
Рост технологии преобразования текста в видео на основе искусственного интеллекта меняет способ создания и потребления контента. На переднем крае этой трансформации находятся мощные модели Hugging Face, которые быстро становятся инструментами, к которым обращаются создатели контента и компании.

Эти современные языковые модели, обученные на огромных массивах данных, обладают замечательной способностью переводить письменный текст в захватывающие визуальные повествования. Используя последние достижения в обработке естественного языка и генеративном ИИ, модели Hugging Face могут без усилий преобразовать ваши слова в увлекательные, высококачественные видеоролики, которые увлекут вашу аудиторию.
Понимание технологии преобразования текста в видео
Модели «текст-видео» преобразуют письменные описания в движущиеся изображения. Эти модели понимают текст и преобразуют его в последовательность кадров, которые изображают описываемую сцену или действие. Этот процесс включает несколько этапов, включая анализ текста, генерацию визуального контента и последовательность кадров. Каждый этап требует сложных алгоритмов для обеспечения того, чтобы выходное видео точно представляло входной текст.
Путь технологии преобразования текста в видео начался с простых текстовых описаний, создающих базовые анимации. Ранние модели были сосредоточены на создании статических изображений, но достижения в области ИИ и машинного обучения позволили разработать динамическую генерацию видео. За эти годы исследователи интегрировали сложные нейронные сети, что привело к значительному улучшению качества и реалистичности видео. Эти достижения открыли новые возможности для создания креативного контента и различных приложений в различных отраслях.
5 лучших моделей искусственного интеллекта для преобразования текста в видео от Huggingface
Здесь у нас есть 5 лучших моделей AI text-to-video от huggingface. Эти модели очень популярны благодаря своей уникальной функциональности и имеют наибольшее количество загрузок.
МодельСкоп - 1.7b
Модель синтеза текста в видео от ModelScope использует многоступенчатый процесс диффузии для генерации видео из текстовых описаний. Эта продвинутая модель поддерживает только английский ввод и разработана для исследовательских целей. Она состоит из трех подсетей: извлечение признаков текста, диффузия скрытого пространства текста в видео и отображение скрытого пространства видео в визуальное пространство.
С 1,7 миллиардами параметров и структурой UNet3D он итеративно подавляет гауссовский шум для создания видео. Эта модель подходит для различных приложений, таких как создание видео из произвольного английского текста. Однако у нее есть ограничения, такие как смещения от обучающих данных и невозможность создания высококачественных видео уровня фильма или чистого текста. Пользователи должны избегать создания вредоносного или ложного контента. Модель была обучена на общедоступных наборах данных, включая LAION5B, ImageNet и Webvid.
Основные характеристики
- Многоступенчатый процесс диффузии
- Поддержка английского текста
- 1,7 миллиарда параметров
- Архитектура UNet3D
- Метод итерационного шумоподавления
- Фокус цели исследования
- Обучение работе с публичными наборами данных
- Генерация произвольного текста
AnimateDiff-Молния
AnimateDiff-Lightning — это передовая модель генерации текста в видео, которая обеспечивает повышение скорости по сравнению с оригинальной AnimateDiff, генерируя видео более чем в десять раз быстрее. Разработанная на основе AnimateDiff SD1.5 v2, эта модель доступна в 1-шаговой, 2-шаговой, 4-шаговой и 8-шаговой версиях, причем модели с более высоким шагом обеспечивают превосходное качество. Она отлично работает со стилизованными базовыми моделями, такими как epiCRealism и Realistic Vision, а также с моделями аниме и мультфильмов, такими как ToonYou и Mistoon Anime.
Пользователи могут достичь оптимальных результатов, экспериментируя с различными настройками, например, используя Motion LoRAs. Для реализации модель может использоваться с Diffusers и ComfyUI. Она поддерживает генерацию видео-в-видео с ControlNet для улучшенного вывода. Для получения более подробной информации и демонстрации пользователям рекомендуется обратиться к исследовательской статье: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Основные характеристики
- Молниеносная генерация видео
- Взято из AnimateDiff
- Многоступенчатые контрольные точки
- Высокое качество генерации
- Поддерживает стилизованные модели
- Поддержка Motion LoRA
- Реалистичные и мультяшные варианты
- Генерация видео-в-видео
Зероскоп V2
Видеомодель zeroscope_v2_567w на основе Modelscope отлично подходит для создания высококачественных видео 16:9 без водяных знаков. Обученная на 9923 клипах и 29769 тегированных кадрах с разрешением 576x320 и 24 кадрами в секунду, она идеально подходит для плавного вывода видео. Эта модель предназначена для первоначального рендеринга перед масштабированием с zeroscope_v2_XL с использованием vid2vid в расширении 1111 text2video, что позволяет эффективно исследовать при более низких разрешениях.
Масштабирование до 1024x576 обеспечивает превосходные композиции. Использует 7,9 ГБ VRAM для рендеринга 30 кадров. Для использования загрузите и замените файлы в соответствующем каталоге.
Для достижения наилучших результатов масштабируйте с помощью zeroscope_v2_XL с уровнем шумоподавления от 0,66 до 0,85. Известные проблемы включают неоптимальный вывод при более низких разрешениях или меньшем количестве кадров. Модель можно легко интегрировать с помощью Diffusers с простой установкой и шагами генерации видео.
Основные характеристики
- Вывод без водяных знаков
- Высокое качество 16:9
- Плавный вывод видео
- разрешение 576x320
- 24 кадра в секунду
- Эффективное масштабирование
- Использование 7,9 ГБ видеопамяти
- Простая интеграция
VGen
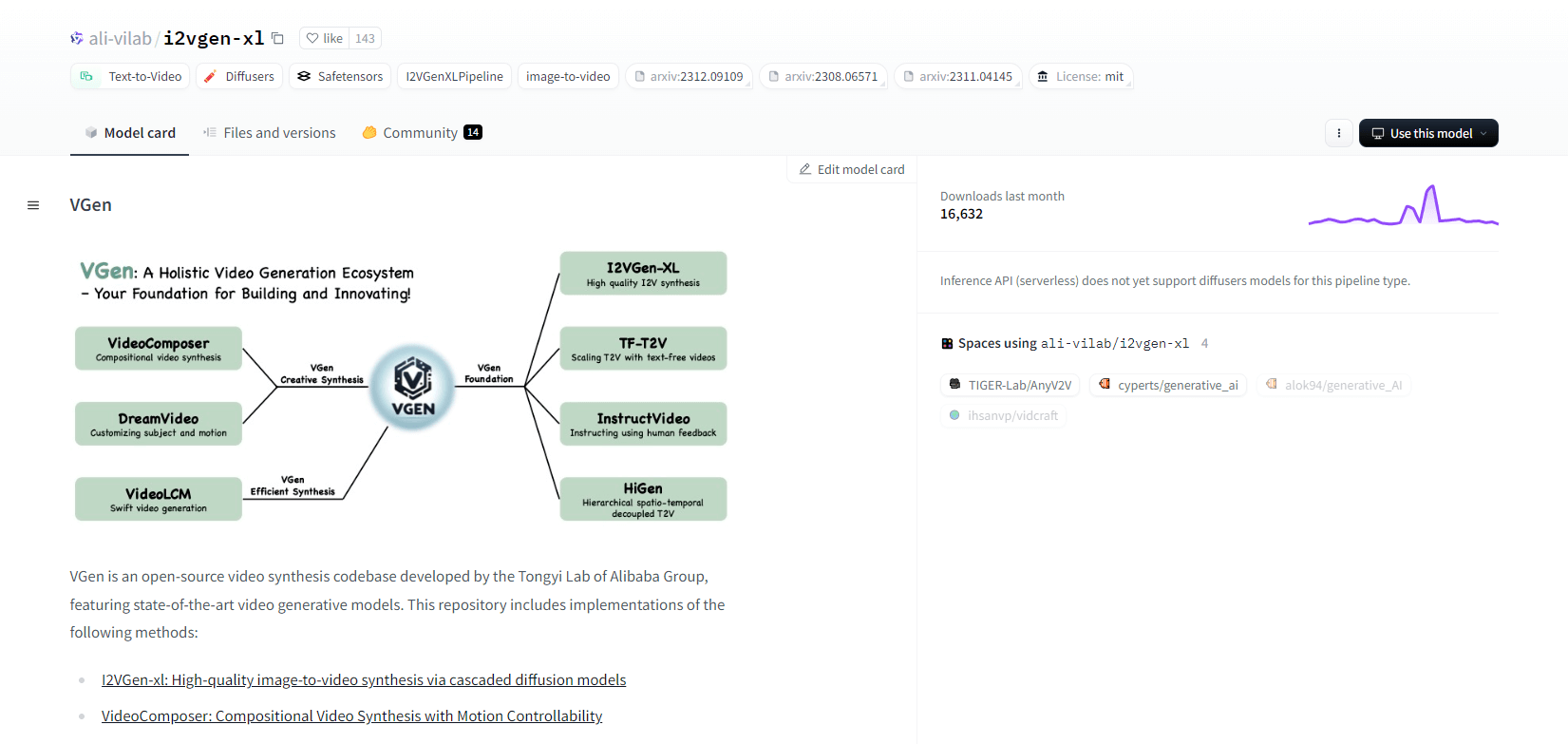
VGen, кодовая база видеосинтеза с открытым исходным кодом от Tongyi Lab компании Alibaba, предлагает передовые модели генерации видео. Она включает такие методы, как I2VGen-xl для высококачественного синтеза изображения в видео, VideoComposer для контролируемого движением синтеза видео и многое другое. VGen может создавать высококачественные видео из текста, изображений, желаемых движений, субъектов и сигналов обратной связи. В репозитории представлены инструменты для визуализации, выборки, обучения, вывода и совместного обучения с использованием изображений и видео. Последние обновления включают VideoLCM, I2VGen-XL и метод DreamVideo.
VGen отличается расширяемостью, производительностью и полнотой. Установка включает настройку среды Python и необходимых библиотек. Пользователи могут обучать модели преобразования текста в видео и запускать I2VGen-XL для генерации видео высокой четкости. Демонстрационные наборы данных и предварительно обученные модели доступны для облегчения экспериментов и оптимизации. Кодовая база обеспечивает простоту управления и высокую эффективность в задачах синтеза видео.
Основные характеристики
- База открытого исходного кода
- Высококачественный синтез
- Управляемость движения
- Генерация текста в видео
- Преобразование изображения в видео
- Расширяемая структура
- Предварительно обученные модели
- Комплексные инструменты
Хотшот XL
Hotshot-XL, модель AI text-to-GIF, разработанная Natural Synthetics Inc., работает без проблем со Stable Diffusion XL. Она позволяет генерировать GIF с использованием любой точно настроенной модели SDXL, упрощая создание персонализированных GIF без дополнительной тонкой настройки. Эта модель отлично справляется с генерацией 1-секундных GIF со скоростью 8 кадров в секунду при различных соотношениях сторон. Она использует Latent Diffusion с предварительно обученными текстовыми кодировщиками (OpenCLIP-ViT/G и CLIP-ViT/L) для повышения производительности.
Пользователи могут изменять композиции GIF с помощью SDXL ControlNet для создания индивидуальных макетов. Несмотря на то, что Hotshot-XL способен создавать универсальные GIF-файлы, он сталкивается с трудностями, связанными с фотореализмом и сложными задачами, такими как рендеринг определенных композиций. Реализация модели направлена на плавную интеграцию в существующие рабочие процессы и доступна для изучения на GitHub под лицензией CreativeML Open RAIL++-M.
Основные характеристики
- Генерация текста в GIF
- Работает с SDXL
- Создает GIF-файлы длительностью 1 секунда
- Поддерживает различные соотношения сторон
- Использует скрытую диффузию
- Предварительно обученные текстовые кодировщики
- Настраивается с помощью ControlNet
- Доступно на GitHub
Будущие возможности моделей искусственного интеллекта для преобразования текста в видео
Такие платформы, как Hugging Face, лидируют в разработке продвинутых моделей, которые могут преобразовывать текст в высококачественный, динамичный видеоконтент. Это приводит нас к предположению, что будущие возможности моделей ИИ для преобразования текста в видео действительно захватывающие.
Эти модели готовы произвести революцию в создании контента, сделав его более быстрым, эффективным и доступным, чем когда-либо прежде. Просто введя текстовую подсказку, пользователи смогут создавать увлекательные, персонализированные видео, которые воплощают их идеи в жизнь.
Потенциальные приложения огромны — от маркетинга и рекламы до образования и развлечений. Представьте себе возможность создавать профессиональные пояснительные видеоролики или анимированные истории одним нажатием кнопки. Экономия времени и средств для предприятий и создателей будет существенной.
Более того, поскольку эти модели преобразования текста в видео продолжают совершенствоваться с точки зрения реалистичности, связности и гибкости, качество вывода будет все более неотличимым от видео, созданного человеком. Эта демократизация видеопроизводства позволит большему количеству людей делиться своими историями и идеями с миром.
Будущее создания контента, несомненно, за преобразованием текста в видео, и Hugging Face находится на переднем крае этой преобразующей технологии. Приготовьтесь удивляться, поскольку эти модели расширяют границы возможного.
Подведение итогов
В заключение, Huggingface предлагает широкий спектр моделей для задач преобразования текста в видео, каждая из которых обладает уникальными преимуществами в создании динамического визуального контента из текстовых описаний. Независимо от того, отдаете ли вы приоритет точности, креативности или масштабируемости, эти модели предоставляют надежные решения для различных приложений, обещающие достижения в области синтеза видео на основе ИИ.









