
Hugging Face is een goudmijn voor iedereen die zich bezighoudt met natuurlijke taalverwerking, boordevol verschillende vooraf getrainde taalmodellen die supergemakkelijk te gebruiken zijn in verschillende toepassingen. Als het gaat om Large Language Models (LLM's), is Hugging Face de beste keuze. In dit stuk duiken we in de top 10 LLM's op Hugging Face, die elk een cruciale rol spelen in het bevorderen van de manier waarop we taal begrijpen en genereren.

Laten we beginnen!
Wat is het grote taalmodel?
Large Language Models (LLM's) zijn geavanceerde vormen van kunstmatige intelligentie die zijn ontworpen om menselijke taal te begrijpen en te genereren. Ze zijn gebouwd met behulp van deep learning-technieken, met name een soort neuraal netwerk dat een transformator wordt genoemd.
Hier is een overzicht om het duidelijk te maken:
- Training over enorme data : LLM's worden getraind in enorme datasets die boeken, artikelen, websites en meer bevatten. Deze uitgebreide training helpt hen de nuances van taal te leren, inclusief grammatica, context en zelfs een bepaald niveau van redeneren.
- Transformers : De architectuur achter de meeste LLM's wordt een transformator genoemd. Dit model maakt gebruik van aandachtsmechanismen om het belang van verschillende woorden in een zin af te wegen, waardoor de context beter kan worden begrepen dan eerdere modellen.
- Taken die ze uitvoeren : Eenmaal getraind kunnen LLM's verschillende taaltaken uitvoeren. Deze omvatten het beantwoorden van vragen, het samenvatten van teksten, het vertalen van talen, het genereren van creatief schrijven en coderen.
- Populaire modellen : Enkele bekende LLM's zijn GPT-3, BERT en T5. Deze vooraf getrainde modellen kunnen worden afgestemd op specifieke taken, waardoor ze veelzijdige hulpmiddelen worden voor ontwikkelaars en onderzoekers.
- Toepassingen : LLM's worden gebruikt in chatbots, virtuele assistenten, geautomatiseerde contentcreatie en nog veel meer. Ze helpen de gebruikersinteracties met technologie te verbeteren door machines de menselijke taal natuurlijker te laten begrijpen en erop te laten reageren.
In wezen zijn grote taalmodellen een soort superkrachtige hersenen voor computers, waardoor ze menselijke taal met indrukwekkende nauwkeurigheid en veelzijdigheid kunnen verwerken en genereren.
KnuffelenFace & LLM
Hugging Face is een bedrijf en een platform dat is uitgegroeid tot een hub voor natuurlijke taalverwerking (NLP) en machine learning. Ze bieden tools, bibliotheken en bronnen om het voor ontwikkelaars en onderzoekers gemakkelijker te maken om machine learning-modellen te bouwen en te gebruiken, vooral als het gaat om het begrijpen en genereren van talen.
Hugging Face staat bekend om zijn open-sourcebibliotheken, vooral Transformers , die gemakkelijke toegang bieden tot een breed scala aan vooraf getrainde taalmodellen.
Hugging Face biedt onderdak aan veel ultramoderne LLM's zoals GPT-3, BERT en T5. Deze modellen zijn vooraf getraind op enorme datasets en zijn klaar om voor verschillende toepassingen te worden gebruikt.
Het platform biedt eenvoudige API’s en tools om deze modellen in applicaties te integreren zonder dat er diepgaande expertise op het gebied van machine learning nodig is.
Met de tools van Hugging Face kunt u deze vooraf getrainde LLM's eenvoudig afstemmen op uw eigen gegevens, zodat u ze kunt aanpassen aan specifieke taken of domeinen.
Onderzoekers en ontwikkelaars kunnen hun modellen en verbeteringen delen op het Hugging Face-platform, waardoor innovatie en toepassing in NLP worden versneld.
Top 5 LLM-modellen op Huggingface die u zou moeten gebruiken
Laten we enkele van de beste LLM-modellen op Hugging Face verkennen die uitblinken in het vertellen van verhalen en zelfs GPT overtreffen.
Mistral-7B-v0.1
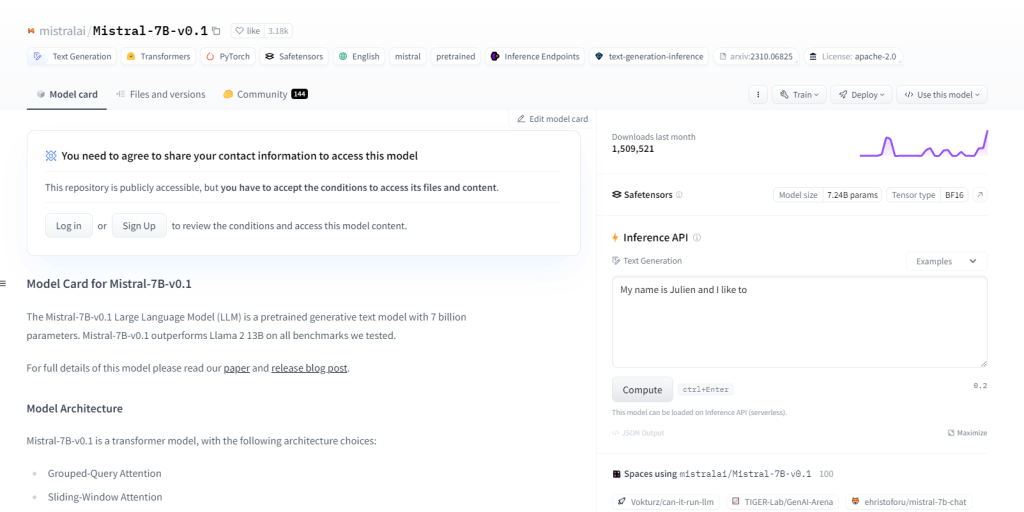
De Mistral-7B-v0.1, een Large Language Model (LLM) met 7 miljard parameters, presteert beter dan benchmarks zoals Llama 2 13B op alle domeinen. Het maakt gebruik van een transformatorarchitectuur met specifieke aandachtsmechanismen en een Byte-fallback BPE-tokenizer. Het blinkt uit in het genereren van tekst, het begrijpen van natuurlijke talen en het vertalen van talen, en dient als basismodel voor onderzoek en ontwikkeling in NLP-projecten.
Belangrijkste kenmerken
- 7 miljard parameters
- Overtreft benchmarks zoals Llama 213B
- Transformator-architectuur
- BPE-tokenizer
- NLP-projectontwikkeling
- Natuurlijk taalbegrip
- Taal vertaling
- Gegroepeerde query-aandacht
Starling-LM-11B-alpha
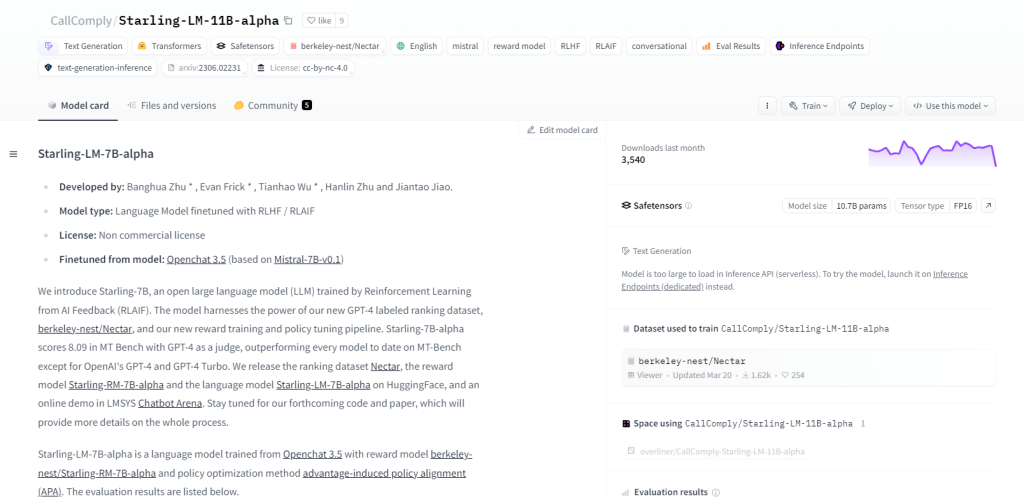
Starling-LM-11B-alpha, een groot taalmodel (LLM) met 11 miljard parameters, komt voort uit NurtureAI en maakt gebruik van het OpenChat 3.5-model als basis. Verfijning wordt bereikt door middel van Reinforcement Learning from AI Feedback (RLAIF), geleid door door mensen gelabelde ranglijsten. Dit model belooft de mens-machine-interactie opnieuw vorm te geven met zijn open-source raamwerk en veelzijdige toepassingen, waaronder NLP-taken, onderzoek naar machinaal leren, onderwijs en het genereren van creatieve inhoud.
Belangrijkste kenmerken
- 11 miljard parameters
- Ontwikkeld door NurtureAI
- Gebaseerd op het OpenChat 3.5-model
- Verfijnd via RLAIF
- Door mensen gelabelde ranglijsten voor training
- Open source-karakter
- Diverse mogelijkheden
- Gebruik voor onderzoek, onderwijs en het genereren van creatieve inhoud
Yi-34B-lama
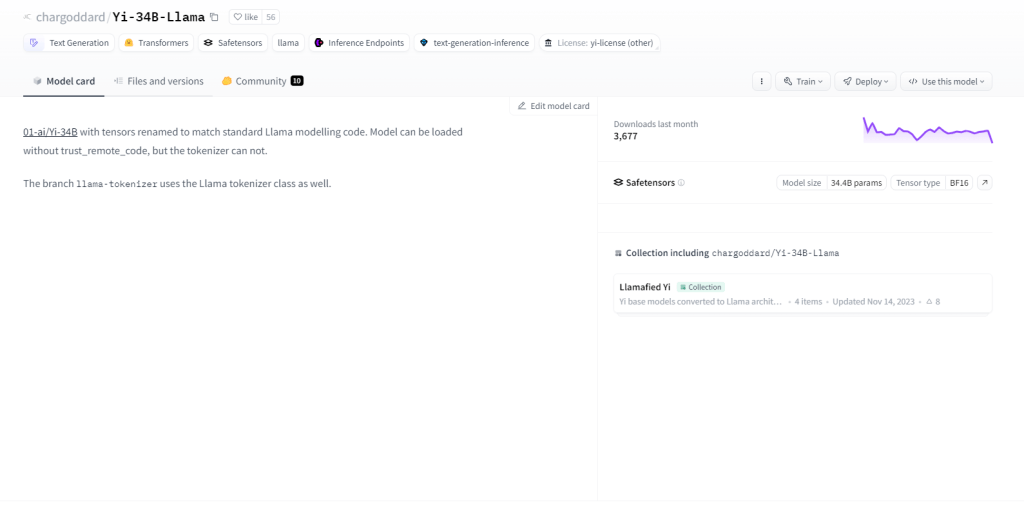
Yi-34B-Llama toont met zijn 34 miljard parameters een superieur leervermogen. Het blinkt uit in multimodale verwerking, waarbij tekst, code en afbeeldingen efficiënt worden verwerkt. Het omarmt zero-shot learning en past zich naadloos aan nieuwe taken aan. Dankzij het stateful karakter kan het eerdere interacties onthouden, waardoor de betrokkenheid van gebruikers wordt vergroot. Gebruiksscenario's omvatten het genereren van tekst, automatische vertaling, het beantwoorden van vragen, dialoog, het genereren van code en het ondertitelen van afbeeldingen.
Belangrijkste kenmerken
- 34 miljard parameters
- Multimodale verwerking
- Zero-shot-leervermogen
- Statelijke aard
- Tekst genereren
- Machine vertaling
- Vraag beantwoorden
- Ondertiteling van afbeeldingen
DeepSeek LLM 67B-basis
DeepSeek LLM 67B Base, een groot taalmodel (LLM) met 67 miljard parameters, blinkt uit in redeneer-, codeer- en wiskundige taken. Met uitzonderlijke scores die de GPT-3.5 en Llama2 70B Base overtreffen, blinkt het uit in het begrijpen en genereren van code en demonstreert het opmerkelijke wiskundige vaardigheden. Het open-source karakter ervan onder de MIT-licentie maakt gratis onderzoek mogelijk. Use cases omvatten programmeren, onderwijs, onderzoek, het creëren van inhoud, vertaling en het beantwoorden van vragen.
Belangrijkste kenmerken
- 67 miljard parameters
- Uitzonderlijke prestaties op het gebied van redeneren, coderen en wiskunde
- HumanEval Pass@1-score van 73,78
- Uitstekend begrip en generatie van code
- Hoge scores op GSM8K 0-shot (84,1)
- Overtreft GPT-3.5 in taalmogelijkheden
- Open source onder de MIT-licentie
- Uitstekende mogelijkheden voor het vertellen van verhalen en het creëren van inhoud.
Skote - Svelte beheerders- en dashboardsjabloon
Marcoroni-7B-v3 is een krachtig meertalig generatief model met 7 miljard parameters dat diverse taken kan uitvoeren, waaronder het genereren van tekst, taalvertaling, het maken van creatieve inhoud en het beantwoorden van vragen. Het blinkt uit in het verwerken van zowel tekst als code, waarbij gebruik wordt gemaakt van zero-shot learning voor snelle taakuitvoering zonder voorafgaande training. Open-source en onder een permissieve licentie vergemakkelijkt Marcoroni-7B-v3 breed gebruik en experimenten.
Belangrijkste kenmerken
- Tekstgeneratie voor gedichten, code, scripts, e-mails en meer.
- Zeer nauwkeurige machinevertaling.
- Creatie van boeiende chatbots met natuurlijke gesprekken.
- Codegeneratie op basis van natuurlijke taalbeschrijvingen.
- Uitgebreide vraag-antwoordmogelijkheden.
- Samenvatten van lange teksten in beknopte samenvattingen.
- Effectief parafraseren met behoud van de oorspronkelijke betekenis.
- Sentimentanalyse voor tekstuele inhoud.
Afsluiten
De verzameling grote taalmodellen van Hugging Face is een game-changer voor zowel ontwikkelaars, onderzoekers als enthousiastelingen. Deze modellen spelen een grote rol bij het verleggen van de grenzen van het begrijpen en genereren van natuurlijke taal, dankzij hun uiteenlopende architecturen en mogelijkheden. Naarmate de technologie evolueert, zijn de toepassingen en impact van deze modellen eindeloos. De reis van verkennen en innoveren met grote taalmodellen gaat door en belooft spannende ontwikkelingen in het verschiet.







