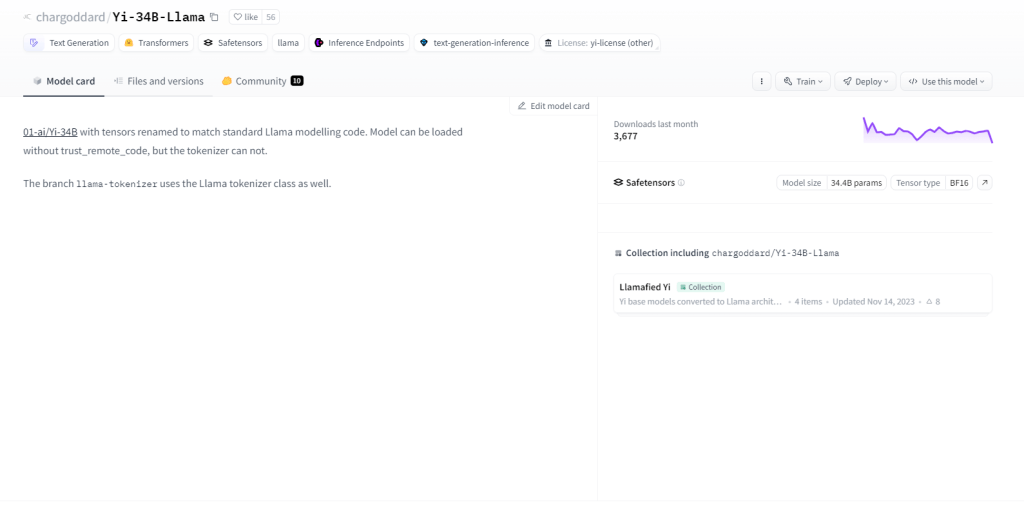
Yi-34B-Llama 拥有 340 亿个参数,展现出卓越的学习能力。它在多模态处理方面表现出色,能够高效处理文本、代码和图像。它采用零样本学习,能够无缝适应新任务。其状态特性使其能够记住过去的互动,从而增强用户参与度。用例包括文本生成、机器翻译、问答、对话、代码生成和图像字幕。
主要特征
- 340 亿个参数
- 多模态处理
- 零样本学习能力
- 有状态的性质
- 文本生成
- 机器翻译
- 问答
- 图像字幕
DeepSeek LLM 67B 基础
DeepSeek LLM 67B Base 是一个 670 亿参数的大型语言模型 (LLM),在推理、编码和数学任务中表现出色。其优异的成绩超越了 GPT-3.5 和 Llama2 70B Base,在代码理解和生成方面表现出色,并展示了非凡的数学技能。其在 MIT 许可下的开源性质使其可以自由探索。用例涵盖编程、教育、研究、内容创建、翻译和问答。
主要特征
- 670 亿个参数
- 推理、编码和数学方面表现优异
- HumanEval Pass@1 得分为 73.78
- 出色的代码理解和生成
- GSM8K 0-shot 高分 (84.1)
- 语言能力超越GPT-3.5
- 根据 MIT 许可证开放源代码
- 出色的讲故事和内容创作能力。
Skote - Svelte 管理和仪表板模板
Marcoroni-7B-v3 是一个强大的 70 亿参数多语言生成模型,能够执行各种任务,包括文本生成、语言翻译、创意内容创作和问答。它在处理文本和代码方面表现出色,利用零样本学习快速完成任务,而无需事先进行训练。Marcoroni-7B-v3 是开源的,并遵循宽松的许可,因此可以广泛使用和实验。
主要特征
- 诗歌、代码、脚本、电子邮件等的文本生成。
- 高精度机器翻译。
- 创建具有自然对话功能的引人入胜的聊天机器人。
- 从自然语言描述生成代码。
- 全面的问答能力。
- 将冗长的文字概括为简洁的摘要。
- 有效的释义同时保留原文含义。
- 文本内容的情感分析。
包起来
Hugging Face 的大型语言模型集合对于开发人员、研究人员和爱好者来说都是一个改变游戏规则的技术。这些模型凭借其多样化的架构和功能,在推动自然语言理解和生成的界限方面发挥了重要作用。随着技术的发展,这些模型的应用和影响是无穷无尽的。探索和创新大型语言模型的旅程仍在继续,未来将迎来令人兴奋的发展。







