
Vzpon tehnologije pretvorbe besedila v video, ki jo poganja umetna inteligenca, spreminja način ustvarjanja in uživanja vsebine. V ospredju te preobrazbe so zmogljivi modeli Hugging Face, ki hitro postajajo priljubljena orodja za ustvarjalce vsebin in podjetja.

Ti najsodobnejši jezikovni modeli, usposobljeni na obsežni množici podatkov, imajo izjemno sposobnost prevajanja pisnega besedila v očarljive vizualne pripovedi. Z izkoriščanjem najnovejših dosežkov pri obdelavi naravnega jezika in generativne umetne inteligence lahko modeli Hugging Face vaše besede brez truda spremenijo v privlačne, visokokakovostne videoposnetke, ki očarajo vaše občinstvo.
Razumevanje tehnologije pretvorbe besedila v video
Modeli besedila v video pretvorijo pisne opise v gibljive slike. Ti modeli razumejo besedilo in ga pretvorijo v zaporedje okvirjev, ki prikazujejo opisani prizor ali dejanje. Ta postopek vključuje več korakov, vključno z analizo besedila, ustvarjanjem vizualne vsebine in zaporedjem okvirjev. Vsak korak zahteva zapletene algoritme za zagotovitev, da izhodni video natančno predstavlja vhodno besedilo.
Potovanje tehnologije besedila v video se je začelo s preprostimi besedilnimi opisi, ki so ustvarili osnovne animacije. Zgodnji modeli so bili osredotočeni na ustvarjanje statičnih slik, vendar sta napredek v AI in strojnem učenju omogočila razvoj dinamične generacije videa. Z leti so raziskovalci integrirali sofisticirane nevronske mreže, kar je privedlo do bistvenih izboljšav kakovosti in realizma videa. Ta napredek je odprl nove možnosti za ustvarjalno ustvarjanje vsebine in različne aplikacije v panogah.
5 najboljših modelov umetne inteligence iz besedila v video od Huggingface
Tukaj imamo 5 najboljših modelov umetne inteligence za pretvorbo besedila v video iz huggingface. Ti modeli so zelo priljubljeni zaradi svoje posebne funkcionalnosti in imajo največje število prenosov.
ModelScope - 1.7b
Model sinteze besedila v video iz ModelScope uporablja večstopenjski postopek razširjanja za ustvarjanje videoposnetkov iz besedilnih opisov. Ta napredni model podpira samo angleški vnos in je zasnovan za raziskovalne namene. Sestavljen je iz treh podomrežij: ekstrakcija besedilnih funkcij, razširjanje latentnega prostora besedila v video in preslikava latentnega prostora videa v vizualni prostor.
Z 1,7 milijarde parametrov in strukturo UNet3D iterativno odpravlja Gaussov šum za ustvarjanje videoposnetkov. Ta model je primeren za različne aplikacije, kot je ustvarjanje video posnetkov iz poljubnega angleškega besedila. Vendar pa ima omejitve, kot so pristranskosti podatkov o usposabljanju in nezmožnost ustvarjanja visokokakovostnih videoposnetkov na ravni filma ali čistega besedila. Uporabniki se morajo izogibati ustvarjanju škodljive ali lažne vsebine. Model je bil usposobljen na javnih naborih podatkov, vključno z LAION5B, ImageNet in Webvid.
Ključne značilnosti
- Večstopenjski difuzijski proces
- Podpora za angleško besedilo
- 1,7 milijarde parametrov
- Arhitektura UNet3D
- Iterativna metoda odstranjevanja šumov
- Fokus raziskovalnega namena
- Usposabljanje za javne zbirke podatkov
- Poljubno generiranje besedila
AnimateDiff-Lightning
AnimateDiff-Lightning je vrhunski model za generiranje besedila v video, ki ponuja izboljšave hitrosti v primerjavi z izvirnim AnimateDiffom in ustvarja več kot desetkrat hitrejše videoposnetke. Ta model, razvit iz AnimateDiff SD1.5 v2, je na voljo v 1-stopenjski, 2-stopenjski, 4-stopenjski in 8-stopenjski različici, pri čemer modeli z višjimi stopnjami ponujajo vrhunsko kakovost. Odličen je pri uporabi s stiliziranimi osnovnimi modeli, kot sta epiCRealism in Realistic Vision, ter modeli animejev in risank, kot sta ToonYou in Mistoon Anime.
Uporabniki lahko dosežejo optimalne rezultate z eksperimentiranjem z različnimi nastavitvami, na primer z uporabo Motion LoRA. Za izvedbo se lahko model uporablja z difuzorji in ComfyUI. Podpira generiranje videa v video s ControlNet za izboljšan izhod. Za več podrobnosti in predstavitev uporabnikom priporočamo, da se obrnejo na raziskovalni dokument: AnimateDiff-Lightning: Cross-Model Diffusion Destillation
Ključne značilnosti
- Svetlobno hitro ustvarjanje videa
- Destilirano iz AnimateDiff
- Kontrolne točke v več korakih
- Kakovost visoke generacije
- Podpira stilizirane modele
- Podpora za Motion LoRAs
- Realistične in risane možnosti
- Generiranje videa v video
Zeroscope V2
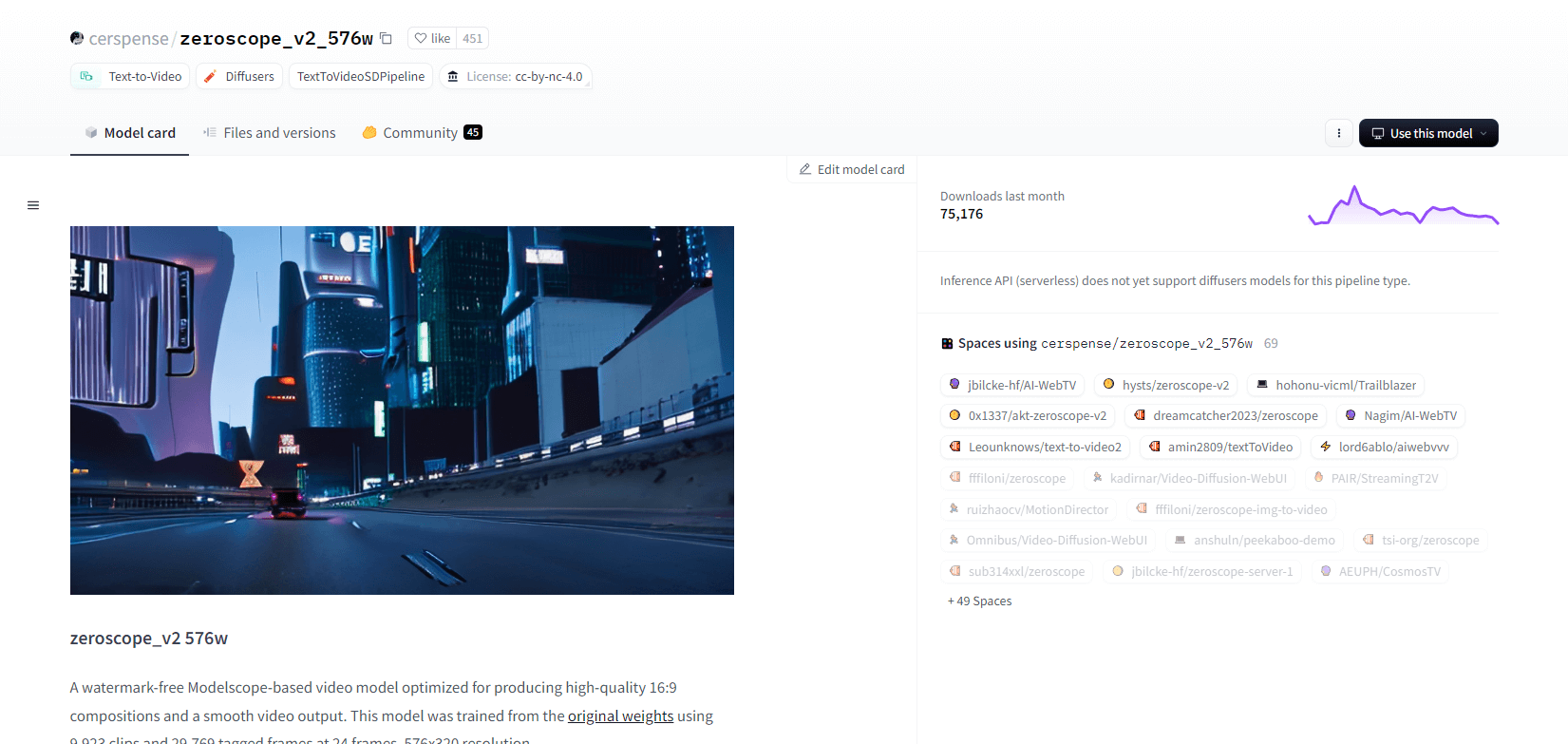
Video model zeroscope_v2_567w, ki temelji na Modelscopeu, je odličen pri ustvarjanju visokokakovostnih videoposnetkov 16:9 brez vodnih žigov. Naučen na 9.923 posnetkih in 29.769 označenih sličicah pri ločljivosti 576 x 320 in 24 sličicah na sekundo je idealen za tekoč video izhod. Ta model je zasnovan za začetno upodabljanje pred nadgradnjo z zeroscope_v2_XL z uporabo vid2vid v razširitvi 1111 text2video, kar omogoča učinkovito raziskovanje pri nižjih ločljivostih.
Povečanje ločljivosti na 1024x576 zagotavlja vrhunske kompozicije. Za upodabljanje 30 sličic uporablja 7,9 GB VRAM-a. Za uporabo prenesite in zamenjajte datoteke v ustreznem imeniku.
Za najboljše rezultate povečajte z uporabo zeroscope_v2_XL z močjo odpravljanja hrupa med 0,66 in 0,85. Znane težave vključujejo neoptimalen izpis pri nižjih ločljivostih ali manj sličic. Model je mogoče preprosto integrirati z uporabo difuzorjev s preprosto namestitvijo in koraki ustvarjanja videa.
Ključne značilnosti
- Izpis brez vodnega žiga
- Visoka kakovost 16:9
- Gladek video izhod
- Ločljivost 576x320
- 24 sličic na sekundo
- Učinkovito povečanje velikosti
- Poraba 7,9 GB VRAM
- Enostavna integracija
VGen
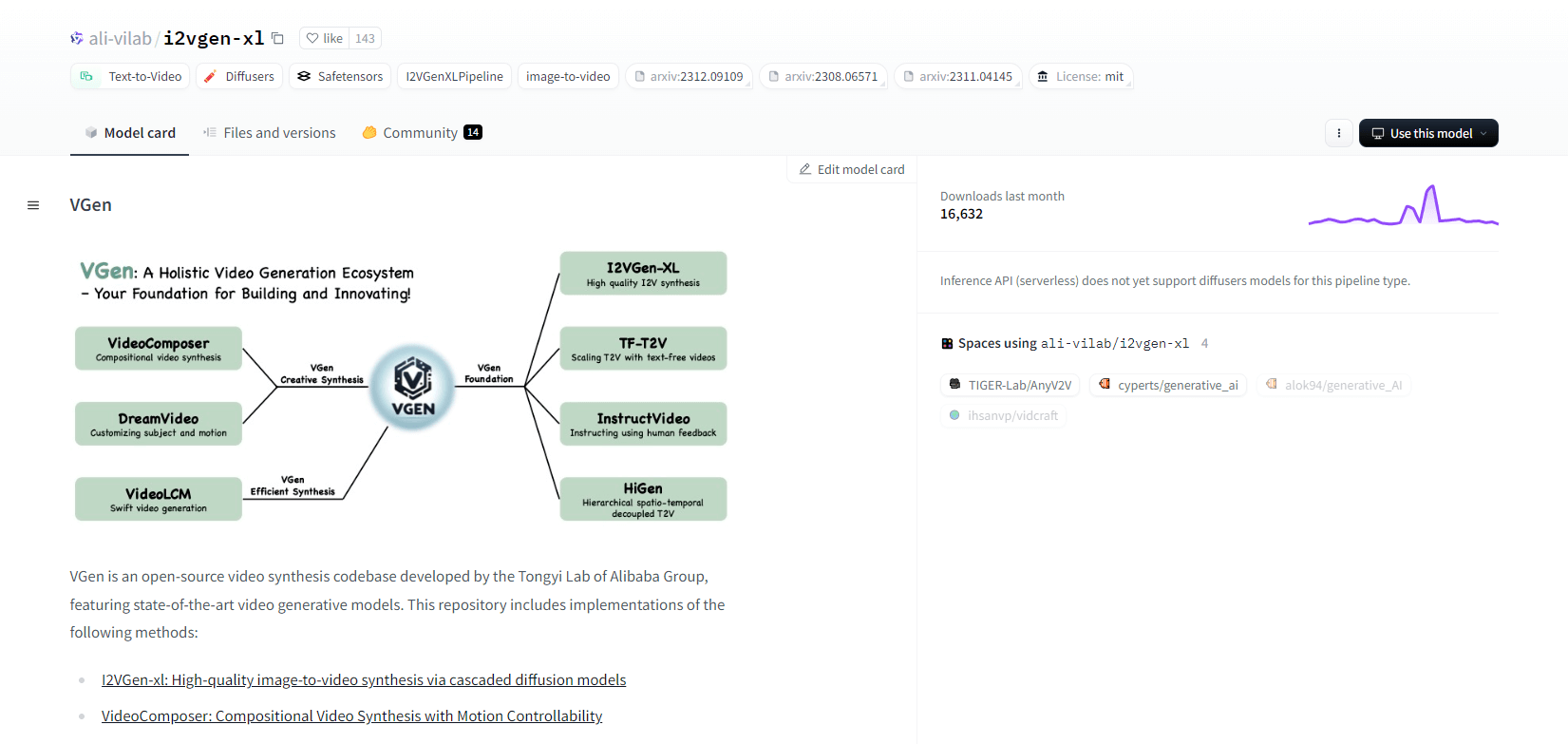
VGen, odprtokodna kodna baza za video sintezo iz Alibabinega laboratorija Tongyi, ponuja napredne video generativne modele. Vključuje metode, kot je I2VGen-xl za visokokakovostno sintezo slike v video, VideoComposer za video sintezo z nadzorom gibanja in še več. VGen lahko ustvari visokokakovostne videoposnetke iz besedila, slik, želenih gibov, subjektov in povratnih signalov. Repozitorij vsebuje orodja za vizualizacijo, vzorčenje, usposabljanje, sklepanje in skupno usposabljanje z uporabo slik in videoposnetkov. Nedavne posodobitve vključujejo VideoLCM, I2VGen-XL in metodo DreamVideo.
VGen se odlikuje po razširljivosti, zmogljivosti in popolnosti. Namestitev vključuje nastavitev okolja Python in potrebnih knjižnic. Uporabniki lahko učijo modele besedila v video in izvajajo I2VGen-XL za generiranje videa visoke ločljivosti. Na voljo so predstavitveni nabori podatkov in predhodno usposobljeni modeli, ki olajšajo eksperimentiranje in optimizacijo. Kodna baza zagotavlja enostavno upravljanje in visoko učinkovitost pri nalogah video sinteze.
Ključne značilnosti
- Odprtokodna kodna baza
- Visokokakovostna sinteza
- Možnost nadzora gibanja
- Generiranje besedila v video
- Pretvorba slike v video
- Razširljiv okvir
- Vnaprej usposobljeni modeli
- Obsežna orodja
Hotshot XL
Hotshot-XL, model besedila v GIF z umetno inteligenco, ki ga je razvil Natural Synthetics Inc., brezhibno deluje s Stable Diffusion XL. Omogoča generiranje GIF z uporabo katerega koli natančno nastavljenega modela SDXL, kar poenostavi ustvarjanje prilagojenih GIF brez dodatnega natančnega prilagajanja. Ta model je odličen pri ustvarjanju 1-sekundnih GIF-ov pri 8 sličicah na sekundo v različnih razmerjih stranic. Izkorišča latentno razširjanje s predhodno usposobljenimi kodirniki besedila (OpenCLIP-ViT/G in CLIP-ViT/L) za izboljšano zmogljivost.
Uporabniki lahko spreminjajo kompozicije GIF z uporabo SDXL ControlNet za prilagojene postavitve. Čeprav je zmožen vsestranskega ustvarjanja GIF, se Hotshot-XL sooča z izzivi fotorealizma in zapletenimi nalogami, kot je upodabljanje določenih kompozicij. Implementacija modela je namenjena nemoteni integraciji v obstoječe poteke dela in je na voljo za raziskovanje na GitHubu pod licenco CreativeML Open RAIL++-M.
Ključne značilnosti
- Generiranje besedila v GIF
- Deluje s SDXL
- Ustvari 1-sekundne GIF-e
- Podpira različna razmerja stranic
- Uporablja latentno difuzijo
- Vnaprej usposobljeni kodirniki besedila
- Prilagodljiv s ControlNet
- Na voljo na GitHubu
Prihodnje zmogljivosti modelov umetne inteligence za pretvorbo besedila v video
Platforme, kot je Hugging Face, so vodilne pri razvoju naprednih modelov, ki lahko pretvorijo besedilo v visokokakovostno, dinamično video vsebino. To nas vodi do predpostavke, da so prihodnje zmogljivosti modelov umetne inteligence besedila v video resnično vznemirljive.
Ti modeli so pripravljeni narediti revolucijo pri ustvarjanju vsebin, tako da postanejo hitrejše, učinkovitejše in dostopnejše kot kdaj koli prej. Z enostavnim vnosom besedilnega poziva bodo uporabniki lahko ustvarili privlačne, prilagojene videoposnetke, ki oživijo njihove zamisli.
Potencialnih aplikacij je ogromno – od trženja in oglaševanja do izobraževanja in zabave. Predstavljajte si, da lahko s klikom na gumb ustvarite videoposnetke z razlago profesionalnega razreda ali animirane zgodbe. Prihranek časa in stroškov za podjetja in ustvarjalce bo precejšen.
Poleg tega, ko se ti modeli besedila v video še naprej izboljšujejo v smislu realizma, skladnosti in prilagodljivosti, se bo kakovost izhoda vedno bolj ne razlikovala od videa, ki ga ustvari človek. Ta demokratizacija video produkcije bo več ljudem omogočila, da svoje zgodbe in zamisli delijo s svetom.
Prihodnost ustvarjanja vsebine je nedvomno pretvorba besedila v video in Hugging Face je v ospredju te transformativne tehnologije. Pripravite se na presenečenje, saj ti modeli premikajo meje možnega.
Zaključek
Za konec, Huggingface ponuja raznoliko paleto modelov za naloge pretvorbe besedila v video, od katerih ima vsak edinstvene prednosti pri ustvarjanju dinamične vizualne vsebine iz besedilnih opisov. Ne glede na to, ali dajete prednost natančnosti, ustvarjalnosti ali razširljivosti, ti modeli zagotavljajo robustne rešitve za različne aplikacije, ki obljubljajo napredek pri video sintezi, ki jo poganja AI.







