
Hugging Face é uma mina de ouro para qualquer pessoa interessada em processamento de linguagem natural, repleto de uma variedade de modelos de linguagem pré-treinados que são super fáceis de usar em diferentes aplicações. Quando se trata de Large Language Models (LLMs), Hugging Face é a melhor escolha. Neste artigo, mergulharemos nos 10 principais LLMs em Hugging Face, cada um desempenhando um papel fundamental no avanço da forma como entendemos e geramos a linguagem.

Vamos começar!
O que é o modelo de linguagem grande?
Large Language Models (LLMs) são tipos avançados de inteligência artificial projetados para compreender e gerar a linguagem humana. Eles são construídos usando técnicas de aprendizagem profunda, particularmente um tipo de rede neural chamada transformador.
Aqui está um detalhamento para deixar isso claro:
- Treinamento em dados massivos : LLMs são treinados em grandes conjuntos de dados que incluem livros, artigos, sites e muito mais. Este extenso treinamento os ajuda a aprender as nuances da linguagem, incluindo gramática, contexto e até mesmo algum nível de raciocínio.
- Transformadores : A arquitetura por trás da maioria dos LLMs é chamada de transformador. Este modelo utiliza mecanismos de atenção para pesar a importância de diferentes palavras em uma frase, permitindo compreender melhor o contexto do que os modelos anteriores.
- Tarefas que executam : Uma vez treinados, os LLMs podem realizar várias tarefas linguísticas. Isso inclui responder perguntas, resumir textos, traduzir idiomas, gerar escrita criativa e codificação.
- Modelos populares : alguns LLMs bem conhecidos incluem GPT-3, BERT e T5. Esses modelos pré-treinados podem ser ajustados para tarefas específicas, tornando-os ferramentas versáteis para desenvolvedores e pesquisadores.
- Aplicações : LLMs são usados em chatbots, assistentes virtuais, criação automatizada de conteúdo e muito mais. Eles ajudam a melhorar as interações do usuário com a tecnologia, fazendo com que as máquinas entendam e respondam à linguagem humana de forma mais natural.
Em essência, os Grandes Modelos de Linguagem são como cérebros sobrecarregados para computadores, permitindo-lhes manipular e gerar linguagem humana com precisão e versatilidade impressionantes.
HuggingFace e LLM
Hugging Face é uma empresa e uma plataforma que se tornou um centro de processamento de linguagem natural (PNL) e aprendizado de máquina. Eles fornecem ferramentas, bibliotecas e recursos para facilitar aos desenvolvedores e pesquisadores a construção e o uso de modelos de aprendizado de máquina, especialmente aqueles relacionados à compreensão e geração de linguagem.
Hugging Face é conhecido por suas bibliotecas de código aberto, especialmente Transformers , que fornecem acesso fácil a uma ampla variedade de modelos de linguagem pré-treinados.
Hugging Face hospeda muitos LLMs de última geração, como GPT-3, BERT e T5. Esses modelos são pré-treinados em grandes conjuntos de dados e estão prontos para serem usados em diversas aplicações.
A plataforma fornece APIs e ferramentas simples para integrar esses modelos em aplicativos sem exigir profundo conhecimento em aprendizado de máquina.
Usando as ferramentas do Hugging Face, você pode ajustar facilmente esses LLMs pré-treinados com seus próprios dados, permitindo adaptá-los a tarefas ou domínios específicos.
Pesquisadores e desenvolvedores podem compartilhar seus modelos e melhorias na plataforma Hugging Face, acelerando a inovação e a aplicação em PNL.
Os 5 principais modelos LLM no Huggingface que você deve usar
Vamos explorar alguns dos principais modelos de LLM em Hugging Face que se destacam em contar histórias e até superam o GPT.
Mistral-7B-v0.1
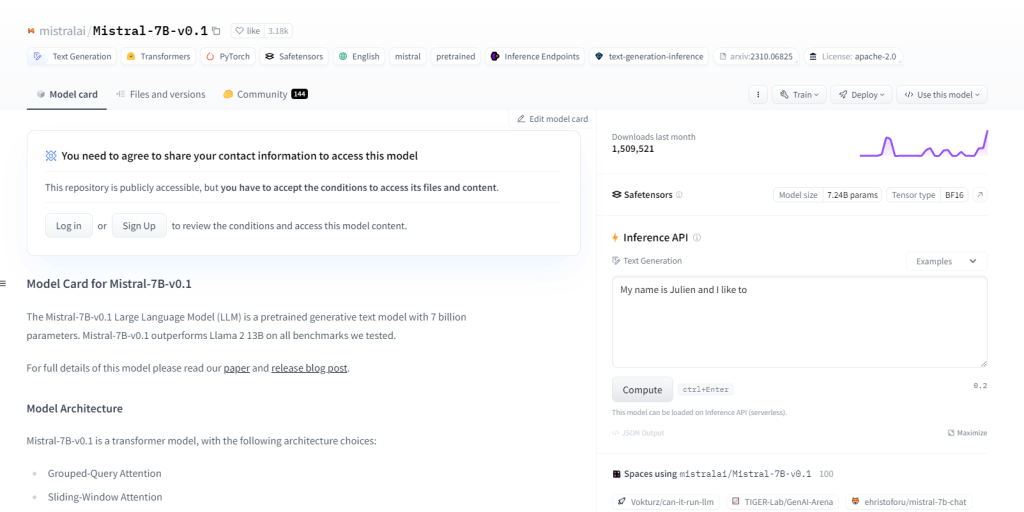
O Mistral-7B-v0.1, um Large Language Model (LLM) com 7 bilhões de parâmetros, supera benchmarks como Llama 2 13B em todos os domínios. Ele utiliza arquitetura de transformador com mecanismos de atenção específicos e um tokenizer BPE de byte-fallback. É excelente na geração de texto, compreensão de linguagem natural, tradução de idiomas e serve como modelo base para pesquisa e desenvolvimento em projetos de PNL.
Características principais
- 7 bilhões de parâmetros
- Supera benchmarks como Llama 213B
- Arquitetura do transformador
- Tokenizador BPE
- Desenvolvimento de Projetos de PNL
- Compreensão da linguagem natural
- Tradução de idiomas
- Atenção de consulta agrupada
Starling-LM-11B-alfa
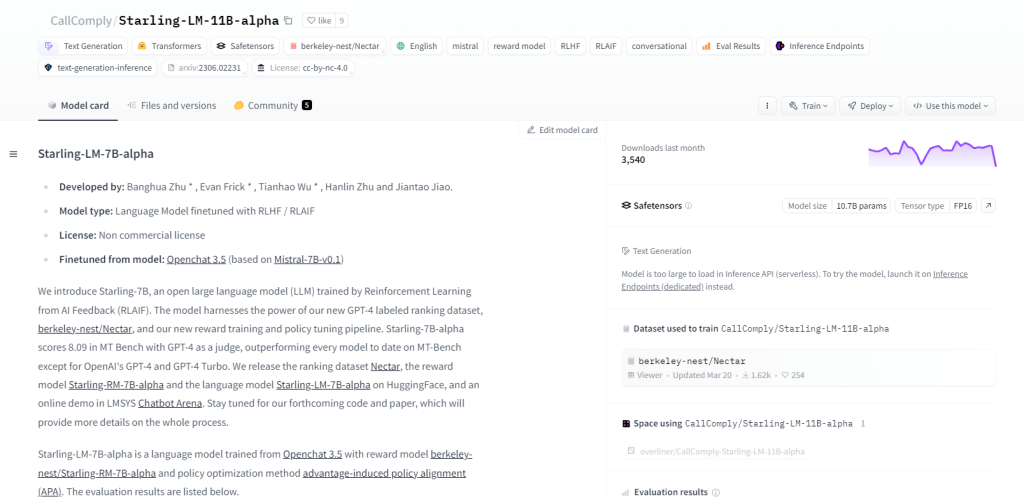
Starling-LM-11B-alpha, um modelo de linguagem grande (LLM) com 11 bilhões de parâmetros, surge do NurtureAI, aproveitando o modelo OpenChat 3.5 como base. O ajuste fino é alcançado por meio do Reinforcement Learning from AI Feedback (RLAIF), guiado por classificações rotuladas por humanos. Este modelo promete remodelar a interação homem-máquina com sua estrutura de código aberto e aplicações versáteis, incluindo tarefas de PNL, pesquisa de aprendizado de máquina, educação e geração de conteúdo criativo.
Características principais
- 11 bilhões de parâmetros
- Desenvolvido por NutriAI
- Baseado no modelo OpenChat 3.5
- Ajustado através do RLAIF
- Classificações rotuladas por humanos para treinamento
- Natureza de código aberto
- Capacidades diversas
- Use para pesquisa, educação e geração de conteúdo criativo
Yi-34B-Lhama
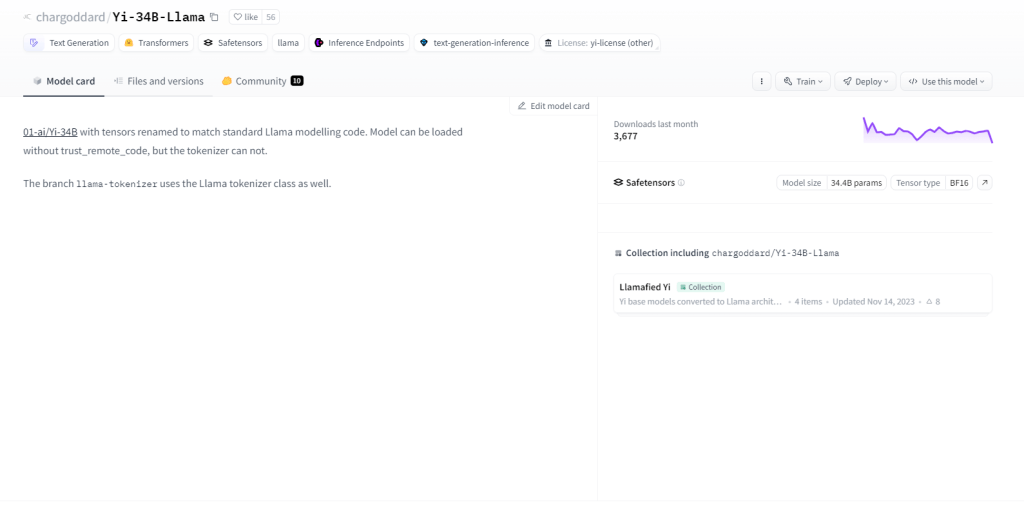
Yi-34B-Llama, com seus 34 bilhões de parâmetros, apresenta capacidade de aprendizagem superior. Ele se destaca no processamento multimodal, manipulando texto, código e imagens com eficiência. Adotando o aprendizado zero-shot, ele se adapta perfeitamente a novas tarefas. Sua natureza com estado permite lembrar interações passadas, aumentando o envolvimento do usuário. Os casos de uso incluem geração de texto, tradução automática, resposta a perguntas, diálogo, geração de código e legenda de imagens.
Características principais
- 34 bilhões de parâmetros
- Processamento multimodal
- Capacidade de aprendizado zero-shot
- Natureza imponente
- Geração de texto
- Maquina de tradução
- Resposta a perguntas
- Legendagem de imagens
Base DeepSeek LLM 67B
DeepSeek LLM 67B Base, um modelo de linguagem grande (LLM) de 67 bilhões de parâmetros, brilha em tarefas de raciocínio, codificação e matemática. Com pontuações excepcionais que ultrapassam GPT-3.5 e Llama2 70B Base, ele se destaca na compreensão e geração de código e demonstra habilidades matemáticas notáveis. Sua natureza de código aberto sob a licença do MIT permite a exploração livre. Os casos de uso abrangem programação, educação, pesquisa, criação de conteúdo, tradução e resposta a perguntas.
Características principais
- Parâmetro de 67 bilhões
- Desempenho excepcional em raciocínio, codificação e matemática
- Pontuação HumanEval Pass@1 de 73,78
- Excelente compreensão e geração de código
- Pontuações altas em GSM8K 0-shot (84,1)
- Supera GPT-3.5 em recursos de linguagem
- Código aberto sob licença do MIT
- Excelente capacidade de contar histórias e criação de conteúdo.
Skote - Svelte Admin e modelo de painel
Marcoroni-7B-v3 é um poderoso modelo generativo multilíngue de 7 bilhões de parâmetros, capaz de diversas tarefas, incluindo geração de texto, tradução de idiomas, criação de conteúdo criativo e resposta a perguntas. Ele se destaca no processamento de texto e código, aproveitando o aprendizado imediato para desempenho rápido de tarefas sem treinamento prévio. De código aberto e sob licença permissiva, Marcoroni-7B-v3 facilita amplo uso e experimentação.
Características principais
- Geração de texto para poemas, códigos, scripts, e-mails e muito mais.
- Tradução automática de alta precisão.
- Criação de chatbots envolventes com conversas naturais.
- Geração de código a partir de descrições em linguagem natural.
- Recursos abrangentes de resposta a perguntas.
- Resumo de textos longos em resumos concisos.
- Paráfrase eficaz, preservando o significado original.
- Análise de sentimento para conteúdo textual.
Empacotando
A coleção de grandes modelos de linguagem do Hugging Face é uma virada de jogo para desenvolvedores, pesquisadores e entusiastas. Esses modelos desempenham um grande papel na expansão dos limites da compreensão e geração da linguagem natural, graças às suas diversas arquiteturas e capacidades. À medida que a tecnologia evolui, as aplicações e o impacto destes modelos são infinitos. A jornada de exploração e inovação com grandes modelos de linguagem é contínua, prometendo desenvolvimentos emocionantes no futuro.








