
Ôm mặt là một mỏ vàng dành cho bất kỳ ai quan tâm đến xử lý ngôn ngữ tự nhiên, được tích hợp nhiều mô hình ngôn ngữ được đào tạo trước, siêu dễ sử dụng trong các ứng dụng khác nhau. Khi nói đến Mô hình ngôn ngữ lớn (LLM), Ôm mặt là lựa chọn hàng đầu. Trong phần này, chúng ta sẽ đi sâu vào 10 LLM hàng đầu trên Ôm Mặt, mỗi LLM đóng vai trò then chốt trong việc nâng cao cách chúng ta hiểu và tạo ra ngôn ngữ.

Bắt đầu nào!
Mô hình ngôn ngữ lớn là gì?
Mô hình ngôn ngữ lớn (LLM) là loại trí tuệ nhân tạo tiên tiến được thiết kế để hiểu và tạo ra ngôn ngữ của con người. Chúng được xây dựng bằng cách sử dụng các kỹ thuật học sâu, đặc biệt là một loại mạng lưới thần kinh được gọi là máy biến áp.
Đây là một sự cố để làm cho nó rõ ràng:
- Đào tạo về dữ liệu lớn : LLM được đào tạo về các bộ dữ liệu khổng lồ bao gồm sách, bài viết, trang web, v.v. Khóa đào tạo mở rộng này giúp họ tìm hiểu các sắc thái của ngôn ngữ, bao gồm ngữ pháp, ngữ cảnh và thậm chí một số cấp độ lý luận.
- Máy biến áp : Kiến trúc đằng sau hầu hết các LLM được gọi là máy biến áp. Mô hình này sử dụng cơ chế chú ý để cân nhắc tầm quan trọng của các từ khác nhau trong câu, cho phép nó hiểu ngữ cảnh tốt hơn các mô hình trước đó.
- Nhiệm vụ họ thực hiện : Sau khi được đào tạo, LLM có thể thực hiện nhiều nhiệm vụ ngôn ngữ khác nhau. Chúng bao gồm trả lời câu hỏi, tóm tắt văn bản, dịch ngôn ngữ, tạo văn bản sáng tạo và mã hóa.
- Các mô hình phổ biến : Một số LLM nổi tiếng bao gồm GPT-3, BERT và T5. Những mô hình được đào tạo trước này có thể được tinh chỉnh cho các nhiệm vụ cụ thể, biến chúng thành công cụ linh hoạt cho các nhà phát triển và nhà nghiên cứu.
- Ứng dụng : LLM được sử dụng trong chatbot, trợ lý ảo, tạo nội dung tự động, v.v. Chúng giúp cải thiện tương tác của người dùng với công nghệ bằng cách làm cho máy móc hiểu và phản hồi ngôn ngữ của con người một cách tự nhiên hơn.
Về bản chất, Mô hình ngôn ngữ lớn giống như bộ não được tăng áp cho máy tính, cho phép chúng xử lý và tạo ra ngôn ngữ của con người với độ chính xác và tính linh hoạt ấn tượng.
Ôm Mặt & LLM
Ôm Mặt là một công ty và một nền tảng trở thành trung tâm xử lý ngôn ngữ tự nhiên (NLP) và học máy. Họ cung cấp các công cụ, thư viện và tài nguyên để giúp các nhà phát triển và nhà nghiên cứu xây dựng và sử dụng các mô hình học máy dễ dàng hơn, đặc biệt là những mô hình liên quan đến hiểu và tạo ngôn ngữ.
Ôm Mặt được biết đến với các thư viện mã nguồn mở, đặc biệt là Transformers , cho phép truy cập dễ dàng vào nhiều mô hình ngôn ngữ được đào tạo trước.
Ôm Mặt lưu trữ nhiều LLM hiện đại như GPT-3, BERT và T5. Những mô hình này được đào tạo trước trên bộ dữ liệu lớn và sẵn sàng sử dụng cho nhiều ứng dụng khác nhau.
Nền tảng này cung cấp các API và công cụ đơn giản để tích hợp các mô hình này vào các ứng dụng mà không yêu cầu chuyên môn sâu về học máy.
Bằng cách sử dụng các công cụ của Hugging Face, bạn có thể dễ dàng tinh chỉnh các LLM được đào tạo trước này trên dữ liệu của riêng mình, cho phép bạn điều chỉnh chúng cho phù hợp với các nhiệm vụ hoặc miền cụ thể.
Các nhà nghiên cứu và nhà phát triển có thể chia sẻ các mô hình và cải tiến của họ trên nền tảng Ôm mặt, thúc đẩy đổi mới và ứng dụng trong NLP.
Top 5 Mô Hình LLM Trên Huggingface Bạn Nên Sử Dụng
Hãy cùng khám phá một số mô hình LLM hàng đầu trên Ôm Mặt có khả năng kể chuyện vượt trội và thậm chí vượt qua GPT.
Mistral-7B-v0.1
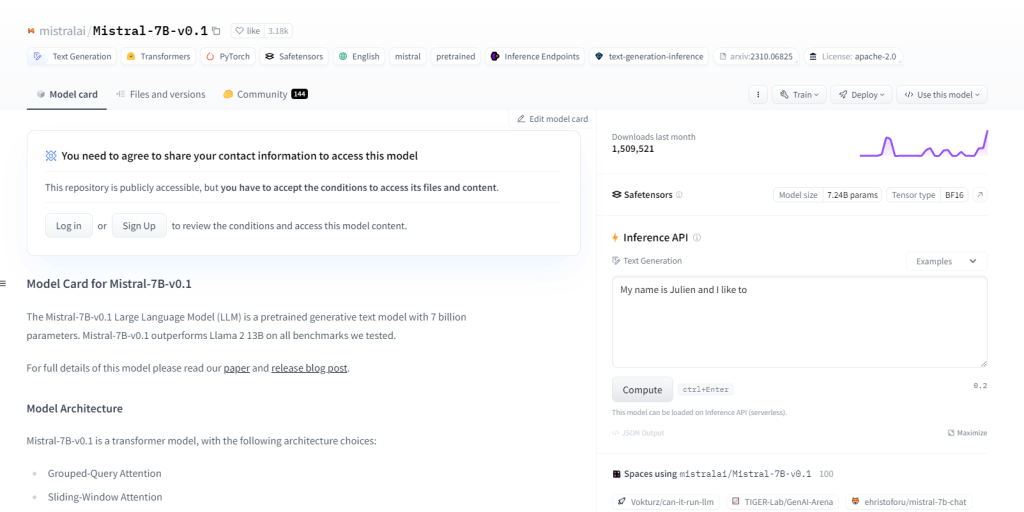
Mistral-7B-v0.1, Mô hình ngôn ngữ lớn (LLM) với 7 tỷ tham số, vượt trội so với các điểm chuẩn như Llama 2 13B trên các miền. Nó sử dụng kiến trúc máy biến áp với các cơ chế chú ý cụ thể và mã thông báo BPE dự phòng Byte. Nó vượt trội trong việc tạo văn bản, hiểu ngôn ngữ tự nhiên, dịch ngôn ngữ và đóng vai trò là mô hình cơ sở cho nghiên cứu và phát triển trong các dự án NLP.
Các tính năng chính
- 7 tỷ thông số
- Vượt benchmark như Llama 213B
- Kiến trúc máy biến áp
- Mã thông báo BPE
- Phát triển dự án NLP
- Hiểu ngôn ngữ tự nhiên
- Dịch ngôn ngữ
- Chú ý truy vấn được nhóm
Sáo-LM-11B-alpha
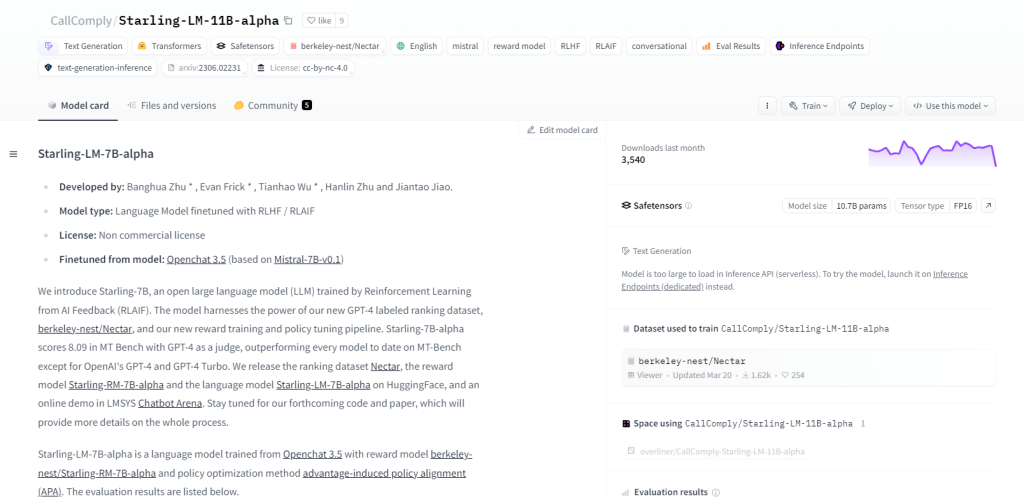
Starling-LM-11B-alpha, một mô hình ngôn ngữ lớn (LLM) với 11 tỷ tham số, xuất hiện từ NurtureAI, tận dụng mô hình OpenChat 3.5 làm cơ sở. Việc tinh chỉnh đạt được thông qua Học tập tăng cường từ Phản hồi AI (RLAIF), được hướng dẫn bởi bảng xếp hạng do con người gắn nhãn. Mô hình này hứa hẹn sẽ định hình lại sự tương tác giữa con người và máy móc với khung nguồn mở và các ứng dụng linh hoạt, bao gồm các nhiệm vụ NLP, nghiên cứu học máy, giáo dục và tạo nội dung sáng tạo.
Các tính năng chính
- 11 tỷ thông số
- Được phát triển bởi NurtureAI
- Dựa trên mô hình OpenChat 3.5
- Tinh chỉnh thông qua RLAIF
- Xếp hạng do con người gắn nhãn cho đào tạo
- Bản chất nguồn mở
- Khả năng đa dạng
- Sử dụng cho nghiên cứu, giáo dục và tạo nội dung sáng tạo
Yi-34B-Llama
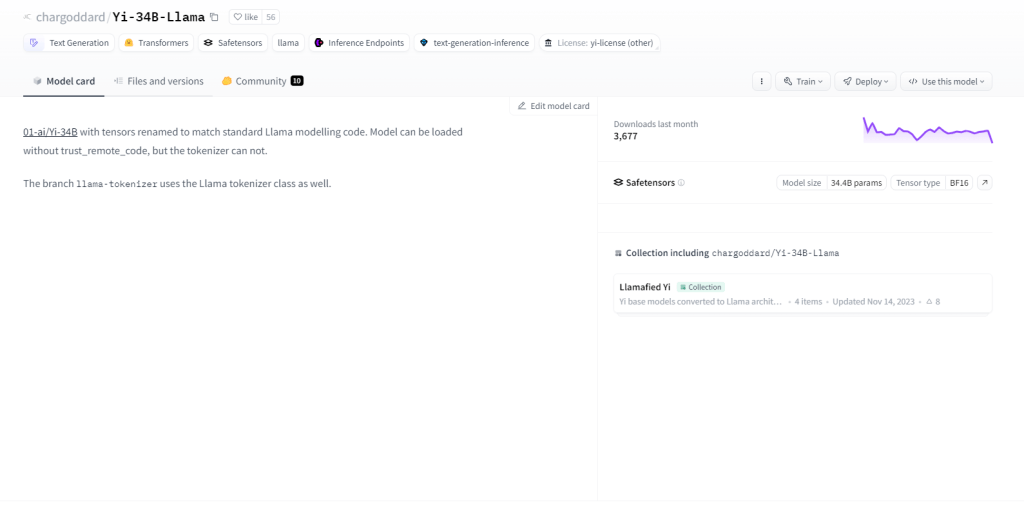
Yi-34B-Llama, với 34 tỷ thông số, thể hiện khả năng học tập vượt trội. Nó vượt trội trong việc xử lý đa phương thức, xử lý văn bản, mã và hình ảnh một cách hiệu quả. Áp dụng phương pháp học tập không cần nỗ lực, nó thích ứng với các nhiệm vụ mới một cách liền mạch. Bản chất trạng thái của nó cho phép nó ghi nhớ các tương tác trong quá khứ, nâng cao mức độ tương tác của người dùng. Các trường hợp sử dụng bao gồm tạo văn bản, dịch máy, trả lời câu hỏi, đối thoại, tạo mã và chú thích hình ảnh.
Các tính năng chính
- 34 tỷ thông số
- Xử lý đa phương thức
- Khả năng học tập không cần bắn
- Tính chất trạng thái
- tạo văn bản
- Dịch máy
- Trả lời câu hỏi
- Chú thích hình ảnh
Cơ sở DeepSeek LLM 67B
DeepSeek LLM 67B Base, một mô hình ngôn ngữ lớn (LLM) có 67 tỷ tham số, tỏa sáng trong các nhiệm vụ lý luận, mã hóa và toán học. Với điểm số vượt trội vượt qua GPT-3.5 và Llama2 70B Base, nó vượt trội về khả năng hiểu và tạo mã cũng như thể hiện các kỹ năng toán học vượt trội. Bản chất nguồn mở của nó theo giấy phép MIT cho phép khám phá miễn phí. Các trường hợp sử dụng bao gồm lập trình, giáo dục, nghiên cứu, tạo nội dung, dịch thuật và trả lời câu hỏi.
Các tính năng chính
- thông số 67 tỷ
- Hiệu suất vượt trội trong lý luận, mã hóa và toán học
- HumanEval Pass@1 điểm 73,78
- Sự hiểu biết và tạo mã vượt trội
- Điểm cao trên GSM8K 0 ảnh (84,1)
- Vượt qua GPT-3.5 về khả năng ngôn ngữ
- Nguồn mở theo giấy phép MIT
- Khả năng kể chuyện và sáng tạo nội dung tuyệt vời.
Skote - Mẫu bảng điều khiển và quản trị Svelte
Marcoroni-7B-v3 là mô hình tạo đa ngôn ngữ mạnh mẽ gồm 7 tỷ tham số, có khả năng thực hiện các tác vụ đa dạng, bao gồm tạo văn bản, dịch ngôn ngữ, tạo nội dung sáng tạo và trả lời câu hỏi. Nó vượt trội trong việc xử lý cả văn bản và mã, tận dụng phương pháp học tập không cần thực hiện để thực hiện nhiệm vụ nhanh chóng mà không cần đào tạo trước. Nguồn mở và theo giấy phép cho phép, Marcoroni-7B-v3 tạo điều kiện cho việc sử dụng và thử nghiệm rộng rãi.
Các tính năng chính
- Tạo văn bản cho các bài thơ, mã, kịch bản, email, v.v.
- Dịch máy có độ chính xác cao.
- Tạo các chatbot hấp dẫn với các cuộc trò chuyện tự nhiên.
- Tạo mã từ các mô tả ngôn ngữ tự nhiên.
- Khả năng trả lời câu hỏi toàn diện.
- Tóm tắt các văn bản dài thành những bản tóm tắt ngắn gọn.
- Diễn giải hiệu quả trong khi vẫn giữ được ý nghĩa ban đầu.
- Phân tích tình cảm cho nội dung văn bản.
Kết thúc
Bộ sưu tập các mô hình ngôn ngữ lớn của Hugging Face là công cụ thay đổi cuộc chơi cho các nhà phát triển, nhà nghiên cứu cũng như những người đam mê. Những mô hình này đóng một vai trò lớn trong việc mở rộng ranh giới của việc hiểu và tạo ngôn ngữ tự nhiên nhờ vào kiến trúc và khả năng đa dạng của chúng. Khi công nghệ ngày càng phát triển, ứng dụng và tác động của những mô hình này là vô tận. Hành trình khám phá và đổi mới với Mô hình ngôn ngữ lớn đang diễn ra, hứa hẹn những bước phát triển thú vị phía trước.







