
Sự phát triển của công nghệ chuyển văn bản thành video hỗ trợ AI đang cách mạng hóa cách chúng ta tạo và tiêu thụ nội dung. Đi đầu trong sự chuyển đổi này là các mô hình Hugging Face mạnh mẽ, đang nhanh chóng trở thành công cụ phổ biến cho cả người sáng tạo nội dung và doanh nghiệp.

Những mô hình ngôn ngữ tiên tiến này, được đào tạo trên kho dữ liệu khổng lồ, có khả năng đáng chú ý là dịch văn bản viết thành những câu chuyện trực quan hấp dẫn. Bằng cách tận dụng những tiến bộ mới nhất trong xử lý ngôn ngữ tự nhiên và AI tạo sinh, các mô hình Hugging Face có thể dễ dàng chuyển đổi lời nói của bạn thành những video hấp dẫn, chất lượng cao, thu hút khán giả của bạn.
Hiểu về công nghệ Text-to-Video
Các mô hình văn bản thành video chuyển đổi các mô tả bằng văn bản thành hình ảnh chuyển động. Các mô hình này hiểu văn bản và chuyển đổi thành một chuỗi các khung hình mô tả cảnh hoặc hành động được mô tả. Quá trình này bao gồm nhiều bước, bao gồm phân tích văn bản, tạo nội dung trực quan và sắp xếp khung hình. Mỗi bước yêu cầu các thuật toán phức tạp để đảm bảo video đầu ra thể hiện chính xác văn bản đầu vào.
Hành trình của công nghệ chuyển văn bản thành video bắt đầu bằng các mô tả văn bản đơn giản tạo ra các hình ảnh động cơ bản. Các mô hình ban đầu tập trung vào việc tạo hình ảnh tĩnh, nhưng những tiến bộ trong AI và máy học đã cho phép phát triển việc tạo video động. Trong nhiều năm, các nhà nghiên cứu đã tích hợp các mạng nơ-ron tinh vi, dẫn đến những cải tiến đáng kể về chất lượng và tính chân thực của video. Những tiến bộ này đã mở ra những khả năng mới cho việc tạo nội dung sáng tạo và nhiều ứng dụng khác nhau trong các ngành công nghiệp.
5 Mô hình AI chuyển văn bản thành video tốt nhất từ Huggingface
Dưới đây là 5 mô hình chuyển văn bản thành video AI tốt nhất từ hugingface. Những mô hình này rất phổ biến vì chức năng riêng biệt của chúng và có số lượt tải xuống nhiều nhất.
Phạm vi mô hình - 1.7b
Mô hình tổng hợp văn bản thành video từ ModelScope sử dụng quy trình khuếch tán nhiều giai đoạn để tạo video từ mô tả văn bản. Mô hình tiên tiến này chỉ hỗ trợ đầu vào tiếng Anh và được thiết kế cho mục đích nghiên cứu. Nó bao gồm ba mạng con: trích xuất tính năng văn bản, khuếch tán không gian tiềm ẩn văn bản thành video và ánh xạ không gian tiềm ẩn video thành không gian trực quan.
Với 1,7 tỷ tham số và cấu trúc UNet3D, nó khử nhiễu Gauss theo từng bước để tạo video. Mô hình này phù hợp với nhiều ứng dụng khác nhau, như tạo video từ văn bản tiếng Anh tùy ý. Tuy nhiên, nó có những hạn chế, chẳng hạn như sai lệch từ dữ liệu đào tạo và không thể tạo video chất lượng cao ở cấp độ phim hoặc văn bản rõ ràng. Người dùng phải tránh tạo nội dung có hại hoặc sai lệch. Mô hình được đào tạo trên các tập dữ liệu công khai, bao gồm LAION5B, ImageNet và Webvid.
Các tính năng chính
- Quá trình khuếch tán nhiều giai đoạn
- Hỗ trợ văn bản tiếng Anh
- 1,7 tỷ tham số
- Kiến trúc UNet3D
- Phương pháp khử nhiễu lặp lại
- Tập trung mục đích nghiên cứu
- Đào tạo tập dữ liệu công khai
- Tạo văn bản tùy ý
AnimateDiff-Ánh sáng
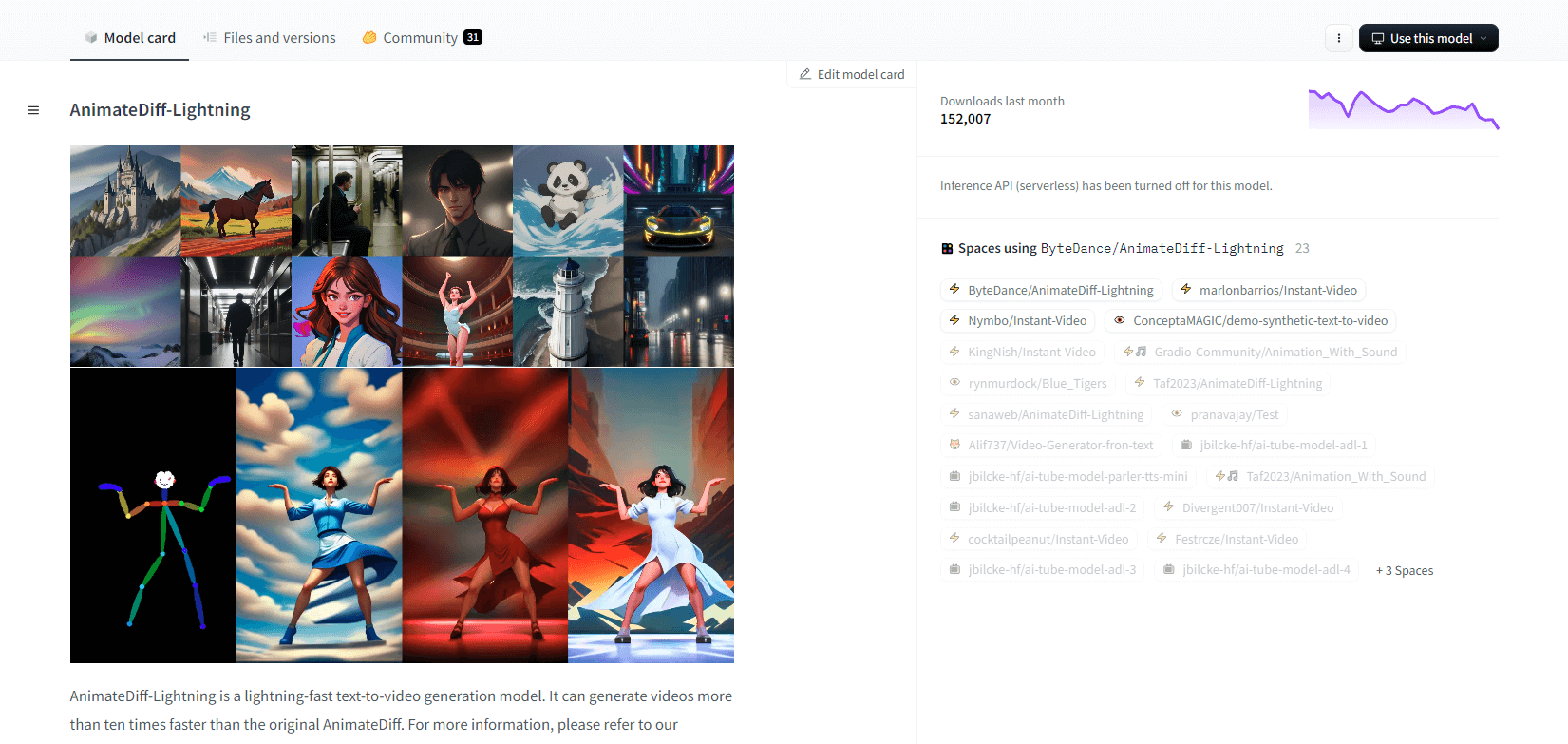
AnimateDiff-Lightning là mô hình tạo văn bản thành video tiên tiến, cải thiện tốc độ so với AnimateDiff gốc, tạo video nhanh hơn gấp mười lần. Được phát triển từ AnimateDiff SD1.5 v2, mô hình này có sẵn ở các phiên bản 1 bước, 2 bước, 4 bước và 8 bước, với các mô hình bước cao hơn cung cấp chất lượng vượt trội. Nó nổi trội khi sử dụng với các mô hình cơ sở cách điệu như epiCRealism và Realistic Vision, cũng như các mô hình anime và hoạt hình như ToonYou và Mistoon Anime.
Người dùng có thể đạt được kết quả tối ưu bằng cách thử nghiệm với các thiết lập khác nhau, chẳng hạn như sử dụng Motion LoRA. Để triển khai, mô hình có thể được sử dụng với Diffusers và ComfyUI. Nó hỗ trợ tạo video-to-video với ControlNet để tăng cường đầu ra. Để biết thêm chi tiết và bản demo, người dùng được khuyến khích tham khảo bài báo nghiên cứu: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Các tính năng chính
- Tạo video nhanh như chớp
- Trích từ AnimateDiff
- Điểm kiểm tra nhiều bước
- Chất lượng thế hệ cao
- Hỗ trợ các mô hình cách điệu
- Hỗ trợ Motion LoRAs
- Tùy chọn thực tế và hoạt hình
- Thế hệ video-to-video
Zeroscope V2
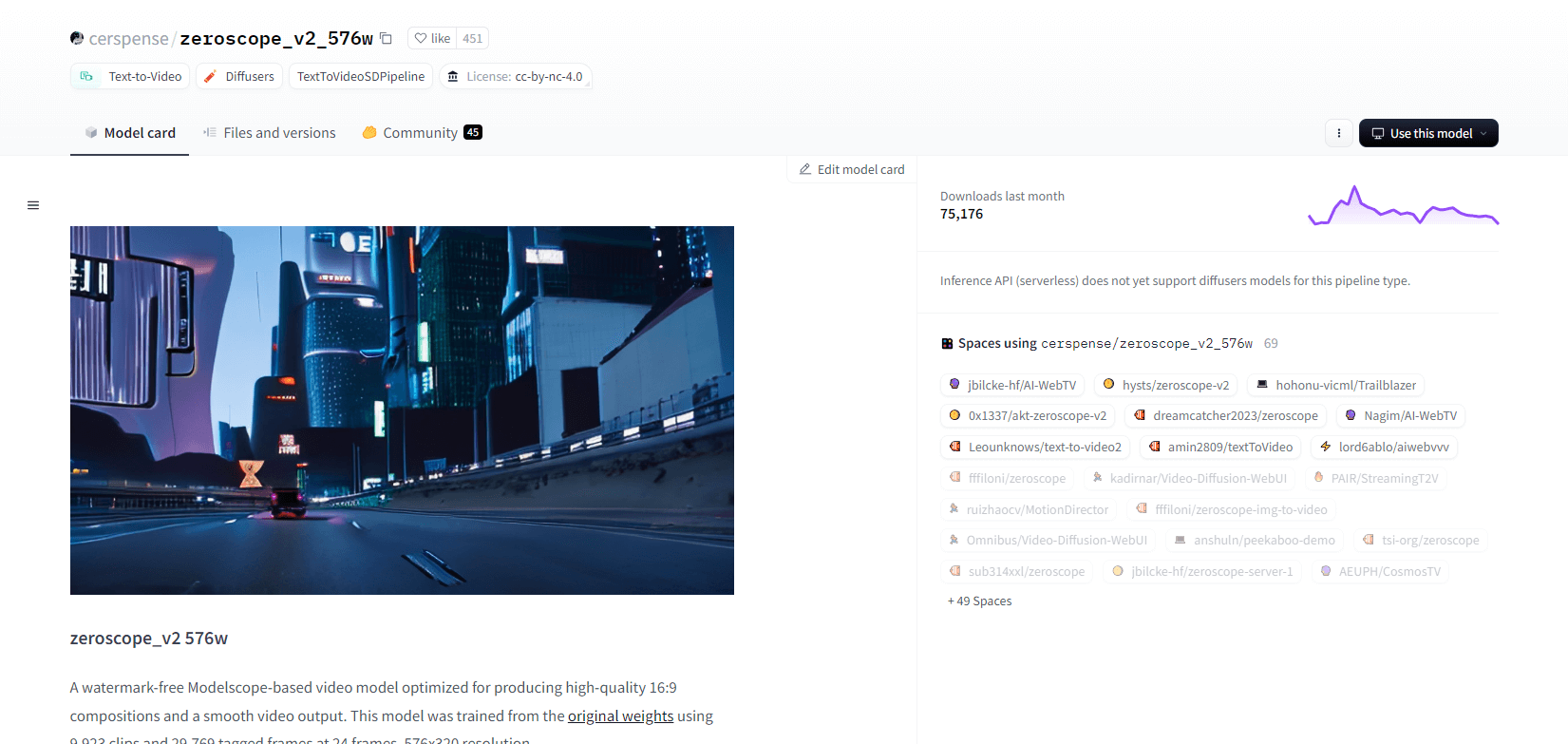
Mô hình video zeroscope_v2_567w dựa trên Modelscope rất tuyệt vời trong việc tạo video 16:9 chất lượng cao mà không có hình mờ. Được đào tạo trên 9.923 clip và 29.769 khung được gắn thẻ ở độ phân giải 576x320 và 24 khung hình mỗi giây, mô hình này lý tưởng cho đầu ra video mượt mà. Mô hình này được thiết kế để dựng hình ban đầu trước khi nâng cấp với zeroscope_v2_XL bằng cách sử dụng vid2vid trong phần mở rộng 1111 text2video, cho phép khám phá hiệu quả ở độ phân giải thấp hơn.
Nâng cấp lên 1024x576 cung cấp các thành phần vượt trội. Nó sử dụng 7,9 GB VRAM để kết xuất 30 khung hình. Để sử dụng, hãy tải xuống và thay thế các tệp trong thư mục thích hợp.
Để có kết quả tốt nhất, hãy nâng cấp bằng zeroscope_v2_XL với cường độ khử nhiễu từ 0,66 đến 0,85. Các vấn đề đã biết bao gồm đầu ra không tối ưu ở độ phân giải thấp hơn hoặc ít khung hình hơn. Mô hình có thể dễ dàng tích hợp bằng Bộ khuếch tán với các bước cài đặt và tạo video đơn giản.
Các tính năng chính
- Đầu ra không có hình mờ
- Chất lượng cao 16:9
- Đầu ra video mượt mà
- Độ phân giải 576x320
- 24 khung hình mỗi giây
- Nâng cấp hiệu quả
- Sử dụng 7,9 GB VRAM
- Tích hợp dễ dàng
VGen
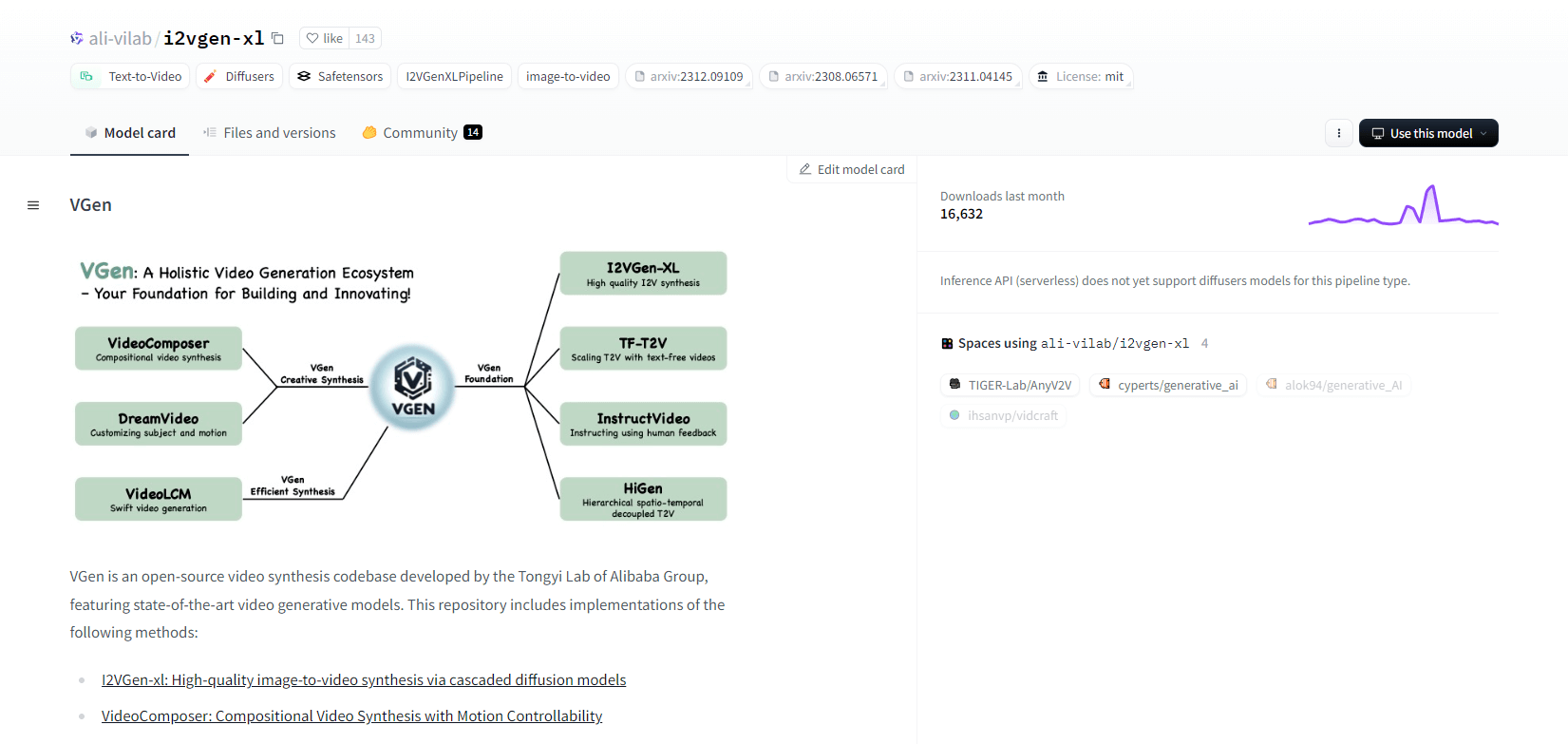
VGen, một cơ sở mã nguồn mở tổng hợp video từ Phòng thí nghiệm Tongyi của Alibaba, cung cấp các mô hình tạo video tiên tiến. Nó bao gồm các phương pháp như I2VGen-xl để tổng hợp hình ảnh thành video chất lượng cao, VideoComposer để tổng hợp video có thể điều khiển chuyển động, v.v. VGen có thể tạo video chất lượng cao từ văn bản, hình ảnh, chuyển động mong muốn, chủ thể và tín hiệu phản hồi. Kho lưu trữ có các công cụ để trực quan hóa, lấy mẫu, đào tạo, suy luận và đào tạo chung bằng hình ảnh và video. Các bản cập nhật gần đây bao gồm VideoLCM, I2VGen-XL và phương pháp DreamVideo.
VGen vượt trội về khả năng mở rộng, hiệu suất và tính hoàn thiện. Việc cài đặt bao gồm thiết lập môi trường Python và các thư viện cần thiết. Người dùng có thể đào tạo các mô hình văn bản thành video và chạy I2VGen-XL để tạo video độ nét cao. Các tập dữ liệu demo và các mô hình được đào tạo trước có sẵn để tạo điều kiện cho việc thử nghiệm và tối ưu hóa. Cơ sở mã đảm bảo quản lý dễ dàng và hiệu quả cao trong các tác vụ tổng hợp video.
Các tính năng chính
- Cơ sở mã nguồn mở
- Tổng hợp chất lượng cao
- Khả năng điều khiển chuyển động
- Tạo văn bản thành video
- Chuyển đổi hình ảnh sang video
- Khung mở rộng
- Các mô hình được đào tạo trước
- Công cụ toàn diện
Hotshot XL
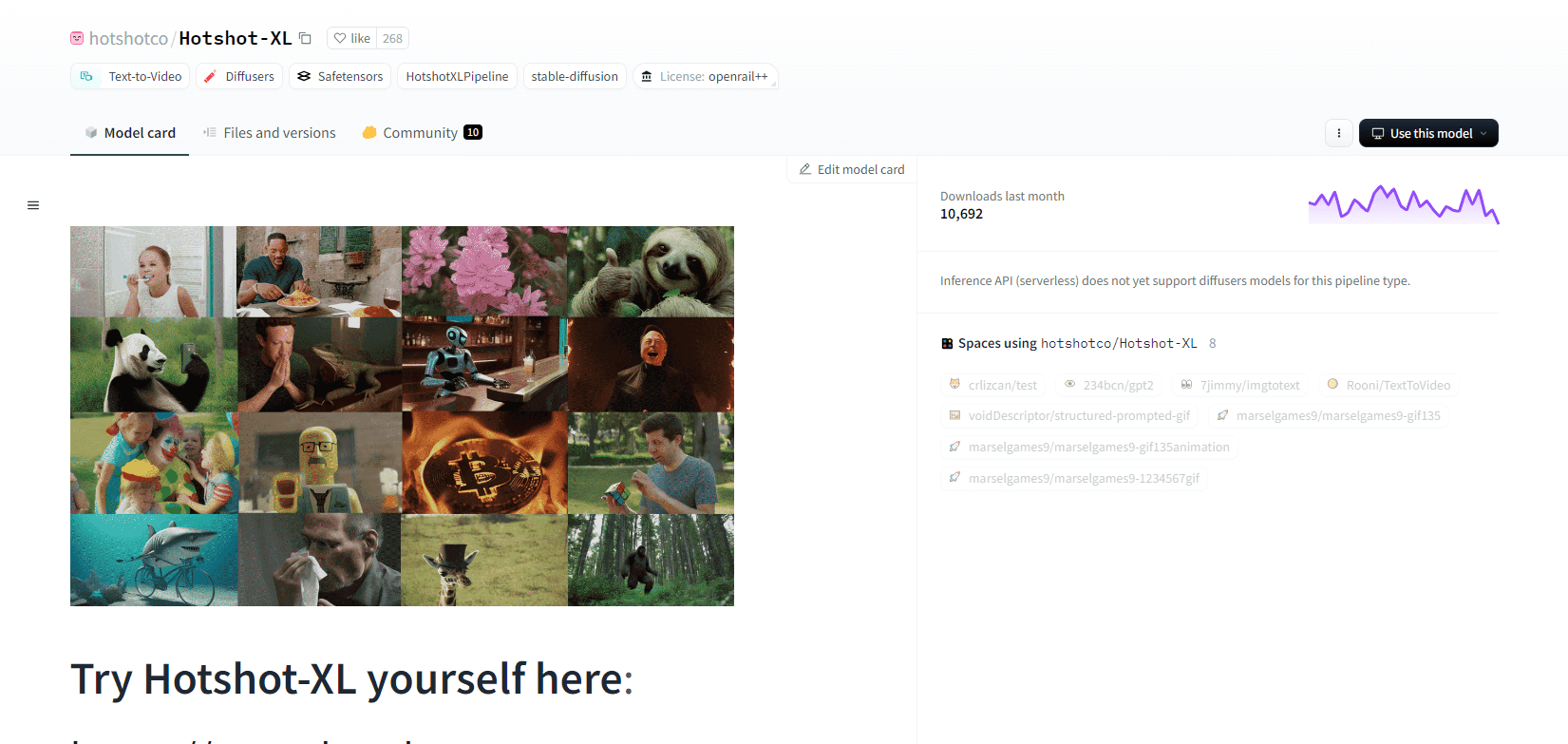
Hotshot-XL, một mô hình AI text-to-GIF do Natural Synthetics Inc. phát triển, hoạt động liền mạch với Stable Diffusion XL. Nó cho phép tạo GIF bằng bất kỳ mô hình SDXL nào được tinh chỉnh, giúp đơn giản hóa việc tạo GIF được cá nhân hóa mà không cần tinh chỉnh thêm. Mô hình này xuất sắc trong việc tạo GIF 1 giây ở tốc độ 8 khung hình mỗi giây trên nhiều tỷ lệ khung hình khác nhau. Nó tận dụng Latent Diffusion với các bộ mã hóa văn bản được đào tạo trước (OpenCLIP-ViT/G và CLIP-ViT/L) để nâng cao hiệu suất.
Người dùng có thể chỉnh sửa các thành phần GIF bằng SDXL ControlNet để có các bố cục tùy chỉnh. Mặc dù có khả năng tạo GIF đa năng, Hotshot-XL phải đối mặt với những thách thức về tính chân thực và các tác vụ phức tạp như kết xuất các thành phần cụ thể. Việc triển khai mô hình này nhằm mục đích tích hợp trơn tru vào các quy trình làm việc hiện có và có sẵn để khám phá trên GitHub theo Giấy phép CreativeML Open RAIL++-M.
Các tính năng chính
- Tạo văn bản thành GIF
- Hoạt động với SDXL
- Tạo GIF 1 giây
- Hỗ trợ nhiều tỷ lệ khung hình khác nhau
- Sử dụng khuếch tán tiềm ẩn
- Bộ mã hóa văn bản được đào tạo trước
- Có thể tùy chỉnh với ControlNet
- Có sẵn trên GitHub
Khả năng tương lai của mô hình AI chuyển văn bản thành video
Các nền tảng như Hugging Face đang dẫn đầu trong việc phát triển các mô hình tiên tiến có thể chuyển đổi văn bản thành nội dung video động, chất lượng cao. Điều này dẫn chúng ta đến giả định rằng - khả năng tương lai của các mô hình AI chuyển văn bản thành video thực sự thú vị.
Những mô hình này được thiết kế để cách mạng hóa việc tạo nội dung, giúp việc này nhanh hơn, hiệu quả hơn và dễ tiếp cận hơn bao giờ hết. Chỉ cần nhập lời nhắc văn bản, người dùng sẽ có thể tạo video hấp dẫn, tùy chỉnh để biến ý tưởng của họ thành hiện thực.
Các ứng dụng tiềm năng rất rộng lớn - từ tiếp thị và quảng cáo đến giáo dục và giải trí. Hãy tưởng tượng bạn có thể tạo video giải thích chuyên nghiệp hoặc câu chuyện hoạt hình chỉ bằng một cú nhấp chuột. Tiết kiệm thời gian và chi phí cho doanh nghiệp và người sáng tạo sẽ rất đáng kể.
Hơn nữa, khi các mô hình văn bản thành video này tiếp tục cải thiện về tính chân thực, tính mạch lạc và tính linh hoạt, chất lượng đầu ra sẽ ngày càng không thể phân biệt được với video do con người tạo ra. Sự dân chủ hóa sản xuất video này sẽ trao quyền cho nhiều người hơn để chia sẻ câu chuyện và ý tưởng của họ với thế giới.
Tương lai của việc sáng tạo nội dung chắc chắn là chuyển văn bản thành video và Hugging Face đang đi đầu trong công nghệ chuyển đổi này. Hãy chuẩn bị để ngạc nhiên khi những mô hình này mở rộng ranh giới của những điều có thể.
Kết thúc
Tóm lại, Huggingface cung cấp nhiều mô hình đa dạng cho các tác vụ chuyển văn bản thành video, mỗi mô hình đều có thế mạnh riêng trong việc tạo nội dung trực quan động từ mô tả văn bản. Cho dù bạn ưu tiên độ chính xác, tính sáng tạo hay khả năng mở rộng, các mô hình này đều cung cấp các giải pháp mạnh mẽ cho nhiều ứng dụng khác nhau, hứa hẹn những tiến bộ trong tổng hợp video do AI điều khiển.







