
Hugging Face เป็นขุมทองสำหรับทุกคนในการประมวลผลภาษาธรรมชาติ อัดแน่นไปด้วยโมเดลภาษาที่ผ่านการฝึกอบรมมาแล้วมากมาย ซึ่งใช้งานง่ายสุดๆ ในแอปพลิเคชันต่างๆ เมื่อพูดถึง Large Language Models (LLM) Hugging Face คือตัวเลือกอันดับต้นๆ ในงานชิ้นนี้ เราจะเจาะลึก LLM 10 อันดับแรกใน Hugging Face ซึ่งแต่ละรายการมีบทบาทสำคัญในการพัฒนาวิธีที่เราเข้าใจและสร้างภาษา

มาเริ่มกันเลย!
โมเดลภาษาขนาดใหญ่คืออะไร?
โมเดลภาษาขนาดใหญ่ (LLM) เป็นปัญญาประดิษฐ์ขั้นสูงที่ออกแบบมาเพื่อทำความเข้าใจและสร้างภาษาของมนุษย์ พวกมันถูกสร้างขึ้นโดยใช้เทคนิคการเรียนรู้เชิงลึก โดยเฉพาะโครงข่ายประสาทเทียมชนิดหนึ่งที่เรียกว่าหม้อแปลงไฟฟ้า
ต่อไปนี้คือรายละเอียดเพื่อให้ชัดเจน:
- การฝึกอบรมเกี่ยวกับข้อมูลขนาดใหญ่ : LLM ได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูลขนาดใหญ่ที่ประกอบด้วยหนังสือ บทความ เว็บไซต์ และอื่นๆ การฝึกอบรมที่ครอบคลุมนี้ช่วยให้พวกเขาเรียนรู้ความแตกต่างของภาษา รวมถึงไวยากรณ์ บริบท และแม้แต่การใช้เหตุผลในระดับหนึ่ง
- Transformers : สถาปัตยกรรมเบื้องหลัง LLM ส่วนใหญ่เรียกว่าหม้อแปลงไฟฟ้า โมเดลนี้ใช้กลไกความสนใจเพื่อชั่งน้ำหนักความสำคัญของคำต่างๆ ในประโยค ทำให้เข้าใจบริบทได้ดีกว่าโมเดลก่อนๆ
- งานที่พวกเขาปฏิบัติ : เมื่อได้รับการฝึกอบรมแล้ว LLM จะสามารถทำงานด้านภาษาต่างๆ ได้ ซึ่งรวมถึงการตอบคำถาม การสรุปข้อความ การแปลภาษา การสร้างงานเขียนเชิงสร้างสรรค์ และการเขียนโค้ด
- โมเดลยอดนิยม : LLM ที่รู้จักกันดี ได้แก่ GPT-3, BERT และ T5 โมเดลที่ได้รับการฝึกอบรมล่วงหน้าเหล่านี้สามารถปรับแต่งอย่างละเอียดสำหรับงานเฉพาะได้ ทำให้เป็นเครื่องมืออเนกประสงค์สำหรับนักพัฒนาและนักวิจัย
- แอปพลิเคชัน : LLM ใช้ในแชทบอท ผู้ช่วยเสมือน การสร้างเนื้อหาอัตโนมัติ และอื่นๆ อีกมากมาย ช่วยปรับปรุงการโต้ตอบของผู้ใช้กับเทคโนโลยีโดยทำให้เครื่องจักรเข้าใจและตอบสนองต่อภาษามนุษย์ได้อย่างเป็นธรรมชาติมากขึ้น
โดยพื้นฐานแล้ว โมเดลภาษาขนาดใหญ่เปรียบเสมือนสมองที่อัดแน่นไปด้วยพลังของคอมพิวเตอร์ ทำให้พวกมันสามารถจัดการและสร้างภาษาของมนุษย์ได้อย่างแม่นยำและมีความสามารถรอบด้านอย่างน่าประทับใจ
กอดเฟซ & LLM
Hugging Face คือบริษัทและเป็นแพลตฟอร์มที่กลายเป็นศูนย์กลางสำหรับการประมวลผลภาษาธรรมชาติ (NLP) และการเรียนรู้ของเครื่อง โดยจัดเตรียมเครื่องมือ ไลบรารี และทรัพยากรเพื่อช่วยให้นักพัฒนาและนักวิจัยสามารถสร้างและใช้โมเดลการเรียนรู้ของเครื่องได้ง่ายขึ้น โดยเฉพาะที่เกี่ยวข้องกับความเข้าใจและการสร้างภาษา
Hugging Face เป็นที่รู้จักจากไลบรารีโอเพ่นซอร์ส โดยเฉพาะ Transformers ซึ่งช่วยให้เข้าถึงโมเดลภาษาที่ผ่านการฝึกอบรมมาแล้วมากมายได้อย่างง่ายดาย
Hugging Face โฮสต์ LLM ที่ล้ำสมัยมากมาย เช่น GPT-3, BERT และ T5 โมเดลเหล่านี้ได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับชุดข้อมูลขนาดใหญ่ และพร้อมที่จะใช้กับแอปพลิเคชันต่างๆ
แพลตฟอร์มดังกล่าวมอบ API และเครื่องมือง่ายๆ สำหรับการรวมโมเดลเหล่านี้เข้ากับแอปพลิเคชันโดยไม่ต้องอาศัยความเชี่ยวชาญเชิงลึกในการเรียนรู้ของเครื่อง
การใช้เครื่องมือของ Hugging Face ทำให้คุณสามารถปรับแต่ง LLM ที่ได้รับการฝึกอบรมล่วงหน้าเหล่านี้จากข้อมูลของคุณเองได้ ช่วยให้คุณสามารถปรับให้เข้ากับงานหรือโดเมนเฉพาะได้
นักวิจัยและนักพัฒนาสามารถแบ่งปันแบบจำลองและการปรับปรุงของตนบนแพลตฟอร์ม Hugging Face ซึ่งจะช่วยเร่งให้เกิดนวัตกรรมและการประยุกต์ใช้ใน NLP
โมเดล LLM 5 อันดับแรกบน Huggingface ที่คุณควรใช้
เรามาสำรวจโมเดล LLM ชั้นนำบางส่วนบน Hugging Face ที่เก่งในการเล่าเรื่องและเหนือกว่า GPT กัน
มิสทรัล-7B-v0.1
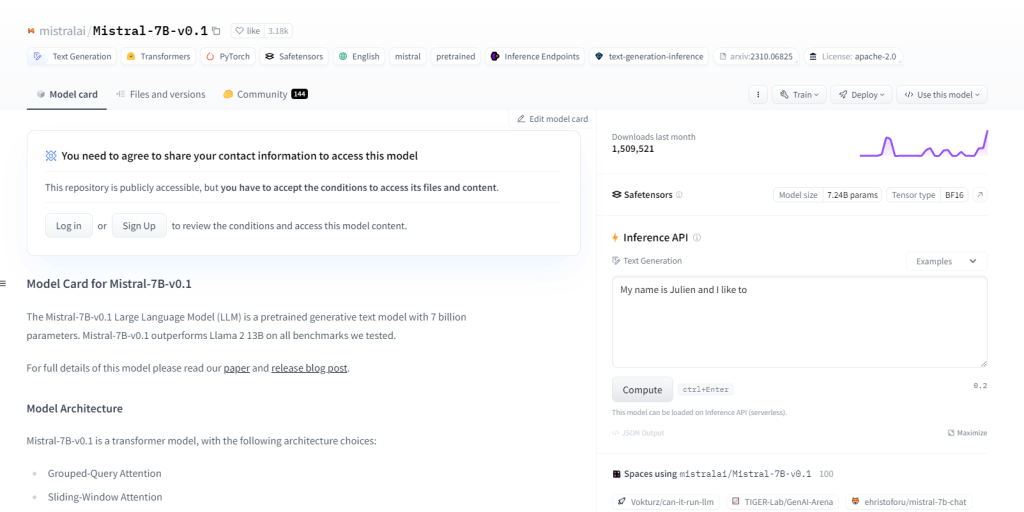
Mistral-7B-v0.1 ซึ่งเป็นโมเดลภาษาขนาดใหญ่ (LLM) ที่มีพารามิเตอร์ถึง 7 พันล้านพารามิเตอร์ มีประสิทธิภาพเหนือกว่าเกณฑ์มาตรฐานอย่าง Llama 2 13B ทั่วทั้งโดเมน ใช้สถาปัตยกรรมหม้อแปลงไฟฟ้าพร้อมกลไกความสนใจเฉพาะและโทเค็น BPE แบบ Byte-fallback มีความเป็นเลิศในการสร้างข้อความ ความเข้าใจภาษาธรรมชาติ การแปลภาษา และทำหน้าที่เป็นต้นแบบสำหรับการวิจัยและพัฒนาในโครงการ NLP
คุณสมบัติที่สำคัญ
- 7 พันล้านพารามิเตอร์
- เหนือกว่าเกณฑ์มาตรฐานเช่น Llama 213B
- สถาปัตยกรรมหม้อแปลงไฟฟ้า
- โทเค็น BPE
- การพัฒนาโครงการ NLP
- ความเข้าใจภาษาธรรมชาติ
- การแปลภาษา
- ความสนใจแบบสอบถามแบบกลุ่ม
สตาร์ลิ่ง-LM-11B-อัลฟา
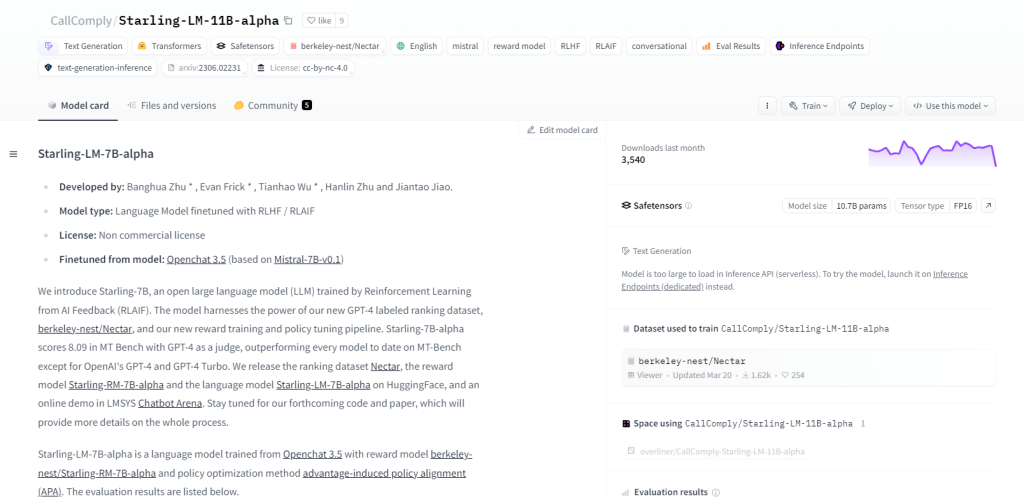
Starling-LM-11B-alpha ซึ่งเป็นโมเดลภาษาขนาดใหญ่ (LLM) ที่มีพารามิเตอร์ 11 พันล้านพารามิเตอร์ เกิดขึ้นจาก NurtureAI โดยใช้ประโยชน์จากโมเดล OpenChat 3.5 เป็นฐาน การปรับแต่งอย่างละเอียดทำได้ผ่านการเรียนรู้แบบเสริมแรงจาก AI Feedback (RLAIF) ซึ่งได้รับคำแนะนำจากการจัดอันดับที่มนุษย์กำหนด โมเดลนี้สัญญาว่าจะปรับเปลี่ยนปฏิสัมพันธ์ระหว่างมนุษย์กับเครื่องจักรด้วยเฟรมเวิร์กโอเพ่นซอร์สและแอปพลิเคชันที่หลากหลาย รวมถึงงาน NLP การวิจัยการเรียนรู้ของเครื่องจักร การศึกษา และการสร้างเนื้อหาที่สร้างสรรค์
คุณสมบัติที่สำคัญ
- 11 พันล้านพารามิเตอร์
- พัฒนาโดย NurtureAI
- อิงตามโมเดล OpenChat 3.5
- ปรับแต่งอย่างละเอียดผ่าน RLAIF
- การจัดอันดับการฝึกอบรมที่ติดป้ายกำกับโดยมนุษย์
- ธรรมชาติของโอเพ่นซอร์ส
- ความสามารถที่หลากหลาย
- ใช้สำหรับการวิจัย การศึกษา และการสร้างเนื้อหาที่สร้างสรรค์
ยี่-34B-ลามะ
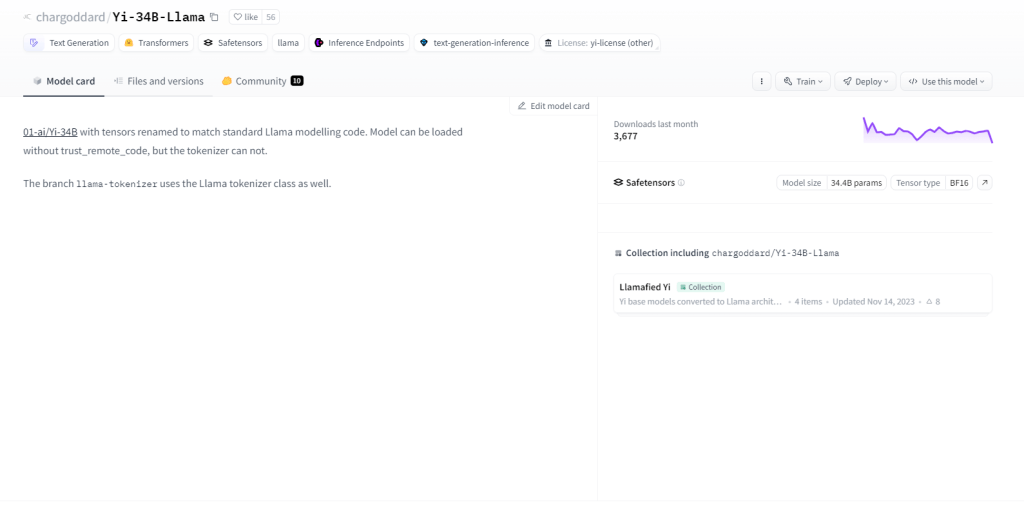
Yi-34B-Llama ซึ่งมีพารามิเตอร์ถึง 34 พันล้านพารามิเตอร์ แสดงให้เห็นถึงความสามารถในการเรียนรู้ที่เหนือกว่า เป็นเลิศในการประมวลผลหลายรูปแบบ การจัดการข้อความ โค้ด และรูปภาพอย่างมีประสิทธิภาพ การนำการเรียนรู้แบบ Zero-shot มาปรับใช้จะปรับให้เข้ากับงานใหม่ๆ ได้อย่างราบรื่น ลักษณะการเก็บสถานะทำให้สามารถจดจำการโต้ตอบในอดีต ช่วยเพิ่มการมีส่วนร่วมของผู้ใช้ กรณีการใช้งานได้แก่ การสร้างข้อความ การแปลด้วยเครื่อง การตอบคำถาม บทสนทนา การสร้างโค้ด และคำบรรยายภาพ
คุณสมบัติที่สำคัญ
- 34 พันล้านพารามิเตอร์
- การประมวลผลหลายรูปแบบ
- ความสามารถในการเรียนรู้แบบ Zero-shot
- ธรรมชาติของรัฐ
- การสร้างข้อความ
- การแปลด้วยเครื่อง
- ตอบคำถาม
- คำบรรยายภาพ
ฐาน DeepSeek LLM 67B
DeepSeek LLM 67B Base ซึ่งเป็นโมเดลภาษาขนาดใหญ่ (LLM) พารามิเตอร์มูลค่า 6.7 หมื่นล้านพารามิเตอร์ โดดเด่นในด้านการใช้เหตุผล การเขียนโค้ด และงานคณิตศาสตร์ ด้วยคะแนนที่โดดเด่นเหนือ GPT-3.5 และ Llama2 70B Base ทำให้เป็นเลิศในการทำความเข้าใจโค้ดและสร้าง และแสดงให้เห็นถึงทักษะทางคณิตศาสตร์ที่น่าทึ่ง ลักษณะโอเพ่นซอร์สภายใต้ใบอนุญาต MIT ช่วยให้สามารถสำรวจได้ฟรี กรณีการใช้งานครอบคลุมการเขียนโปรแกรม การศึกษา การวิจัย การสร้างเนื้อหา การแปล และการตอบคำถาม
คุณสมบัติที่สำคัญ
- พารามิเตอร์ 67 พันล้าน
- ประสิทธิภาพที่โดดเด่นในด้านการใช้เหตุผล การเขียนโค้ด และคณิตศาสตร์
- HumanEval Pass@1 คะแนน 73.78
- ความเข้าใจและสร้างโค้ดที่โดดเด่น
- คะแนนสูงสุดบน GSM8K 0-shot (84.1)
- ความสามารถด้านภาษาเหนือกว่า GPT-3.5
- โอเพ่นซอร์สภายใต้ใบอนุญาต MIT
- ความสามารถในการเล่าเรื่องและการสร้างเนื้อหาที่ยอดเยี่ยม
Skote - เทมเพลตผู้ดูแลระบบและแดชบอร์ด Svelte
Marcoroni-7B-v3 เป็นโมเดลสร้างหลายภาษาที่ทรงพลังด้วยพารามิเตอร์มูลค่า 7 พันล้านพารามิเตอร์ สามารถทำงานได้หลากหลาย รวมถึงการสร้างข้อความ การแปลภาษา การสร้างเนื้อหาเชิงสร้างสรรค์ และการตอบคำถาม เป็นเลิศในการประมวลผลทั้งข้อความและโค้ด โดยใช้ประโยชน์จากการเรียนรู้แบบ Zero-Shot เพื่อการปฏิบัติงานที่รวดเร็วโดยไม่ต้องมีการฝึกอบรมล่วงหน้า โอเพ่นซอร์สและภายใต้ใบอนุญาตที่อนุญาต Marcoroni-7B-v3 อำนวยความสะดวกในการใช้งานและการทดลองในวงกว้าง
คุณสมบัติที่สำคัญ
- การสร้างข้อความสำหรับบทกวี โค้ด สคริปต์ อีเมล และอื่นๆ
- การแปลด้วยเครื่องที่มีความแม่นยำสูง
- การสร้างแชทบอทที่น่าสนใจพร้อมการสนทนาที่เป็นธรรมชาติ
- การสร้างโค้ดจากคำอธิบายภาษาธรรมชาติ
- ความสามารถในการตอบคำถามที่ครอบคลุม
- การสรุปข้อความที่ยาวให้เป็นบทสรุปที่กระชับ
- การถอดความที่มีประสิทธิภาพโดยยังคงรักษาความหมายดั้งเดิม
- การวิเคราะห์ความรู้สึกสำหรับเนื้อหาที่เป็นข้อความ
ห่อ
คอลเลกชันโมเดลภาษาขนาดใหญ่ของ Hugging Face เป็นตัวเปลี่ยนเกมสำหรับนักพัฒนา นักวิจัย และผู้ที่ชื่นชอบ โมเดลเหล่านี้มีบทบาทสำคัญในการผลักดันขอบเขตของการทำความเข้าใจและการสร้างภาษาธรรมชาติ ต้องขอบคุณสถาปัตยกรรมและความสามารถที่หลากหลาย เมื่อเทคโนโลยีพัฒนาไป การใช้งานและผลกระทบของโมเดลเหล่านี้ก็จะไม่มีที่สิ้นสุด การเดินทางของการสำรวจและสร้างสรรค์สิ่งใหม่ๆ ด้วยโมเดลภาษาขนาดใหญ่กำลังดำเนินไปอย่างต่อเนื่อง และมีการพัฒนาที่น่าตื่นเต้นรออยู่ข้างหน้า







