
Rozwój technologii text-to-video opartej na sztucznej inteligencji rewolucjonizuje sposób, w jaki tworzymy i konsumujemy treści. Na czele tej transformacji stoją potężne modele Hugging Face, które szybko stają się narzędziami dla twórców treści i firm.

Te najnowocześniejsze modele językowe, trenowane na ogromnych zbiorach danych, posiadają niezwykłą zdolność tłumaczenia tekstu pisanego na porywające narracje wizualne. Wykorzystując najnowsze osiągnięcia w zakresie przetwarzania języka naturalnego i generatywnej sztucznej inteligencji, modele Hugging Face mogą bez wysiłku przekształcić Twoje słowa w angażujące, wysokiej jakości filmy, które oczarują Twoją publiczność.
Zrozumienie technologii zamiany tekstu na wideo
Modele text-to-video przekształcają opisy pisemne w ruchome obrazy. Modele te rozumieją tekst i przekształcają go w sekwencję klatek, które przedstawiają opisaną scenę lub akcję. Proces ten obejmuje wiele kroków, w tym analizę tekstu, generowanie treści wizualnych i sekwencjonowanie klatek. Każdy krok wymaga złożonych algorytmów, aby zapewnić, że wideo wyjściowe dokładnie przedstawia tekst wejściowy.
Podróż technologii text-to-video rozpoczęła się od prostych opisów tekstowych generujących podstawowe animacje. Wczesne modele koncentrowały się na tworzeniu statycznych obrazów, ale postęp w dziedzinie sztucznej inteligencji i uczenia maszynowego umożliwił rozwój dynamicznego generowania wideo. Na przestrzeni lat naukowcy zintegrowali zaawansowane sieci neuronowe, co doprowadziło do znacznej poprawy jakości i realizmu wideo. Te postępy otworzyły nowe możliwości kreatywnego tworzenia treści i różnych zastosowań w różnych branżach.
5 najlepszych modeli AI do zamiany tekstu na wideo od Huggingface
Oto 5 najlepszych modeli AI text-to-video od huggingface. Te modele są bardzo popularne ze względu na swoją wyjątkową funkcjonalność i mają najwięcej pobrań.
Zakres modelu - 1.7b
Model syntezy tekstu do wideo z ModelScope wykorzystuje wieloetapowy proces dyfuzji do generowania filmów z opisów tekstowych. Ten zaawansowany model obsługuje tylko dane wejściowe w języku angielskim i jest przeznaczony do celów badawczych. Składa się z trzech podsieci: ekstrakcji cech tekstu, dyfuzji przestrzeni ukrytej tekstu do wideo i mapowania przestrzeni ukrytej wideo do przestrzeni wizualnej.
Z 1,7 miliarda parametrów i strukturą UNet3D, iteracyjnie odszumia szum Gaussa, aby tworzyć filmy. Ten model nadaje się do różnych zastosowań, takich jak tworzenie filmów z dowolnego tekstu w języku angielskim. Ma jednak ograniczenia, takie jak odchylenia od danych treningowych i niemożność tworzenia wysokiej jakości filmów na poziomie filmu lub czystego tekstu. Użytkownicy muszą unikać generowania szkodliwych lub fałszywych treści. Model został wytrenowany na publicznych zestawach danych, w tym LAION5B, ImageNet i Webvid.
Główne cechy
- Wieloetapowy proces dyfuzji
- Obsługa tekstu w języku angielskim
- 1,7 miliarda parametrów
- Architektura UNet3D
- Iteracyjna metoda odszumiania
- Cel badań
- Szkolenie z publicznego zbioru danych
- Generowanie dowolnego tekstu
AnimateDiff-Błyskawica
AnimateDiff-Lightning to najnowocześniejszy model generowania tekstu na wideo, który oferuje poprawę prędkości w porównaniu z oryginalnym AnimateDiff, generując filmy ponad dziesięć razy szybciej. Opracowany na podstawie AnimateDiff SD1.5 v2, ten model jest dostępny w wersjach 1-krokowej, 2-krokowej, 4-krokowej i 8-krokowej, przy czym modele o wyższej liczbie kroków oferują wyższą jakość. Doskonale sprawdza się w połączeniu ze stylizowanymi modelami bazowymi, takimi jak epicCRealism i Realistic Vision, a także modelami anime i kreskówek, takimi jak ToonYou i Mistoon Anime.
Użytkownicy mogą osiągnąć optymalne wyniki, eksperymentując z różnymi ustawieniami, takimi jak Motion LoRAs. Do wdrożenia model można wykorzystać z Diffusers i ComfyUI. Obsługuje generowanie wideo-wideo z ControlNet w celu uzyskania ulepszonego wyniku. Aby uzyskać więcej szczegółów i wersję demonstracyjną, zachęcamy użytkowników do zapoznania się z dokumentem badawczym: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Główne cechy
- Błyskawiczne generowanie wideo
- Wydestylowano z AnimateDiff
- Wieloetapowe punkty kontrolne
- Wysoka jakość generacji
- Obsługuje stylizowane modele
- Obsługa technologii Motion LoRA
- Opcje realistyczne i kreskówkowe
- Generowanie wideo do wideo
Zeroskop V2
Model wideo zeroscope_v2_567w oparty na Modelscope doskonale nadaje się do tworzenia wysokiej jakości filmów 16:9 bez znaków wodnych. Wytrenowany na 9923 klipach i 29 769 oznaczonych klatkach przy rozdzielczości 576x320 i 24 klatkach na sekundę, idealnie nadaje się do płynnego wyjścia wideo. Ten model jest przeznaczony do początkowego renderowania przed skalowaniem w górę za pomocą zeroscope_v2_XL przy użyciu vid2vid w rozszerzeniu 1111 text2video, umożliwiając wydajną eksplorację przy niższych rozdzielczościach.
Skalowanie do 1024x576 zapewnia lepsze kompozycje. Używa 7,9 GB pamięci VRAM do renderowania 30 klatek. Aby użyć, pobierz i zamień pliki w odpowiednim katalogu.
Aby uzyskać najlepsze rezultaty, należy wykonać upscale przy użyciu zeroscope_v2_XL z siłą denoise między 0,66 a 0,85. Znane problemy obejmują suboptymalne wyjście przy niższych rozdzielczościach lub mniejszej liczbie klatek. Model można łatwo zintegrować przy użyciu Diffusers z prostymi krokami instalacji i generowania wideo.
Główne cechy
- Wyjście bez znaku wodnego
- Wysokiej jakości 16:9
- Płynny sygnał wideo
- Rozdzielczość 576x320
- 24 klatki na sekundę
- Efektywne skalowanie
- 7,9 GB wykorzystania pamięci VRAM
- Łatwa integracja
Generacja V
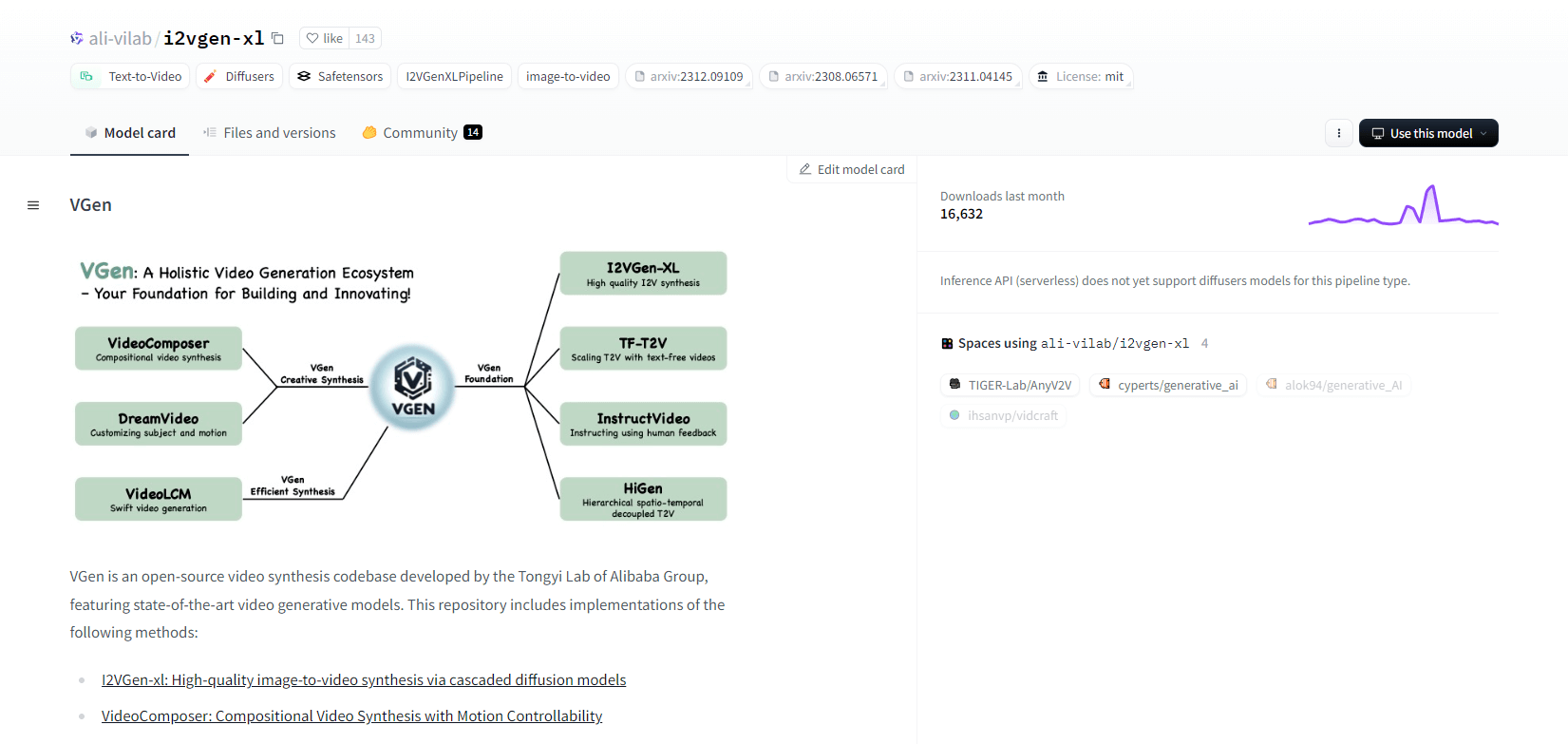
VGen, baza kodu źródłowego do syntezy wideo z otwartym kodem źródłowym od Tongyi Lab firmy Alibaba, oferuje zaawansowane modele generatywne wideo. Obejmuje metody takie jak I2VGen-xl do wysokiej jakości syntezy obrazu do wideo, VideoComposer do syntezy wideo sterowanej ruchem i wiele innych. VGen może tworzyć wysokiej jakości filmy z tekstu, obrazów, pożądanych ruchów, tematów i sygnałów sprzężenia zwrotnego. Repozytorium zawiera narzędzia do wizualizacji, próbkowania, szkolenia, wnioskowania i wspólnego szkolenia przy użyciu obrazów i filmów. Ostatnie aktualizacje obejmują VideoLCM, I2VGen-XL i metodę DreamVideo.
VGen wyróżnia się rozszerzalnością, wydajnością i kompletnością. Instalacja obejmuje skonfigurowanie środowiska Python i niezbędnych bibliotek. Użytkownicy mogą trenować modele text-to-video i uruchamiać I2VGen-XL w celu generowania wideo wysokiej rozdzielczości. Dostępne są zestawy danych demonstracyjnych i wstępnie wytrenowane modele ułatwiające eksperymentowanie i optymalizację. Baza kodu zapewnia łatwe zarządzanie i wysoką wydajność w zadaniach syntezy wideo.
Główne cechy
- Baza kodu źródłowego typu open source
- Synteza wysokiej jakości
- Kontrolowalność ruchu
- Generowanie tekstu na wideo
- Konwersja obrazu na wideo
- Rozszerzalna struktura
- Wstępnie wyszkolone modele
- Kompleksowe narzędzia
Gorący strzał XL
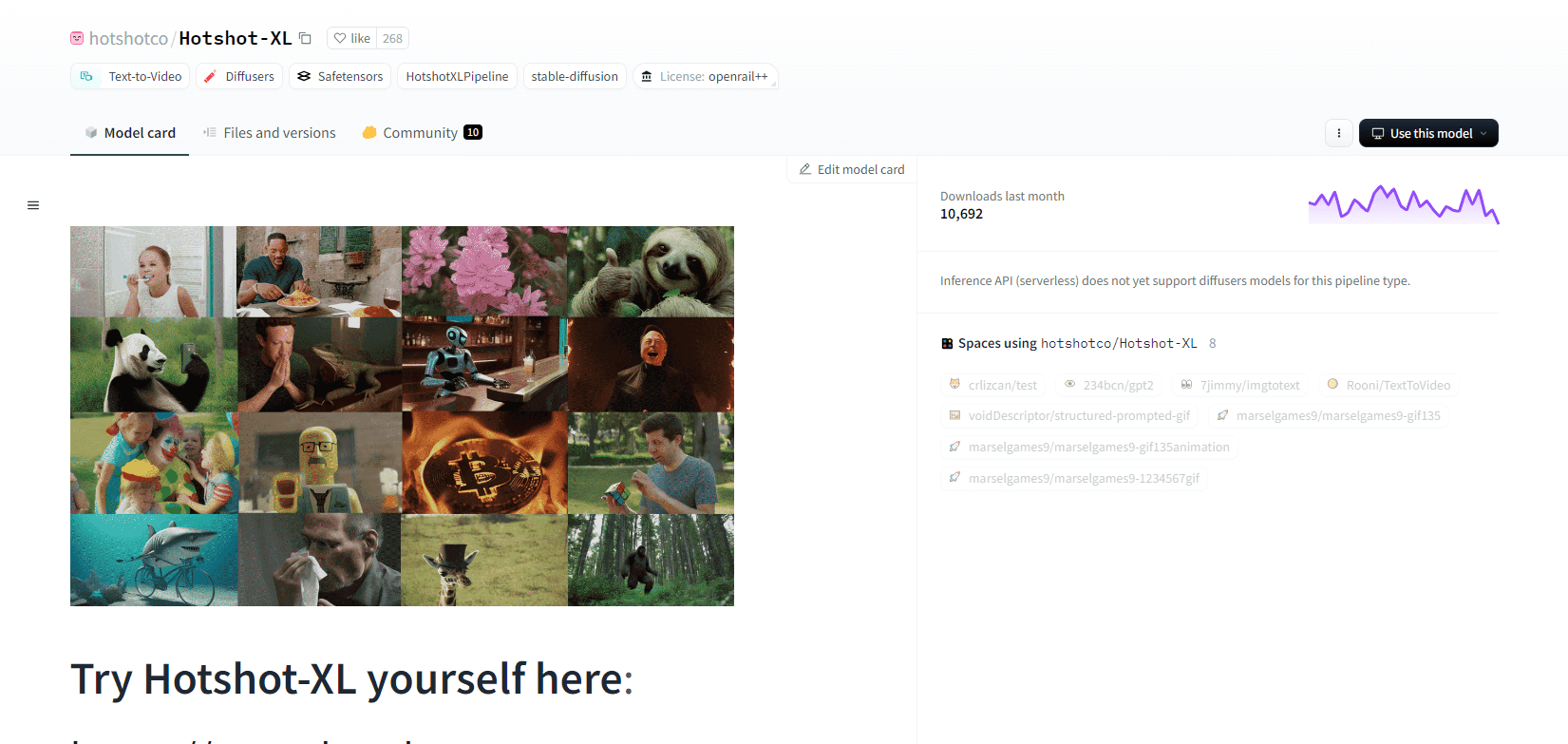
Hotshot-XL, model AI text-to-GIF opracowany przez Natural Synthetics Inc., działa bezproblemowo ze Stable Diffusion XL. Umożliwia generowanie GIF-ów przy użyciu dowolnego dostrojonego modelu SDXL, upraszczając tworzenie spersonalizowanych GIF-ów bez dodatkowego dostrajania. Ten model doskonale radzi sobie z generowaniem 1-sekundowych GIF-ów przy 8 klatkach na sekundę w różnych proporcjach. Wykorzystuje Latent Diffusion z wstępnie wyszkolonymi koderami tekstu (OpenCLIP-ViT/G i CLIP-ViT/L) w celu zwiększenia wydajności.
Użytkownicy mogą modyfikować kompozycje GIF za pomocą SDXL ControlNet w celu uzyskania niestandardowych układów. Hotshot-XL, mimo że jest w stanie tworzyć wszechstronne pliki GIF, stawia czoła wyzwaniom związanym z fotorealizmem i złożonymi zadaniami, takimi jak renderowanie określonych kompozycji. Implementacja modelu ma na celu płynną integrację z istniejącymi przepływami pracy i jest dostępna do eksploracji w GitHub na licencji CreativeML Open RAIL++-M.
Główne cechy
- Generowanie tekstu do GIF-a
- Działa z SDXL
- Generuje 1-sekundowe pliki GIF
- Obsługuje różne współczynniki proporcji
- Wykorzystuje dyfuzję utajoną
- Wstępnie wyszkolone kodery tekstu
- Możliwość dostosowania za pomocą ControlNet
- Dostępne na GitHub
Przyszłe możliwości modeli AI do konwersji tekstu na wideo
Platformy takie jak Hugging Face są liderami w rozwijaniu zaawansowanych modeli, które mogą przekształcać tekst w wysokiej jakości, dynamiczną treść wideo. Prowadzi nas to do założenia, że - przyszłe możliwości modeli AI text-to-video są naprawdę ekscytujące.
Te modele są gotowe zrewolucjonizować tworzenie treści, czyniąc je szybszym, wydajniejszym i bardziej dostępnym niż kiedykolwiek wcześniej. Po prostu wprowadzając tekstowy monit, użytkownicy będą mogli generować angażujące, dostosowane filmy, które ożywią ich pomysły.
Potencjalne zastosowania są ogromne - od marketingu i reklamy po edukację i rozrywkę. Wyobraź sobie, że możesz tworzyć profesjonalne filmy wyjaśniające lub animowane historie za pomocą jednego kliknięcia. Oszczędności czasu i kosztów dla firm i twórców będą znaczne.
Co więcej, w miarę jak te modele text-to-video będą się nadal poprawiać pod względem realizmu, spójności i elastyczności, jakość wyników będzie coraz bardziej nieodróżnialna od wideo tworzonego przez człowieka. Ta demokratyzacja produkcji wideo umożliwi większej liczbie osób dzielenie się swoimi historiami i pomysłami ze światem.
Przyszłość tworzenia treści to niewątpliwie tekst do wideo, a Hugging Face jest na czele tej transformacyjnej technologii. Przygotuj się na zdumienie, gdy te modele przesuną granice tego, co jest możliwe.
Podsumowanie
Podsumowując, Huggingface oferuje zróżnicowany zakres modeli do zadań text-to-video, z których każdy wnosi unikalne mocne strony w generowaniu dynamicznej treści wizualnej z opisów tekstowych. Niezależnie od tego, czy priorytetem jest precyzja, kreatywność czy skalowalność, modele te zapewniają solidne rozwiązania dla różnych aplikacji, obiecując postęp w syntezie wideo opartej na sztucznej inteligencji.







