
Hugging Face — это золотая жила для всех, кто занимается обработкой естественного языка, наполненная множеством предварительно обученных языковых моделей, которые очень легко использовать в различных приложениях. Когда дело доходит до больших языковых моделей (LLM), Hugging Face — лучший выбор. В этой статье мы рассмотрим 10 лучших программ LLM по Hugging Face, каждый из которых играет ключевую роль в развитии того, как мы понимаем и создаем язык.

Давайте начнем!
Что такое модель большого языка?
Модели большого языка (LLM) — это продвинутые типы искусственного интеллекта, предназначенные для понимания и создания человеческого языка. Они построены с использованием методов глубокого обучения, в частности, нейронной сети, называемой трансформатором.
Вот разбивка, чтобы было понятно:
- Обучение работе с большими данными : LLM обучаются на огромных наборах данных, включая книги, статьи, веб-сайты и многое другое. Это обширное обучение помогает им изучить нюансы языка, включая грамматику, контекст и даже некоторый уровень рассуждения.
- Трансформаторы . Архитектура большинства LLM называется трансформером. Эта модель использует механизмы внимания для взвешивания важности разных слов в предложении, что позволяет лучше понимать контекст, чем предыдущие модели.
- Задачи, которые они выполняют : после обучения LLM могут выполнять различные языковые задачи. К ним относятся ответы на вопросы, обобщение текстов, перевод языков, создание творческого письма и кодирование.
- Популярные модели . Некоторые известные модели LLM включают GPT-3, BERT и T5. Эти предварительно обученные модели можно настроить для конкретных задач, что делает их универсальными инструментами для разработчиков и исследователей.
- Приложения : LLM используются в чат-ботах, виртуальных помощниках, автоматическом создании контента и многом другом. Они помогают улучшить взаимодействие пользователей с технологиями, заставляя машины более естественно понимать человеческий язык и реагировать на него.
По сути, модели большого языка подобны усиленному мозгу компьютеров, позволяющему им обрабатывать и генерировать человеческий язык с впечатляющей точностью и универсальностью.
HuggingFace и LLM
Hugging Face — это компания и платформа, которая стала центром обработки естественного языка (НЛП) и машинного обучения. Они предоставляют инструменты, библиотеки и ресурсы, упрощающие разработчикам и исследователям создание и использование моделей машинного обучения, особенно тех, которые связаны с пониманием и генерацией языков.
Hugging Face известен своими библиотеками с открытым исходным кодом, особенно Transformers , которые обеспечивают легкий доступ к широкому спектру предварительно обученных языковых моделей.
Hugging Face проводит множество современных программ LLM, таких как GPT-3, BERT и T5. Эти модели предварительно обучены на массивных наборах данных и готовы к использованию в различных приложениях.
Платформа предоставляет простые API и инструменты для интеграции этих моделей в приложения без глубоких знаний в области машинного обучения.
Используя инструменты Hugging Face, вы можете легко настроить эти предварительно обученные LLM на собственных данных, что позволит адаптировать их к конкретным задачам или областям.
Исследователи и разработчики могут делиться своими моделями и улучшениями на платформе Hugging Face, что ускоряет внедрение инноваций и их применение в НЛП.
5 лучших моделей LLM на Huggingface, которые вам стоит использовать
Давайте рассмотрим некоторые из лучших моделей LLM на Hugging Face, которые превосходно рассказывают истории и даже превосходят GPT.
Мистраль-7Б-v0.1
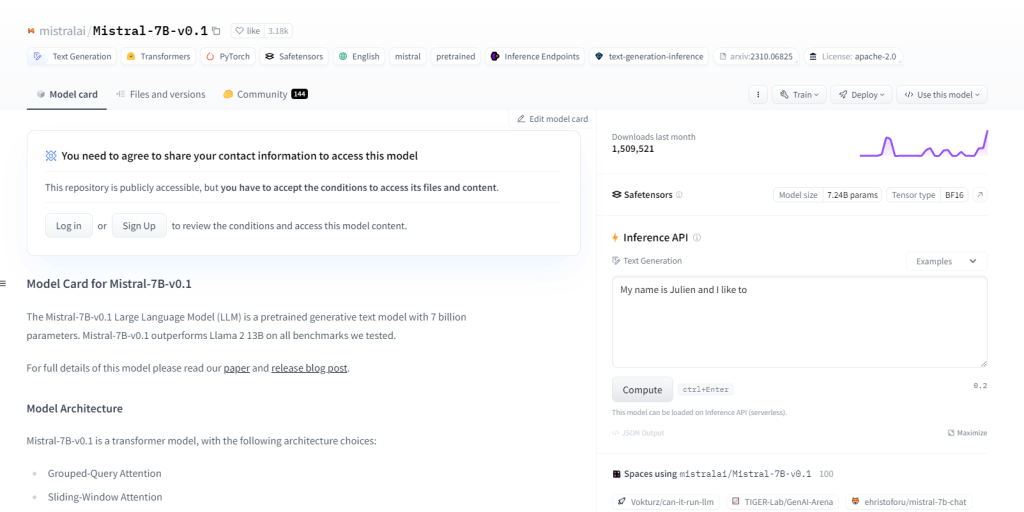
Mistral-7B-v0.1, модель большого языка (LLM) с 7 миллиардами параметров, превосходит такие тесты, как Llama 2 13B, во всех доменах. Он использует архитектуру преобразователя со специальными механизмами внимания и токенизатором BPE с резервным байтом. Он превосходно справляется с генерацией текста, пониманием естественного языка, языковым переводом и служит базовой моделью для исследований и разработок в проектах НЛП.
Ключевая особенность
- 7 миллиардов параметров
- Превосходит такие тесты, как Llama 213B
- Трансформаторная архитектура
- токенизатор BPE
- Разработка проектов НЛП
- Понимание естественного языка
- Языковой перевод
- Внимание группового запроса
Скворец-ЛМ-11Б-альфа
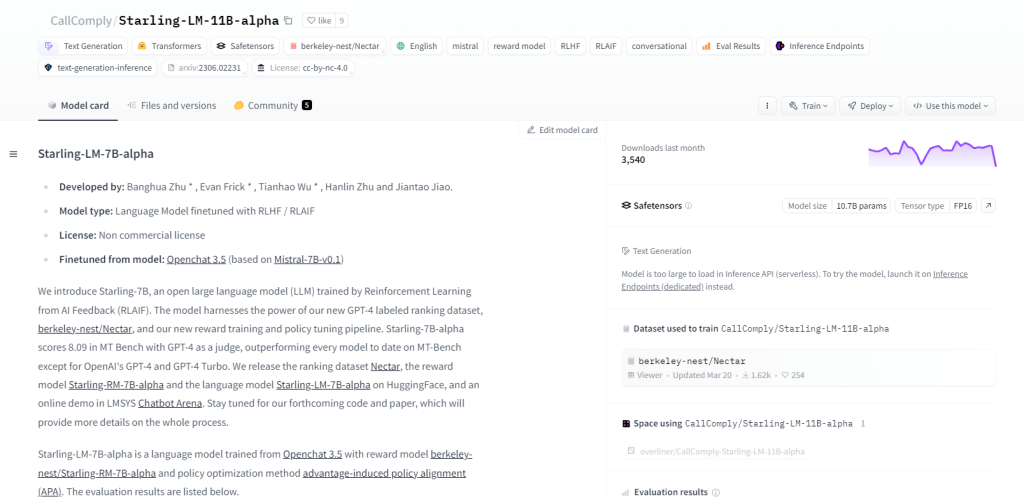
Starling-LM-11B-alpha, большая языковая модель (LLM) с 11 миллиардами параметров, разработана NurtureAI и использует в качестве основы модель OpenChat 3.5. Точная настройка достигается с помощью обучения с подкреплением на основе обратной связи ИИ (RLAIF), руководствуясь рейтингами, определяемыми людьми. Эта модель обещает изменить взаимодействие человека и машины благодаря своей структуре с открытым исходным кодом и универсальным приложениям, включая задачи НЛП, исследования машинного обучения, образование и создание творческого контента.
Ключевая особенность
- 11 миллиардов параметров
- Разработано NurtureAI
- На основе модели OpenChat 3.5.
- Точная настройка через RLAIF
- Рейтинги обучения, составленные человеком
- Открытый исходный код
- Разнообразные возможности
- Использование для исследований, образования и создания творческого контента.
Йи-34Б-Лама
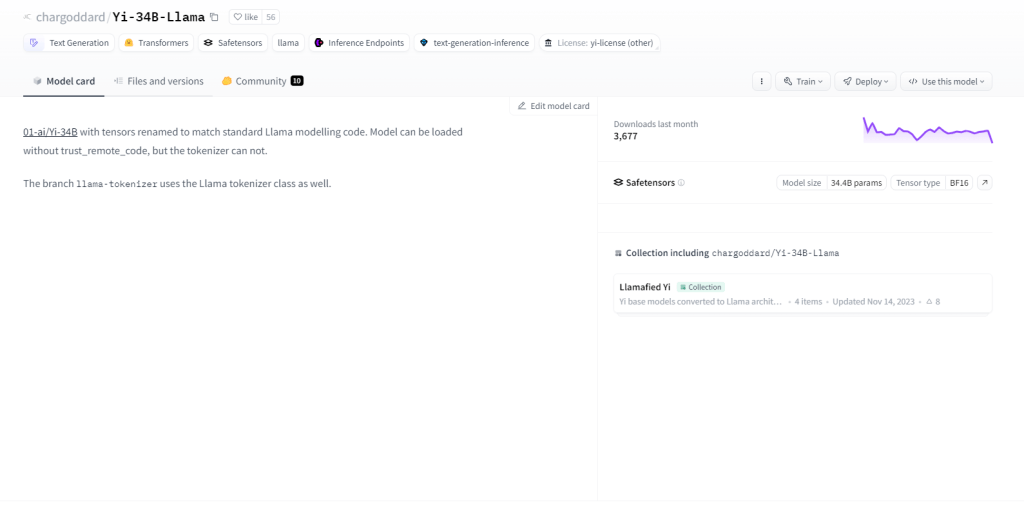
Yi-34B-Llama с 34 миллиардами параметров демонстрирует превосходные способности к обучению. Он превосходно справляется с мультимодальной обработкой, эффективной обработкой текста, кода и изображений. Благодаря принципу нулевого обучения он легко адаптируется к новым задачам. Его природа с сохранением состояния позволяет ему запоминать прошлые взаимодействия, повышая вовлеченность пользователей. Варианты использования включают генерацию текста, машинный перевод, ответы на вопросы, диалог, генерацию кода и подписи к изображениям.
Ключевая особенность
- 34 миллиарда параметров
- Мультимодальная обработка
- Возможность обучения с нуля
- Государственный характер
- Генерация текста
- Машинный перевод
- Ответ на вопрос
- Подпись к изображению
База DeepSeek LLM 67B
DeepSeek LLM 67B Base, модель большого языка (LLM) с 67 миллиардами параметров, отлично справляется с рассуждениями, кодированием и математическими задачами. Обладая исключительными результатами, превосходящими GPT-3.5 и Llama2 70B Base, он превосходно понимает и генерирует код, а также демонстрирует замечательные математические навыки. Его открытый исходный код под лицензией MIT обеспечивает свободное исследование. Варианты использования охватывают программирование, образование, исследования, создание контента, перевод и ответы на вопросы.
Ключевая особенность
- 67-миллиардный параметр
- Исключительные успехи в рассуждениях, программировании и математике.
- HumanEval Pass@1, балл 73,78
- Превосходное понимание и генерация кода
- Высокие баллы по GSM8K 0-shot (84,1)
- Превосходит GPT-3.5 по языковым возможностям
- Открытый исходный код под лицензией MIT
- Отличные возможности рассказывания историй и создания контента.
Skote — Svelte шаблон для администрирования и информационной панели
Marcoroni-7B-v3 — это мощная многоязычная генеративная модель с 7 миллиардами параметров, способная решать разнообразные задачи, включая генерацию текста, языковой перевод, создание творческого контента и ответы на вопросы. Он превосходно обрабатывает как текст, так и код, используя нулевое обучение для быстрого выполнения задач без предварительного обучения. Marcoroni-7B-v3 с открытым исходным кодом и под разрешительной лицензией облегчает широкое использование и экспериментирование.
Ключевая особенность
- Генерация текста для стихов, кода, сценариев, электронных писем и многого другого.
- Высокоточный машинный перевод.
- Создание привлекательных чат-ботов с естественным диалогом.
- Генерация кода из описаний на естественном языке.
- Широкие возможности ответов на вопросы.
- Обобщение длинных текстов в краткие аннотации.
- Эффективный перефраз с сохранением исходного смысла.
- Анализ тональности текстового контента.
Подведение итогов
Коллекция больших языковых моделей Hugging Face меняет правила игры как для разработчиков, исследователей, так и для энтузиастов. Эти модели играют большую роль в расширении границ понимания и создания естественного языка благодаря своей разнообразной архитектуре и возможностям. По мере развития технологий возможности применения и влияние этих моделей безграничны. Исследование и внедрение инноваций в области больших языковых моделей продолжается и обещает впереди захватывающие разработки.








