
人工智能文本转视频技术的兴起正在彻底改变我们创作和消费内容的方式。走在这场变革最前沿的是强大的 Hugging Face 模型,它们正迅速成为内容创作者和企业的首选工具。

这些最先进的语言模型经过大量数据的训练,具有将书面文字转化为引人入胜的视觉叙事的非凡能力。通过利用自然语言处理和生成式 AI 的最新进展,Hugging Face 模型可以毫不费力地将您的文字转化为引人入胜的高质量视频,吸引您的观众。
了解文本转视频技术
文本转视频模型将书面描述转换为动态图像。这些模型理解文本并将其转换为描述场景或动作的帧序列。此过程涉及多个步骤,包括文本分析、视觉内容生成和帧排序。每个步骤都需要复杂的算法来确保输出视频准确表示输入文本。
文本转视频技术的发展始于简单的文本描述生成基本动画。早期模型专注于创建静态图像,但人工智能和机器学习的进步推动了动态视频生成的发展。多年来,研究人员整合了复杂的神经网络,显著提高了视频质量和真实感。这些进步为创意内容创作和跨行业的各种应用开辟了新的可能性。
Huggingface 的 5 个最佳文本转视频 AI 模型
这里我们列出了 huggingface 的 5 个最佳 AI 文本转视频模型。这些模型因其独特的功能而广受欢迎,下载次数最多。
模型范围-1.7b
ModelScope 的文本到视频合成模型使用多阶段扩散过程从文本描述生成视频。此高级模型仅支持英文输入,专为研究目的而设计。它由三个子网络组成:文本特征提取、文本到视频潜在空间扩散和视频潜在空间到视觉空间映射。
它拥有 17 亿个参数和 UNet3D 结构,可以迭代去噪高斯噪声来制作视频。该模型适用于各种应用,例如从任意英文文本制作视频。但它存在局限性,例如训练数据存在偏差,无法制作高质量的电影级视频或清晰的文本。用户必须避免生成有害或虚假内容。该模型在公开数据集上进行训练,包括 LAION5B、ImageNet 和 Webvid。
主要特点
- 多阶段扩散过程
- 英文文本支持
- 17 亿个参数
- UNet3D 架构
- 迭代去噪方法
- 研究目的重点
- 公共数据集训练
- 任意文本生成
AnimateDiff-Lightning
AnimateDiff-Lightning 是一种先进的文本转视频生成模型,与原始 AnimateDiff 相比,其速度有所提升,视频生成速度提高了十倍以上。该模型基于 AnimateDiff SD1.5 v2 开发而成,提供 1 步、2 步、4 步和 8 步版本,其中更高步数的模型可提供更优质的质量。当与 epiCRealism 和 Realistic Vision 等风格化基础模型以及 ToonYou 和 Mistoon Anime 等动漫和卡通模型一起使用时,效果会非常出色。
用户可以通过尝试不同的设置(例如使用 Motion LoRA)来获得最佳效果。在实施方面,该模型可以与 Diffusers 和 ComfyUI 一起使用。它支持使用 ControlNet 进行视频到视频生成,以增强输出。有关更多详细信息和演示,建议用户参考研究论文:AnimateDiff-Lightning:跨模型扩散蒸馏
主要特点
- 闪电般的视频生成
- 从 AnimateDiff 中提取
- 多步骤检查点
- 高生成质量
- 支持风格化模型
- 运动 LoRA 支持
- 现实和卡通选项
- 视频到视频的生成
零点示波器 V2
基于 Modelscope 的 zeroscope_v2_567w 视频模型擅长制作无水印的高质量 16:9 视频。该模型在 576x320 分辨率和 24 帧/秒的速率下对 9,923 个剪辑和 29,769 个标记帧进行了训练,是流畅视频输出的理想选择。该模型设计用于初始渲染,然后使用 1111 text2video 扩展中的 vid2vid 使用 zeroscope_v2_XL 进行升级,从而允许在较低分辨率下进行高效探索。
升级到 1024x576 可提供更出色的构图。它使用 7.9GB VRAM 来渲染 30 帧。要使用,请下载并替换相应目录中的文件。
为获得最佳效果,请使用 zeroscope_v2_XL 进行升级,降噪强度介于 0.66 和 0.85 之间。已知问题包括较低分辨率或较少帧时输出效果不佳。使用扩散器可以轻松集成该模型,安装和视频生成步骤简单。
主要特点
- 无水印输出
- 高品质 16:9
- 流畅的视频输出
- 576x320 分辨率
- 每秒 24 帧
- 高效升级
- 显存占用 7.9GB
- 轻松集成
虚拟生成
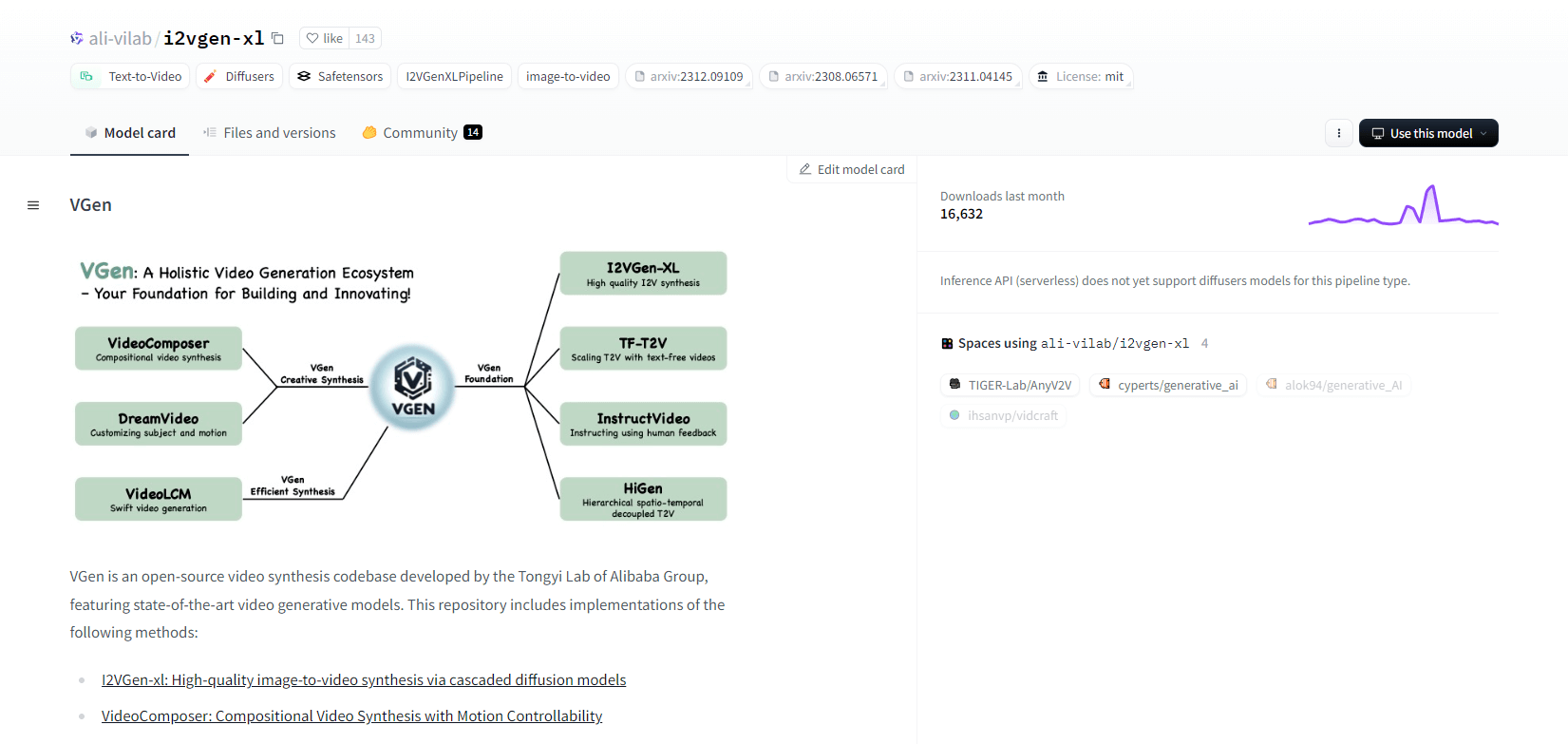
VGen 是阿里巴巴统一实验室推出的开源视频合成代码库,提供先进的视频生成模型。它包括 I2VGen-xl(用于高质量图像到视频合成)、VideoComposer(用于运动可控视频合成)等方法。VGen 可以根据文本、图像、所需运动、主题和反馈信号创建高质量视频。该存储库提供使用图像和视频进行可视化、采样、训练、推理和联合训练的工具。最近的更新包括 VideoLCM、I2VGen-XL 和 DreamVideo 方法。
VGen 在可扩展性、性能和完整性方面表现出色。安装涉及设置 Python 环境和必要的库。用户可以训练文本到视频模型并运行 I2VGen-XL 以生成高清视频。演示数据集和预训练模型可用于促进实验和优化。代码库确保视频合成任务的易于管理和高效性。
主要特点
- 开源代码库
- 高品质合成
- 运动可控性
- 文本转视频
- 图像到视频的转换
- 可扩展框架
- 预训练模型
- 综合工具
热射 XL
Hotshot-XL 是 Natural Synthetics Inc. 开发的 AI 文本转 GIF 模型,可与 Stable Diffusion XL 无缝协作。它支持使用任何经过微调的 SDXL 模型生成 GIF,简化了个性化 GIF 的创建过程,无需额外微调。该模型擅长以每秒 8 帧的速度生成各种宽高比的 1 秒 GIF。它利用 Latent Diffusion 和预训练文本编码器(OpenCLIP-ViT/G 和 CLIP-ViT/L)来增强性能。
用户可以使用 SDXL ControlNet 修改 GIF 构图以实现自定义布局。Hotshot-XL 虽然能够创建多种 GIF,但在照片级真实感和渲染特定构图等复杂任务方面仍面临挑战。该模型的实现旨在顺利集成到现有工作流程中,并可在 CreativeML Open RAIL++-M 许可证下在 GitHub 上进行探索。
主要特点
- 文本到 GIF 生成
- 与 SDXL 兼容
- 生成 1 秒 GIF
- 支持各种宽高比
- 利用潜伏扩散
- 预训练文本编码器
- 可通过 ControlNet 进行定制
- 在 GitHub 上可用
文本转视频 AI 模型的未来功能
Hugging Face 等平台在开发能够将文本转换为高质量动态视频内容的高级模型方面处于领先地位。这让我们假设——文本转视频 AI 模型的未来能力确实令人兴奋。
这些模型有望彻底改变内容创作方式,使其比以往更快、更高效、更易于访问。只需输入文本提示,用户就能生成引人入胜的定制视频,将他们的想法变为现实。
潜在的应用非常广泛 - 从营销和广告到教育和娱乐。想象一下,只需单击一下按钮即可创建专业级的解释视频或动画故事。企业和创作者将节省大量时间和成本。
此外,随着这些文本转视频模型在真实性、连贯性和灵活性方面不断改进,输出的质量将越来越难以与人工制作的视频区分开来。视频制作的民主化将使更多人能够与世界分享他们的故事和想法。
毫无疑问,文本转视频是内容创作的未来,而 Hugging Face 正处于这项变革性技术的前沿。这些模型正在不断突破可能性的界限,请准备好惊叹吧。
总结
总而言之,Huggingface 为文本转视频任务提供了多种模型,每种模型在从文本描述生成动态视觉内容方面都具有独特的优势。无论您优先考虑精度、创造力还是可扩展性,这些模型都能为各种应用提供强大的解决方案,有望推动 AI 驱动的视频合成的发展。







