
การเพิ่มขึ้นของเทคโนโลยีการแปลงข้อความเป็นวิดีโอที่ขับเคลื่อนด้วย AI กำลังปฏิวัติวิธีการสร้างและบริโภคเนื้อหาของเรา โมเดล Hugging Face อันทรงพลังอยู่แนวหน้าของการเปลี่ยนแปลงครั้งนี้ ซึ่งกำลังกลายเป็นเครื่องมือที่ผู้สร้างเนื้อหาและธุรกิจต่าง ๆ เลือกใช้กันอย่างรวดเร็ว

โมเดลภาษาที่ล้ำสมัยเหล่านี้ซึ่งฝึกฝนจากข้อมูลจำนวนมาก มีความสามารถที่โดดเด่นในการแปลข้อความที่เขียนเป็นเรื่องราวทางภาพที่น่าสนใจ ด้วยการใช้ประโยชน์จากความก้าวหน้าล่าสุดในการประมวลผลภาษาธรรมชาติและ AI เชิงสร้างสรรค์ โมเดล Hugging Face สามารถเปลี่ยนคำพูดของคุณให้กลายเป็นวิดีโอคุณภาพสูงที่ดึงดูดผู้ชมได้อย่างง่ายดาย
ทำความเข้าใจเทคโนโลยีการแปลงข้อความเป็นวิดีโอ
โมเดลข้อความเป็นวิดีโอจะแปลงคำอธิบายที่เขียนเป็นภาพเคลื่อนไหว โมเดลเหล่านี้เข้าใจข้อความและแปลงเป็นลำดับเฟรมที่แสดงฉากหรือการกระทำที่บรรยาย กระบวนการนี้เกี่ยวข้องกับหลายขั้นตอน รวมถึงการวิเคราะห์ข้อความ การสร้างเนื้อหาวิดีโอ และการเรียงลำดับเฟรม แต่ละขั้นตอนต้องใช้อัลกอริทึมที่ซับซ้อนเพื่อให้แน่ใจว่าวิดีโอเอาต์พุตแสดงข้อความอินพุตได้อย่างถูกต้อง
การเดินทางของเทคโนโลยีการแปลงข้อความเป็นวิดีโอเริ่มต้นด้วยคำอธิบายข้อความธรรมดาที่สร้างภาพเคลื่อนไหวพื้นฐาน โมเดลในช่วงแรกเน้นที่การสร้างภาพนิ่ง แต่ความก้าวหน้าใน AI และการเรียนรู้ของเครื่องจักรทำให้สามารถพัฒนาการสร้างวิดีโอแบบไดนามิกได้ ในช่วงหลายปีที่ผ่านมา นักวิจัยได้ผสานรวมเครือข่ายประสาทที่ซับซ้อน ส่งผลให้คุณภาพและความสมจริงของวิดีโอดีขึ้นอย่างมาก ความก้าวหน้าเหล่านี้ได้เปิดโอกาสใหม่ๆ สำหรับการสร้างเนื้อหาเชิงสร้างสรรค์และแอปพลิเคชันต่างๆ ในอุตสาหกรรมต่างๆ
โมเดล AI แปลงข้อความเป็นวิดีโอที่ดีที่สุด 5 อันจาก Huggingface
เราขอแนะนำโมเดลแปลงข้อความเป็นวิดีโอด้วย AI ที่ดีที่สุด 5 อันดับจาก huggingface โมเดลเหล่านี้ได้รับความนิยมอย่างมากเนื่องจากฟังก์ชันการทำงานที่โดดเด่นและมียอดดาวน์โหลดมากที่สุด
โมเดลสโคป - 1.7b
แบบจำลองการสังเคราะห์ข้อความเป็นวิดีโอจาก ModelScope ใช้กระบวนการกระจายหลายขั้นตอนเพื่อสร้างวิดีโอจากคำอธิบายข้อความ แบบจำลองขั้นสูงนี้รองรับเฉพาะอินพุตภาษาอังกฤษเท่านั้นและได้รับการออกแบบมาเพื่อวัตถุประสงค์ในการวิจัย ประกอบด้วยเครือข่ายย่อยสามเครือข่าย ได้แก่ การสกัดคุณลักษณะข้อความ การกระจายพื้นที่แฝงจากข้อความเป็นวิดีโอ และการแมปพื้นที่แฝงของวิดีโอเป็นพื้นที่ภาพ
ด้วยพารามิเตอร์ 1.7 พันล้านตัวและโครงสร้าง UNet3D ทำให้สามารถลดเสียงรบกวนแบบเกาส์เซียนได้อย่างต่อเนื่องเพื่อสร้างวิดีโอ โมเดลนี้เหมาะสำหรับการใช้งานต่างๆ เช่น การสร้างวิดีโอจากข้อความภาษาอังกฤษแบบสุ่ม อย่างไรก็ตาม โมเดลนี้มีข้อจำกัด เช่น ความลำเอียงจากข้อมูลการฝึกอบรม และไม่สามารถสร้างวิดีโอคุณภาพสูงระดับฟิล์มหรือข้อความธรรมดาได้ ผู้ใช้ต้องหลีกเลี่ยงการสร้างเนื้อหาที่เป็นอันตรายหรือเป็นเท็จ โมเดลนี้ได้รับการฝึกอบรมบนชุดข้อมูลสาธารณะ รวมถึง LAION5B, ImageNet และ Webvid
คุณสมบัติหลัก
- กระบวนการแพร่กระจายหลายขั้นตอน
- รองรับข้อความภาษาอังกฤษ
- 1.7 พันล้านพารามิเตอร์
- สถาปัตยกรรม UNet3D
- วิธีการลดเสียงรบกวนแบบวนซ้ำ
- จุดมุ่งหมายการวิจัย
- การฝึกอบรมชุดข้อมูลสาธารณะ
- การสร้างข้อความตามต้องการ
AnimateDiff-สายฟ้า
AnimateDiff-Lightning คือโมเดลการสร้างข้อความเป็นวิดีโอที่ล้ำสมัยซึ่งให้ความเร็วที่ปรับปรุงขึ้นจาก AnimateDiff ดั้งเดิม โดยสร้างวิดีโอได้เร็วขึ้นกว่า 10 เท่า พัฒนาจาก AnimateDiff SD1.5 v2 โมเดลนี้มีให้เลือกใช้ทั้งเวอร์ชัน 1 ขั้นตอน 2 ขั้นตอน 4 ขั้นตอน และ 8 ขั้นตอน โดยโมเดลขั้นสูงจะให้คุณภาพที่เหนือกว่า โมเดลนี้จะโดดเด่นเมื่อใช้กับโมเดลพื้นฐานที่มีสไตล์ เช่น epiCRealism และ Realistic Vision รวมถึงโมเดลอนิเมะและการ์ตูน เช่น ToonYou และ Mistoon Anime
ผู้ใช้สามารถได้รับผลลัพธ์ที่ดีที่สุดโดยการทดลองกับการตั้งค่าต่างๆ เช่น การใช้ Motion LoRA สำหรับการนำไปใช้งาน สามารถใช้โมเดลนี้ร่วมกับตัวกระจายสัญญาณและ ComfyUI ได้ โมเดลนี้รองรับการสร้างวิดีโอเป็นวิดีโอด้วย ControlNet เพื่อผลลัพธ์ที่ดีขึ้น สำหรับรายละเอียดเพิ่มเติมและการสาธิต ผู้ใช้ควรอ่านเอกสารวิจัย: AnimateDiff-Lightning: การกลั่นการแพร่กระจายแบบข้ามโมเดล
คุณสมบัติหลัก
- การสร้างวิดีโอที่รวดเร็วทันใจ
- กลั่นจาก AnimateDiff
- จุดตรวจหลายขั้นตอน
- คุณภาพการผลิตระดับสูง
- รองรับโมเดลที่ออกแบบมาอย่างมีสไตล์
- รองรับการเคลื่อนไหว LoRAs
- ตัวเลือกที่สมจริงและการ์ตูน
- การสร้างวิดีโอเป็นวิดีโอ
ซีโรสโคป V2
โมเดลวิดีโอ zeroscope_v2_567w ที่ใช้ Modelscope โดดเด่นในด้านการสร้างวิดีโอ 16:9 คุณภาพสูงโดยไม่มีลายน้ำ โดยฝึกจากคลิป 9,923 คลิปและเฟรมที่แท็กไว้ 29,769 เฟรมที่ความละเอียด 576x320 และ 24 เฟรมต่อวินาที จึงเหมาะอย่างยิ่งสำหรับการแสดงผลวิดีโอที่ราบรื่น โมเดลนี้ได้รับการออกแบบมาสำหรับการแสดงผลเบื้องต้นก่อนการอัปสเกลด้วย zeroscope_v2_XL โดยใช้ vid2vid ในส่วนขยาย 1111 text2video ซึ่งช่วยให้สามารถสำรวจได้อย่างมีประสิทธิภาพที่ความละเอียดต่ำกว่า
การอัปสเกลเป็น 1024x576 ช่วยให้ได้องค์ประกอบภาพที่เหนือกว่า โดยใช้ VRAM ขนาด 7.9GB สำหรับการเรนเดอร์ 30 เฟรม หากต้องการใช้งาน โปรดดาวน์โหลดและแทนที่ไฟล์ในไดเร็กทอรีที่เหมาะสม
หากต้องการผลลัพธ์ที่ดีที่สุด ให้ทำการอัปสเกลโดยใช้ zeroscope_v2_XL โดยมีค่าความแรงของการลดสัญญาณรบกวนระหว่าง 0.66 ถึง 0.85 ปัญหาที่ทราบ ได้แก่ เอาต์พุตที่ไม่เหมาะสมที่ความละเอียดต่ำกว่าหรือเฟรมที่น้อยกว่า สามารถผสานรวมโมเดลนี้ได้อย่างง่ายดายโดยใช้ตัวกระจายแสงพร้อมขั้นตอนการติดตั้งและการสร้างวิดีโอที่ง่ายดาย
คุณสมบัติหลัก
- เอาท์พุตแบบไม่มีลายน้ำ
- 16:9 คุณภาพสูง
- เอาต์พุตวิดีโอที่ราบรื่น
- ความละเอียด 576x320
- 24 เฟรมต่อวินาที
- การอัปสเกลที่มีประสิทธิภาพ
- การใช้งาน VRAM 7.9GB
- การบูรณาการที่ง่ายดาย
วีเจ็น
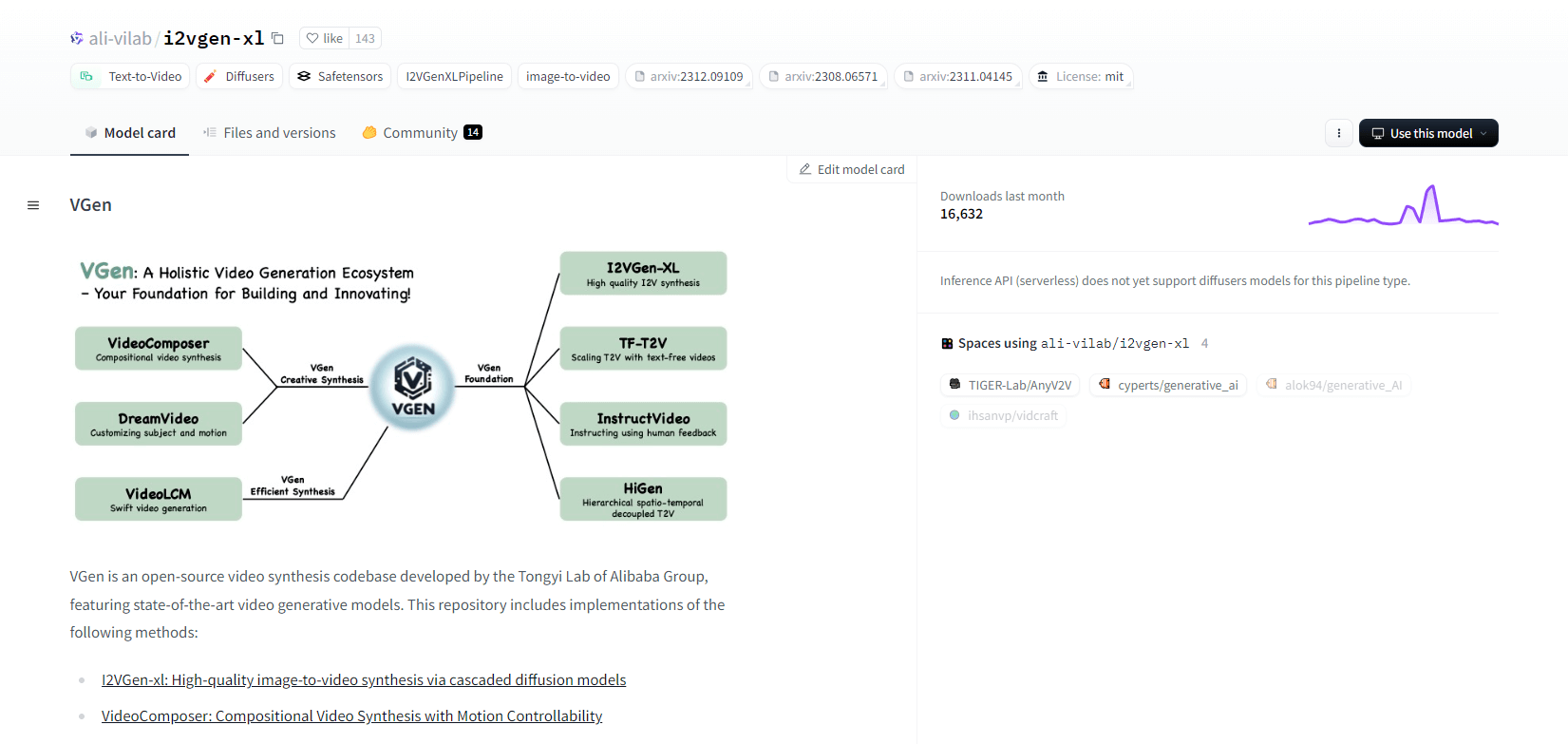
VGen ซึ่งเป็นฐานโค้ดการสังเคราะห์วิดีโอโอเพ่นซอร์สจาก Tongyi Lab ของ Alibaba นำเสนอโมเดลการสร้างวิดีโอขั้นสูง ซึ่งรวมถึงวิธีการต่างๆ เช่น I2VGen-xl สำหรับการสังเคราะห์ภาพเป็นวิดีโอคุณภาพสูง VideoComposer สำหรับการสังเคราะห์วิดีโอที่ควบคุมการเคลื่อนไหว และอื่นๆ อีกมากมาย VGen สามารถสร้างวิดีโอคุณภาพสูงจากข้อความ รูปภาพ การเคลื่อนไหวที่ต้องการ หัวข้อ และสัญญาณตอบรับ คลังข้อมูลนี้มีเครื่องมือสำหรับการสร้างภาพ การสุ่มตัวอย่าง การฝึกอบรม การอนุมาน และการฝึกอบรมร่วมกันโดยใช้รูปภาพและวิดีโอ การอัปเดตล่าสุดได้แก่ VideoLCM, I2VGen-XL และวิธี DreamVideo
VGen โดดเด่นในด้านความสามารถในการขยาย ประสิทธิภาพ และความสมบูรณ์ การติดตั้งเกี่ยวข้องกับการตั้งค่าสภาพแวดล้อม Python และไลบรารีที่จำเป็น ผู้ใช้สามารถฝึกโมเดลข้อความเป็นวิดีโอและเรียกใช้ I2VGen-XL สำหรับการสร้างวิดีโอความละเอียดสูง มีชุดข้อมูลสาธิตและโมเดลที่ผ่านการฝึกล่วงหน้าเพื่ออำนวยความสะดวกในการทดลองและการเพิ่มประสิทธิภาพ ฐานโค้ดช่วยให้จัดการได้ง่ายและมีประสิทธิภาพสูงในงานสังเคราะห์วิดีโอ
คุณสมบัติหลัก
- ฐานโค้ดโอเพ่นซอร์ส
- การสังเคราะห์คุณภาพสูง
- การควบคุมการเคลื่อนไหว
- การสร้างข้อความเป็นวิดีโอ
- การแปลงรูปภาพเป็นวิดีโอ
- กรอบงานที่สามารถขยายได้
- โมเดลที่ผ่านการฝึกอบรมล่วงหน้า
- เครื่องมือที่ครบครัน
ฮ็อตช็อต เอ็กซ์แอล
Hotshot-XL ซึ่งเป็นโมเดลการแปลงข้อความเป็น GIF ด้วย AI ที่พัฒนาโดย Natural Synthetics Inc. สามารถทำงานร่วมกับ Stable Diffusion XL ได้อย่างราบรื่น ช่วยให้สามารถสร้าง GIF ได้โดยใช้โมเดล SDXL ที่ปรับแต่งอย่างละเอียด ทำให้การสร้าง GIF ส่วนบุคคลเป็นเรื่องง่ายโดยไม่ต้องปรับแต่งเพิ่มเติม โมเดลนี้โดดเด่นในด้านการสร้าง GIF 1 วินาทีที่ 8 เฟรมต่อวินาทีในอัตราส่วนภาพต่างๆ โดยใช้ประโยชน์จาก Latent Diffusion กับตัวเข้ารหัสข้อความที่ผ่านการฝึกอบรมไว้ล่วงหน้า (OpenCLIP-ViT/G และ CLIP-ViT/L) เพื่อประสิทธิภาพที่เพิ่มขึ้น
ผู้ใช้สามารถปรับเปลี่ยนองค์ประกอบ GIF โดยใช้ SDXL ControlNet สำหรับเลย์เอาต์ที่กำหนดเองได้ แม้ว่าจะมีความสามารถในการสร้าง GIF ที่หลากหลาย แต่ Hotshot-XL ต้องเผชิญกับความท้าทายในด้านความสมจริงและงานที่ซับซ้อน เช่น การเรนเดอร์องค์ประกอบเฉพาะ การนำโมเดลไปใช้งานมีเป้าหมายเพื่อบูรณาการเข้ากับเวิร์กโฟลว์ที่มีอยู่ได้อย่างราบรื่น และพร้อมให้สำรวจบน GitHub ภายใต้ใบอนุญาต CreativeML Open RAIL++-M
คุณสมบัติหลัก
- การสร้างข้อความเป็น GIF
- ใช้งานได้กับ SDXL
- สร้าง GIF 1 วินาที
- รองรับอัตราส่วนภาพหลากหลาย
- ใช้การแพร่กระจายแฝง
- ตัวเข้ารหัสข้อความที่ผ่านการฝึกอบรมล่วงหน้า
- ปรับแต่งได้ด้วย ControlNet
- พร้อมใช้งานบน GitHub
ความสามารถในอนาคตของโมเดล AI แปลงข้อความเป็นวิดีโอ
แพลตฟอร์มเช่น Hugging Face เป็นผู้นำในการพัฒนาโมเดลขั้นสูงที่สามารถแปลงข้อความเป็นเนื้อหาวิดีโอแบบไดนามิกคุณภาพสูง ซึ่งทำให้เราตั้งสมมติฐานได้ว่าความสามารถในอนาคตของโมเดล AI แปลงข้อความเป็นวิดีโอนั้นน่าตื่นเต้นอย่างแท้จริง
โมเดลเหล่านี้พร้อมที่จะปฏิวัติการสร้างเนื้อหา ทำให้เร็วขึ้น มีประสิทธิภาพมากขึ้น และเข้าถึงได้ง่ายกว่าที่เคย เพียงแค่ป้อนข้อความ ผู้ใช้ก็สามารถสร้างวิดีโอที่น่าสนใจและปรับแต่งได้ ซึ่งจะทำให้ไอเดียของพวกเขากลายเป็นจริงได้
การประยุกต์ใช้งานมีมากมาย ไม่ว่าจะเป็นการตลาดและโฆษณา ไปจนถึงการศึกษาและความบันเทิง ลองนึกภาพว่าคุณสามารถสร้างวิดีโออธิบายระดับมืออาชีพหรือเรื่องราวแบบแอนิเมชันได้เพียงแค่คลิกปุ่มเดียว จะช่วยประหยัดเวลาและต้นทุนให้กับธุรกิจและผู้สร้างสรรค์ผลงานได้มาก
ยิ่งไปกว่านั้น เนื่องจากโมเดลการแปลงข้อความเป็นวิดีโอเหล่านี้ยังคงพัฒนาอย่างต่อเนื่องในแง่ของความสมจริง ความสอดคล้อง และความยืดหยุ่น คุณภาพของผลลัพธ์จึงแทบไม่สามารถแยกแยะได้จากวิดีโอที่มนุษย์สร้างขึ้น การทำให้การผลิตวิดีโอเป็นประชาธิปไตยจะทำให้ผู้คนจำนวนมากขึ้นสามารถแบ่งปันเรื่องราวและแนวคิดของตนกับคนทั่วโลกได้
อนาคตของการสร้างเนื้อหาคือการแปลงข้อความเป็นวิดีโออย่างไม่ต้องสงสัย และ Hugging Face ถือเป็นแนวหน้าของเทคโนโลยีที่เปลี่ยนแปลงโลกนี้ เตรียมพบกับความตื่นตาตื่นใจเมื่อโมเดลเหล่านี้ขยายขอบเขตของสิ่งที่เป็นไปได้
การห่อหุ้ม
โดยสรุป Huggingface นำเสนอโมเดลที่หลากหลายสำหรับงานแปลงข้อความเป็นวิดีโอ โดยแต่ละโมเดลมีจุดแข็งเฉพาะตัวในการสร้างเนื้อหาวิดีโอแบบไดนามิกจากคำอธิบายข้อความ ไม่ว่าคุณจะให้ความสำคัญกับความแม่นยำ ความคิดสร้างสรรค์ หรือความสามารถในการปรับขนาด โมเดลเหล่านี้ก็มอบโซลูชันที่แข็งแกร่งสำหรับแอปพลิเคชันต่างๆ ซึ่งสัญญาว่าจะมีความก้าวหน้าในการสังเคราะห์วิดีโอที่ขับเคลื่อนด้วย AI







