
A ascensão da tecnologia de texto para vídeo alimentada por IA está revolucionando a maneira como criamos e consumimos conteúdo. Na vanguarda dessa transformação estão os poderosos modelos Hugging Face, que estão rapidamente se tornando as ferramentas preferidas tanto para criadores de conteúdo quanto para empresas.

Esses modelos de linguagem de última geração, treinados em vastos tesouros de dados, possuem a notável capacidade de traduzir texto escrito em narrativas visuais cativantes. Ao alavancar os últimos avanços em processamento de linguagem natural e IA generativa, os modelos Hugging Face podem transformar sem esforço suas palavras em vídeos envolventes e de alta qualidade que cativam seu público.
Compreendendo a tecnologia de conversão de texto em vídeo
Modelos de texto para vídeo transformam descrições escritas em imagens em movimento. Esses modelos entendem o texto e o convertem em uma sequência de quadros que descrevem a cena ou ação descrita. Esse processo envolve várias etapas, incluindo análise de texto, geração de conteúdo visual e sequenciamento de quadros. Cada etapa requer algoritmos complexos para garantir que o vídeo de saída represente com precisão o texto de entrada.
A jornada da tecnologia de texto para vídeo começou com descrições de texto simples gerando animações básicas. Os primeiros modelos focavam na criação de imagens estáticas, mas os avanços em IA e aprendizado de máquina permitiram o desenvolvimento da geração dinâmica de vídeo. Ao longo dos anos, os pesquisadores integraram redes neurais sofisticadas, levando a melhorias significativas na qualidade e realismo do vídeo. Esses avanços abriram novas possibilidades para a criação de conteúdo criativo e várias aplicações em todos os setores.
5 melhores modelos de IA de texto para vídeo da Huggingface
Aqui temos os 5 melhores modelos de texto para vídeo de IA da HugFace. Esses modelos são muito populares por sua funcionalidade distinta e têm o maior número de downloads.
ModeloScope - 1.7b
O modelo de síntese de texto para vídeo do ModelScope usa um processo de difusão de vários estágios para gerar vídeos a partir de descrições de texto. Este modelo avançado suporta apenas entrada em inglês e é projetado para fins de pesquisa. Ele consiste em três sub-redes: extração de recursos de texto, difusão de espaço latente de texto para vídeo e mapeamento de espaço latente de vídeo para espaço visual.
Com 1,7 bilhão de parâmetros e uma estrutura UNet3D, ele reduz iterativamente o ruído gaussiano para criar vídeos. Este modelo é adequado para várias aplicações, como criar vídeos a partir de texto inglês arbitrário. No entanto, ele tem limitações, como vieses de dados de treinamento e incapacidade de produzir vídeos de nível de filme de alta qualidade ou texto claro. Os usuários devem evitar gerar conteúdo prejudicial ou falso. O modelo foi treinado em conjuntos de dados públicos, incluindo LAION5B, ImageNet e Webvid.
Principais características
- Processo de difusão multiestágio
- Suporte de texto em inglês
- 1,7 bilhões de parâmetros
- Arquitetura UNet3D
- Método de redução de ruído iterativo
- Foco no propósito da pesquisa
- Treinamento de conjunto de dados públicos
- Geração de texto arbitrário
AnimateDiff-Relâmpago
O AnimateDiff-Lightning é um modelo de geração de texto para vídeo de ponta que oferece melhorias de velocidade em relação ao AnimateDiff original, gerando vídeos mais de dez vezes mais rápido. Desenvolvido a partir do AnimateDiff SD1.5 v2, este modelo está disponível em versões de 1, 2, 4 e 8 etapas, com modelos de etapas mais altas oferecendo qualidade superior. Ele se destaca quando usado com modelos de base estilizados como epiCRealism e Realistic Vision, bem como modelos de anime e desenho animado como ToonYou e Mistoon Anime.
Os usuários podem obter resultados ótimos experimentando diferentes configurações, como usar Motion LoRAs. Para implementação, o modelo pode ser usado com Diffusers e ComfyUI. Ele suporta geração de vídeo para vídeo com ControlNet para saída aprimorada. Para mais detalhes e uma demonstração, os usuários são encorajados a consultar o artigo de pesquisa: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Principais características
- Geração de vídeo extremamente rápida
- Destilado de AnimateDiff
- Pontos de verificação de várias etapas
- Alta qualidade de geração
- Suporta modelos estilizados
- Suporte a LoRAs de movimento
- Opções realistas e de desenho animado
- Geração de vídeo para vídeo
Zeroscópio V2
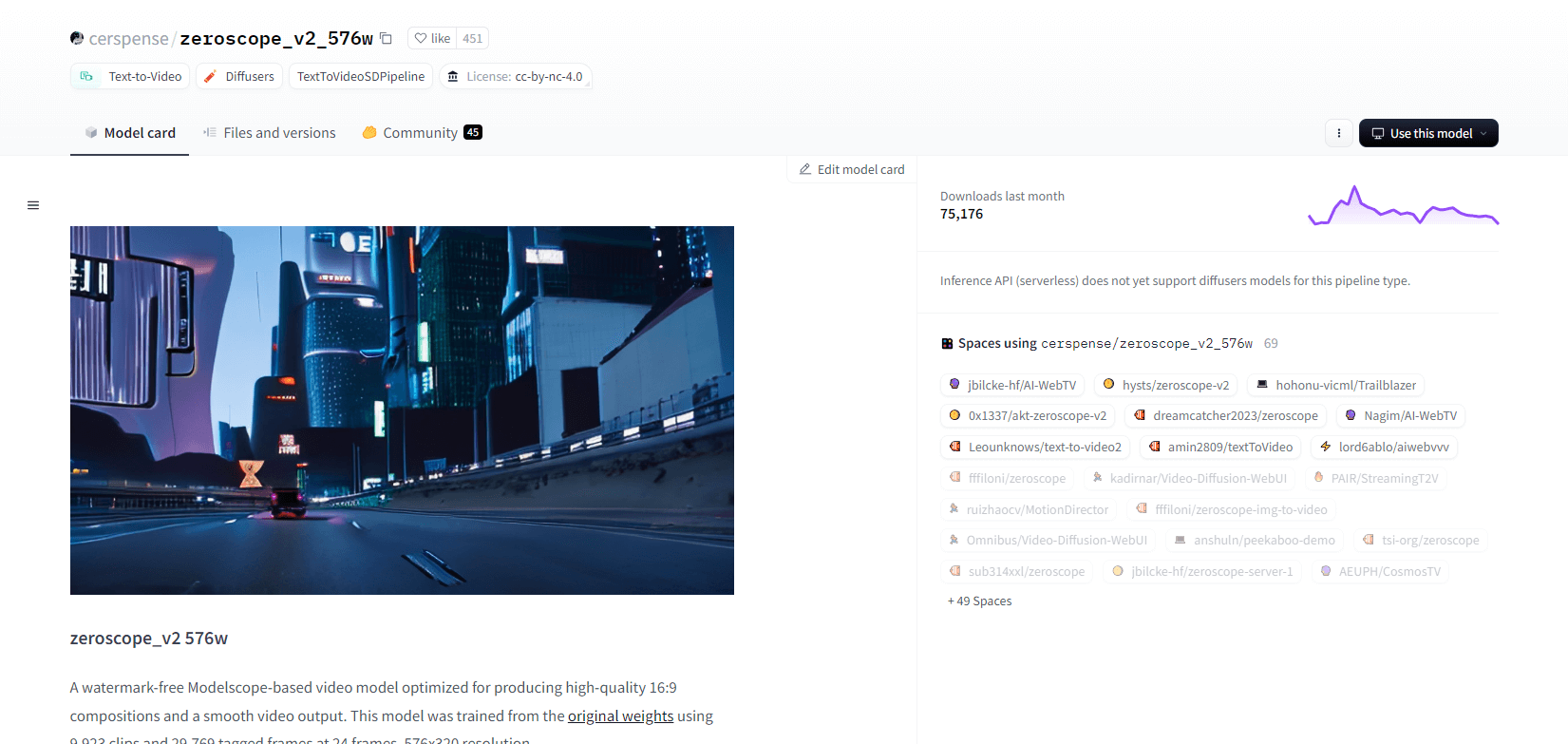
O modelo de vídeo zeroscope_v2_567w baseado em Modelscope se destaca na criação de vídeos 16:9 de alta qualidade sem marcas d'água. Treinado em 9.923 clipes e 29.769 quadros marcados com resolução de 576x320 e 24 quadros por segundo, é ideal para saída de vídeo suave. Este modelo foi projetado para renderização inicial antes do upscaling com zeroscope_v2_XL usando vid2vid na extensão text2video 1111, permitindo exploração eficiente em resoluções mais baixas.
O upscaling para 1024x576 fornece composições superiores. Ele usa 7,9 GB de VRAM para renderizar 30 quadros. Para usar, baixe e substitua os arquivos no diretório apropriado.
Para melhores resultados, faça upscale usando zeroscope_v2_XL com uma intensidade de denoise entre 0,66 e 0,85. Problemas conhecidos incluem saída abaixo do ideal em resoluções mais baixas ou menos quadros. O modelo pode ser facilmente integrado usando Diffusers com etapas simples de instalação e geração de vídeo.
Principais características
- Saída sem marca d'água
- Alta qualidade 16:9
- Saída de vídeo suave
- Resolução 576x320
- 24 quadros por segundo
- Aumento de escala eficiente
- Uso de VRAM de 7,9 GB
- Fácil integração
VGen
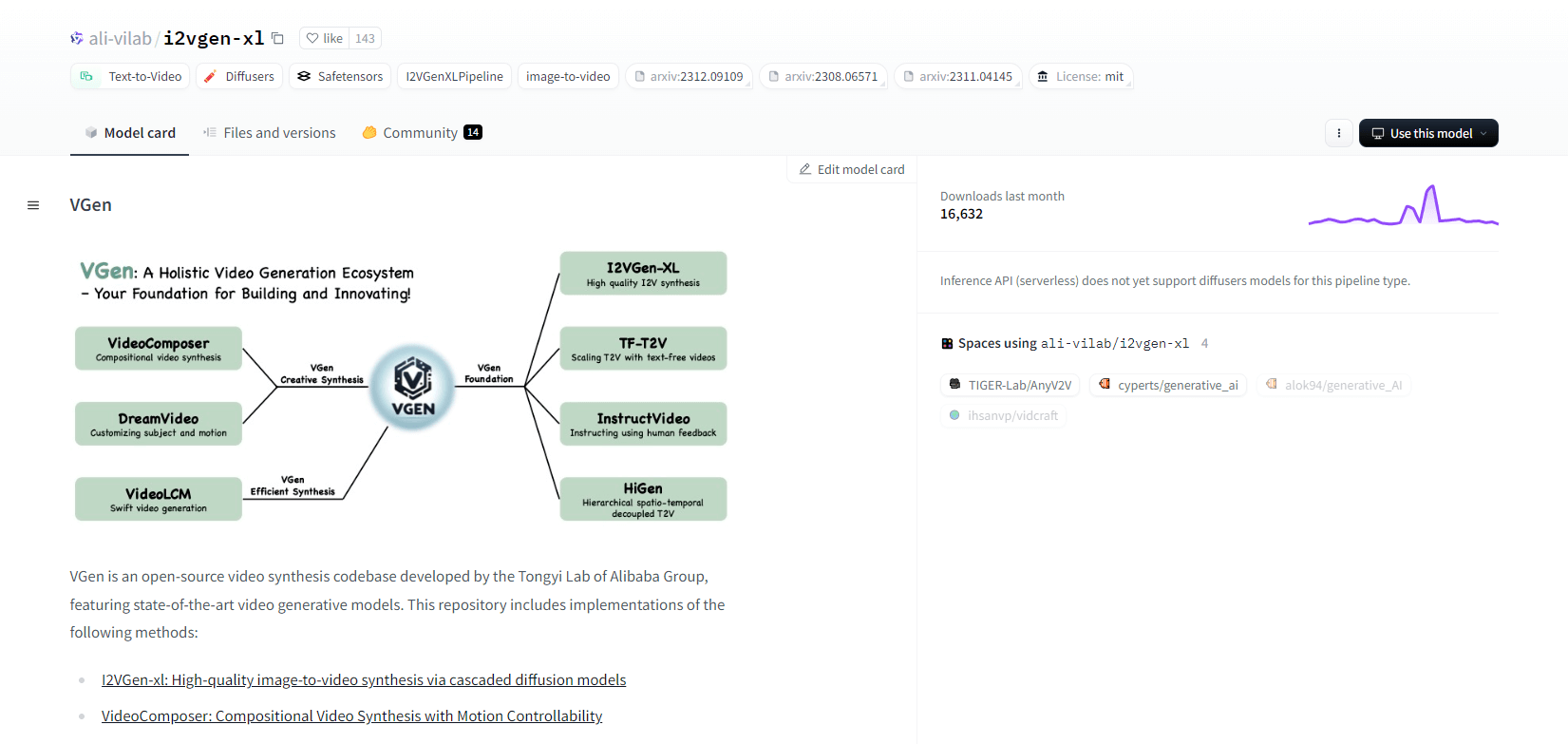
VGen, uma base de código de síntese de vídeo de código aberto do Tongyi Lab do Alibaba, oferece modelos generativos de vídeo avançados. Inclui métodos como I2VGen-xl para síntese de imagem para vídeo de alta qualidade, VideoComposer para síntese de vídeo controlável por movimento e muito mais. O VGen pode criar vídeos de alta qualidade a partir de texto, imagens, movimentos desejados, assuntos e sinais de feedback. O repositório apresenta ferramentas para visualização, amostragem, treinamento, inferência e treinamento conjunto usando imagens e vídeos. Atualizações recentes incluem VideoLCM, I2VGen-XL e o método DreamVideo.
O VGen se destaca em expansibilidade, desempenho e completude. A instalação envolve a configuração de um ambiente Python e bibliotecas necessárias. Os usuários podem treinar modelos de texto para vídeo e executar o I2VGen-XL para geração de vídeo de alta definição. Conjuntos de dados de demonstração e modelos pré-treinados estão disponíveis para facilitar a experimentação e a otimização. A base de código garante fácil gerenciamento e alta eficiência em tarefas de síntese de vídeo.
Principais características
- Base de código de código aberto
- Síntese de alta qualidade
- Controlabilidade de movimento
- Geração de texto para vídeo
- Conversão de imagem para vídeo
- Estrutura expansível
- Modelos pré-treinados
- Ferramentas abrangentes
Tiro quente XL
Hotshot-XL, um modelo de texto para GIF de IA desenvolvido pela Natural Synthetics Inc., opera perfeitamente com o Stable Diffusion XL. Ele permite a geração de GIF usando qualquer modelo SDXL ajustado, simplificando a criação de GIFs personalizados sem ajustes finos adicionais. Este modelo se destaca na geração de GIFs de 1 segundo a 8 quadros por segundo em várias proporções de aspecto. Ele aproveita o Latent Diffusion com codificadores de texto pré-treinados (OpenCLIP-ViT/G e CLIP-ViT/L) para desempenho aprimorado.
Os usuários podem modificar composições de GIF usando o SDXL ControlNet para layouts personalizados. Embora seja capaz de criação versátil de GIF, o Hotshot-XL enfrenta desafios com fotorrealismo e tarefas complexas como renderizar composições específicas. A implementação do modelo visa integrar-se suavemente aos fluxos de trabalho existentes e está disponível para exploração no GitHub sob uma licença CreativeML Open RAIL++-M.
Principais características
- Geração de texto para GIF
- Funciona com SDXL
- Gera GIFs de 1 segundo
- Suporta várias proporções de aspecto
- Utiliza difusão latente
- Codificadores de texto pré-treinados
- Personalizável com ControlNet
- Disponível no GitHub
Capacidades futuras de modelos de IA de texto para vídeo
Plataformas como a Hugging Face estão liderando o caminho no desenvolvimento de modelos avançados que podem transformar texto em conteúdo de vídeo dinâmico e de alta qualidade. Isso nos leva a supor que - as capacidades futuras dos modelos de IA de texto para vídeo são realmente empolgantes.
Esses modelos estão prontos para revolucionar a criação de conteúdo, tornando-a mais rápida, mais eficiente e mais acessível do que nunca. Simplesmente inserindo um prompt de texto, os usuários poderão gerar vídeos envolventes e personalizados que dão vida às suas ideias.
As aplicações potenciais são vastas - de marketing e publicidade a educação e entretenimento. Imagine ser capaz de criar vídeos explicativos de nível profissional ou histórias animadas com o clique de um botão. A economia de tempo e custo para empresas e criadores será substancial.
Além disso, à medida que esses modelos de texto para vídeo continuam a melhorar em termos de realismo, coerência e flexibilidade, a qualidade da saída se tornará cada vez mais indistinguível do vídeo criado por humanos. Essa democratização da produção de vídeo capacitará mais pessoas a compartilhar suas histórias e ideias com o mundo.
O futuro da criação de conteúdo é, sem dúvida, texto para vídeo, e a Hugging Face está na vanguarda dessa tecnologia transformadora. Prepare-se para se surpreender enquanto esses modelos expandem os limites do que é possível.
Encerrando
Concluindo, o Huggingface oferece uma gama diversificada de modelos para tarefas de texto para vídeo, cada um trazendo pontos fortes únicos na geração de conteúdo visual dinâmico a partir de descrições textuais. Não importa se você prioriza precisão, criatividade ou escalabilidade, esses modelos fornecem soluções robustas para várias aplicações, prometendo avanços na síntese de vídeo orientada por IA.









