
Yapay zeka destekli metinden videoya dönüştürme teknolojisinin yükselişi, içerik oluşturma ve tüketme biçimimizde devrim yaratıyor. Bu dönüşümün ön saflarında, içerik oluşturucular ve işletmeler için hızla vazgeçilmez araçlar haline gelen güçlü Hugging Face modelleri yer alıyor.

Geniş veri yığınları üzerinde eğitilen bu son teknoloji dil modelleri, yazılı metni büyüleyici görsel anlatılara dönüştürme konusunda olağanüstü bir yeteneğe sahiptir. Doğal dil işleme ve üretken yapay zekadaki en son gelişmelerden yararlanarak, Hugging Face modelleri kelimelerinizi izleyicilerinizi büyüleyen ilgi çekici, yüksek kaliteli videolara zahmetsizce dönüştürebilir.
Metinden Videoya Teknolojisini Anlamak
Metinden videoya modeller, yazılı açıklamaları hareketli görüntülere dönüştürür. Bu modeller metni anlar ve onu, açıklanan sahneyi veya eylemi tasvir eden bir kare dizisine dönüştürür. Bu süreç, metin analizi, görsel içerik oluşturma ve kare dizilemesi dahil olmak üzere birden fazla adımı içerir. Her adım, çıktı videosunun girdi metnini doğru bir şekilde temsil etmesini sağlamak için karmaşık algoritmalar gerektirir.
Metinden videoya teknolojisinin yolculuğu, temel animasyonlar üreten basit metin açıklamalarıyla başladı. İlk modeller statik görüntüler oluşturmaya odaklanmıştı ancak yapay zeka ve makine öğrenimindeki gelişmeler dinamik video üretiminin geliştirilmesini sağladı. Yıllar geçtikçe araştırmacılar, karmaşık sinir ağlarını entegre ederek video kalitesinde ve gerçekçilikte önemli iyileştirmeler sağladı. Bu gelişmeler, yaratıcı içerik oluşturma ve sektörler genelinde çeşitli uygulamalar için yeni olanaklar açtı.
Huggingface'ten En İyi 5 Metinden Videoya AI Modeli
İşte hugface'ten en iyi 5 AI metin-video modelini sunuyoruz. Bu modeller, belirgin işlevsellikleri nedeniyle oldukça popülerdir ve en fazla indirme sayısına sahiptir.
ModelKapsamı - 1.7b
ModelScope'un metinden videoya sentez modeli, metin açıklamalarından videolar üretmek için çok aşamalı bir yayma süreci kullanır. Bu gelişmiş model yalnızca İngilizce girişi destekler ve araştırma amaçları için tasarlanmıştır. Üç alt ağdan oluşur: metin özelliği çıkarma, metinden videoya gizli alan yayılımı ve video gizli alandan görsel alana eşleme.
1,7 milyar parametre ve UNet3D yapısıyla, videolar oluşturmak için Gauss gürültüsünü yinelemeli olarak azaltır. Bu model, keyfi İngilizce metinlerden video oluşturma gibi çeşitli uygulamalar için uygundur. Ancak, eğitim verilerinden kaynaklanan önyargılar ve yüksek kaliteli film seviyesinde videolar veya net metin üretememe gibi sınırlamaları vardır. Kullanıcılar zararlı veya yanlış içerik oluşturmaktan kaçınmalıdır. Model, LAION5B, ImageNet ve Webvid dahil olmak üzere herkese açık veri kümeleri üzerinde eğitildi.
Temel Özellikler
- Çok aşamalı difüzyon süreci
- İngilizce metin desteği
- 1,7 milyar parametre
- UNet3D mimarisi
- Tekrarlı gürültü giderme yöntemi
- Araştırma amacı odak
- Kamu veri seti eğitimi
- Keyfi metin üretimi
AnimateDiff-Yıldırım
AnimateDiff-Lightning, orijinal AnimateDiff'e göre hız iyileştirmeleri sunan, videoları on kat daha hızlı üreten, son teknoloji, metinden videoya üretim modelidir. AnimateDiff SD1.5 v2'den geliştirilen bu model, 1 adımlı, 2 adımlı, 4 adımlı ve 8 adımlı sürümlerde mevcuttur ve daha yüksek adımlı modeller üstün kalite sunar. epiCRealism ve Realistic Vision gibi stilize temel modellerle ve ToonYou ve Mistoon Anime gibi anime ve çizgi film modelleriyle kullanıldığında mükemmeldir.
Kullanıcılar, Motion LoRAs gibi farklı ayarlarla deneyerek en iyi sonuçları elde edebilirler. Uygulama için, model Diffusers ve ComfyUI ile kullanılabilir. Gelişmiş çıktı için ControlNet ile video-video üretimini destekler. Daha fazla ayrıntı ve bir demo için, kullanıcıların araştırma makalesine başvurmaları önerilir: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Temel Özellikler
- Yıldırım hızında video üretimi
- AnimateDiff'ten damıtıldı
- Çok adımlı kontrol noktaları
- Yüksek nesil kalite
- Stilize edilmiş modelleri destekler
- Motion LoRAs desteği
- Gerçekçi ve çizgi film seçenekleri
- Videodan videoya üretim
Sıfırskop V2
Modelscope tabanlı zeroscope_v2_567w video modeli, filigran olmadan yüksek kaliteli 16:9 videolar oluşturmada mükemmeldir. 576x320 çözünürlükte ve saniyede 24 karede 9.923 klip ve 29.769 etiketli kare üzerinde eğitilen bu model, akıcı video çıktısı için idealdir. Bu model, 1111 text2video uzantısında vid2vid kullanılarak zeroscope_v2_XL ile yükseltmeden önce ilk işleme için tasarlanmıştır ve daha düşük çözünürlüklerde verimli keşif sağlar.
1024x576'ya yükseltme üstün kompozisyonlar sağlar. 30 kareyi işlemek için 7,9 GB VRAM kullanır. Kullanmak için uygun dizindeki dosyaları indirin ve değiştirin.
En iyi sonuçlar için, 0,66 ile 0,85 arasında bir gürültü giderme gücüyle zeroscope_v2_XL kullanarak ölçeklendirme yapın. Bilinen sorunlar arasında daha düşük çözünürlüklerde veya daha az karede optimum olmayan çıktı bulunur. Model, basit kurulum ve video oluşturma adımlarıyla Difüzörler kullanılarak kolayca entegre edilebilir.
Temel Özellikler
- Filigran içermeyen çıktı
- Yüksek kaliteli 16:9
- Pürüzsüz video çıkışı
- 576x320 çözünürlük
- Saniyede 24 kare
- Verimli yükseltme
- 7.9GB VRAM kullanımı
- Kolay entegrasyon
VGen
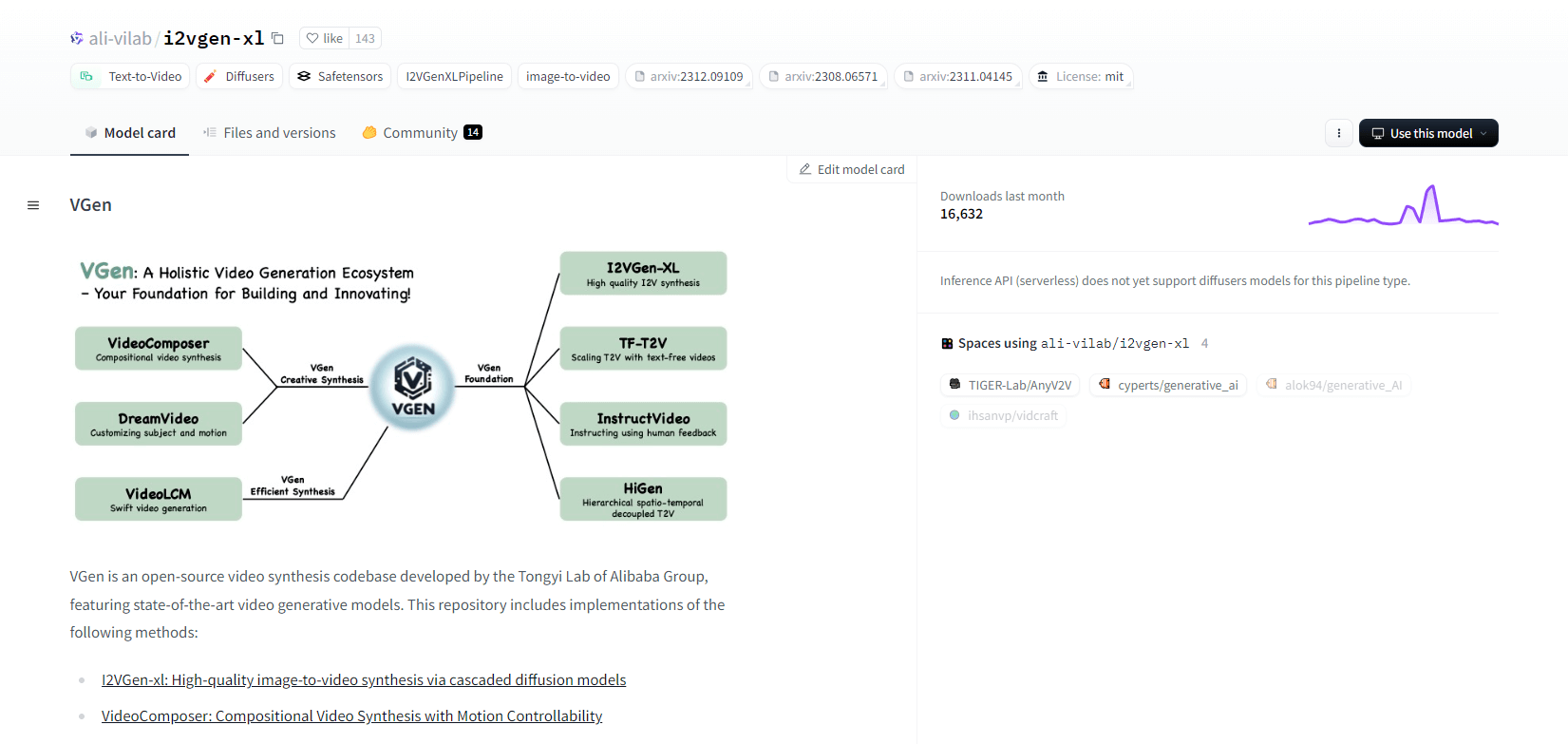
Alibaba'nın Tongyi Lab'ından açık kaynaklı bir video sentezleme kod tabanı olan VGen, gelişmiş video oluşturma modelleri sunar. Yüksek kaliteli görüntü-video sentezi için I2VGen-xl, hareket kontrollü video sentezi için VideoComposer ve daha fazlası gibi yöntemleri içerir. VGen, metinden, görüntülerden, istenen hareketlerden, konulardan ve geri bildirim sinyallerinden yüksek kaliteli videolar oluşturabilir. Depo, görüntüler ve videolar kullanılarak görselleştirme, örnekleme, eğitim, çıkarım ve ortak eğitim için araçlar içerir. Son güncellemeler arasında VideoLCM, I2VGen-XL ve DreamVideo yöntemi yer almaktadır.
VGen, genişletilebilirlik, performans ve eksiksizlik açısından mükemmeldir. Kurulum, bir Python ortamı ve gerekli kütüphaneleri kurmayı içerir. Kullanıcılar, metinden videoya modeller eğitebilir ve yüksek çözünürlüklü video üretimi için I2VGen-XL çalıştırabilir. Deney ve optimizasyonu kolaylaştırmak için demo veri kümeleri ve önceden eğitilmiş modeller mevcuttur. Kod tabanı, video sentez görevlerinde kolay yönetim ve yüksek verimlilik sağlar.
Temel Özellikler
- Açık kaynaklı kod tabanı
- Yüksek kaliteli sentez
- Hareket kontrol edilebilirliği
- Metinden videoya üretim
- Görüntüden videoya dönüştürme
- Genişletilebilir çerçeve
- Önceden eğitilmiş modeller
- Kapsamlı araçlar
Sıcak atış XL
Natural Synthetics Inc. tarafından geliştirilen bir AI metinden GIF'e dönüştürme modeli olan Hotshot-XL, Stable Diffusion XL ile kusursuz bir şekilde çalışır. Herhangi bir ince ayarlı SDXL modeli kullanılarak GIF oluşturulmasını sağlar ve ek ince ayar yapmadan kişiselleştirilmiş GIF'lerin oluşturulmasını basitleştirir. Bu model, çeşitli en boy oranlarında saniyede 8 kare hızında 1 saniyelik GIF'ler oluşturmada mükemmeldir. Gelişmiş performans için önceden eğitilmiş metin kodlayıcılarla (OpenCLIP-ViT/G ve CLIP-ViT/L) Latent Diffusion'ı kullanır.
Kullanıcılar, özelleştirilmiş düzenler için SDXL ControlNet kullanarak GIF kompozisyonlarını değiştirebilir. Çok yönlü GIF oluşturma yeteneğine sahip olsa da Hotshot-XL, fotogerçekçilik ve belirli kompozisyonları işleme gibi karmaşık görevlerle ilgili zorluklarla karşı karşıyadır. Modelin uygulanması, mevcut iş akışlarına sorunsuz bir şekilde entegre olmayı hedefler ve CreativeML Open RAIL++-M Lisansı altında GitHub'da keşfedilmeye açıktır.
Temel Özellikler
- Metinden GIF oluşturma
- SDXL ile çalışır
- 1 saniyelik GIF'ler üretir
- Çeşitli en boy oranlarını destekler
- Gizli Difüzyonu Kullanır
- Önceden eğitilmiş metin kodlayıcıları
- ControlNet ile özelleştirilebilir
- GitHub'da mevcut
Metinden Videoya AI Modellerinin Gelecekteki Yetenekleri
Hugging Face gibi platformlar, metni yüksek kaliteli, dinamik video içeriğine dönüştürebilen gelişmiş modeller geliştirmede öncülük ediyor. Bu bizi, metinden videoya AI modellerinin gelecekteki yeteneklerinin gerçekten heyecan verici olduğu varsayımına götürüyor.
Bu modeller, içerik oluşturmayı devrim niteliğinde değiştirecek, daha hızlı, daha verimli ve her zamankinden daha erişilebilir hale getirecek. Kullanıcılar, yalnızca bir metin istemi girerek, fikirlerini hayata geçiren ilgi çekici, özelleştirilmiş videolar üretebilecekler.
Potansiyel uygulamalar çok geniştir - pazarlama ve reklamcılıktan eğitim ve eğlenceye kadar. Tek bir tıklamayla profesyonel düzeyde açıklayıcı videolar veya animasyonlu hikayeler oluşturabildiğinizi hayal edin. İşletmeler ve yaratıcılar için zaman ve maliyet tasarrufları önemli olacaktır.
Ayrıca, bu metinden videoya modeller gerçekçilik, tutarlılık ve esneklik açısından gelişmeye devam ettikçe, çıktının kalitesi insan yapımı videodan giderek ayırt edilemez hale gelecektir. Video üretiminin bu demokratikleşmesi, daha fazla insanın hikayelerini ve fikirlerini dünyayla paylaşmasına olanak tanıyacaktır.
İçerik oluşturmanın geleceği şüphesiz metinden videoya dönüştürmedir ve Hugging Face bu dönüştürücü teknolojinin ön saflarında yer almaktadır. Bu modeller mümkün olanın sınırlarını zorlarken hayrete düşmeye hazır olun.
Özetleme
Sonuç olarak, Huggingface metinden videoya görevler için çeşitli modeller sunar ve her biri metinsel açıklamalardan dinamik görsel içerik üretmede benzersiz güçler getirir. İster hassasiyeti, ister yaratıcılığı veya ölçeklenebilirliği önceliklendirin, bu modeller çeşitli uygulamalar için sağlam çözümler sunar ve yapay zeka destekli video sentezinde ilerlemeler vaat eder.









