
De opkomst van AI-aangedreven tekst-naar-videotechnologie zorgt voor een revolutie in de manier waarop we content creëren en consumeren. De krachtige Hugging Face-modellen staan voorop in deze transformatie en worden snel de go-to tools voor zowel contentmakers als bedrijven.

Deze state-of-the-art taalmodellen, getraind op enorme hoeveelheden data, bezitten het opmerkelijke vermogen om geschreven tekst te vertalen naar boeiende visuele verhalen. Door gebruik te maken van de nieuwste ontwikkelingen in natuurlijke taalverwerking en generatieve AI, kunnen Hugging Face-modellen moeiteloos uw woorden omzetten in boeiende, hoogwaardige video's die uw publiek boeien.
Begrijpen van tekst-naar-videotechnologie
Tekst-naar-videomodellen transformeren geschreven beschrijvingen in bewegende beelden. Deze modellen begrijpen tekst en zetten deze om in een reeks frames die de beschreven scène of actie weergeven. Dit proces omvat meerdere stappen, waaronder tekstanalyse, visuele contentgeneratie en framesequentie. Elke stap vereist complexe algoritmen om ervoor te zorgen dat de uitvoervideo de invoertekst nauwkeurig weergeeft.
De reis van tekst-naar-videotechnologie begon met eenvoudige tekstbeschrijvingen die basisanimaties genereerden. Vroege modellen waren gericht op het maken van statische afbeeldingen, maar vooruitgang in AI en machine learning hebben de ontwikkeling van dynamische videogeneratie mogelijk gemaakt. In de loop der jaren hebben onderzoekers geavanceerde neurale netwerken geïntegreerd, wat heeft geleid tot aanzienlijke verbeteringen in videokwaliteit en realisme. Deze vooruitgang heeft nieuwe mogelijkheden geopend voor creatieve contentcreatie en verschillende toepassingen in verschillende sectoren.
5 beste tekst-naar-video-AI-modellen van Huggingface
Hier hebben we de 5 beste AI tekst-naar-video modellen van huggingface. Deze modellen zijn erg populair vanwege hun onderscheidende functionaliteit en hebben de meeste downloads.
ModelScope - 1.7b
Het tekst-naar-video synthesemodel van ModelScope gebruikt een meertraps diffusieproces om video's te genereren uit tekstbeschrijvingen. Dit geavanceerde model ondersteunt alleen Engelse invoer en is ontworpen voor onderzoeksdoeleinden. Het bestaat uit drie subnetwerken: tekstkenmerkextractie, tekst-naar-video latente ruimte diffusie en video latente ruimte naar visuele ruimte mapping.
Met 1,7 miljard parameters en een UNet3D-structuur, verwijdert het iteratief Gaussische ruis om video's te maken. Dit model is geschikt voor verschillende toepassingen, zoals het maken van video's van willekeurige Engelse tekst. Het heeft echter beperkingen, zoals vooroordelen van trainingsdata en een onvermogen om hoogwaardige filmvideo's of duidelijke tekst te produceren. Gebruikers moeten voorkomen dat ze schadelijke of valse content genereren. Het model is getraind op openbare datasets, waaronder LAION5B, ImageNet en Webvid.
Belangrijkste kenmerken
- Meertraps diffusieproces
- Ondersteuning voor Engelse tekst
- 1,7 miljard parameters
- UNet3D-architectuur
- Iteratieve ruisverwijderingsmethode
- Onderzoeksdoelstelling focus
- Openbare datasettraining
- Willekeurige tekstgeneratie
AnimateDiff-Bliksem
AnimateDiff-Lightning is een geavanceerd tekst-naar-video generatiemodel dat snelheidsverbeteringen biedt ten opzichte van de originele AnimateDiff, en video's meer dan tien keer sneller genereert. Dit model is ontwikkeld op basis van AnimateDiff SD1.5 v2 en is beschikbaar in 1-staps, 2-staps, 4-staps en 8-staps versies, waarbij modellen met hogere stappen superieure kwaliteit bieden. Het blinkt uit in gebruik met gestileerde basismodellen zoals epiCRealism en Realistic Vision, evenals anime- en cartoonmodellen zoals ToonYou en Mistoon Anime.
Gebruikers kunnen optimale resultaten bereiken door te experimenteren met verschillende instellingen, zoals het gebruik van Motion LoRA's. Voor implementatie kan het model worden gebruikt met Diffusers en ComfyUI. Het ondersteunt video-naar-videogeneratie met ControlNet voor verbeterde output. Voor meer details en een demo worden gebruikers aangemoedigd om het onderzoeksartikel te raadplegen: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Belangrijkste kenmerken
- Razendsnelle videogeneratie
- Gedestilleerd uit AnimateDiff
- Controlepunten met meerdere stappen
- Hoge generatiekwaliteit
- Ondersteunt gestileerde modellen
- Ondersteuning voor Motion LoRAs
- Realistische en cartoonopties
- Video-naar-video-generatie
Zeroscoop V2
Het op Modelscope gebaseerde zeroscope_v2_567w videomodel excelleert in het maken van hoogwaardige 16:9 video's zonder watermerken. Getraind op 9.923 clips en 29.769 getagde frames met een resolutie van 576x320 en 24 frames per seconde, is het ideaal voor vloeiende video-uitvoer. Dit model is ontworpen voor initiële rendering vóór upscaling met zeroscope_v2_XL met behulp van vid2vid in de 1111 text2video-extensie, wat efficiënte verkenning bij lagere resoluties mogelijk maakt.
Upscaling naar 1024x576 levert superieure composities op. Het gebruikt 7,9 GB VRAM voor het renderen van 30 frames. Om te gebruiken, download en vervang bestanden in de juiste directory.
Voor de beste resultaten, upscale met zeroscope_v2_XL met een denoise-sterkte tussen 0,66 en 0,85. Bekende problemen zijn onder andere suboptimale output bij lagere resoluties of minder frames. Het model kan eenvoudig worden geïntegreerd met behulp van Diffusers met eenvoudige installatie- en videogeneratiestappen.
Belangrijkste kenmerken
- Watermerkvrije uitvoer
- Hoge kwaliteit 16:9
- Soepele video-uitvoer
- Resolutie van 576x320
- 24 beelden per seconde
- Efficiënte opschaling
- 7,9 GB VRAM-gebruik
- Eenvoudige integratie
VGen
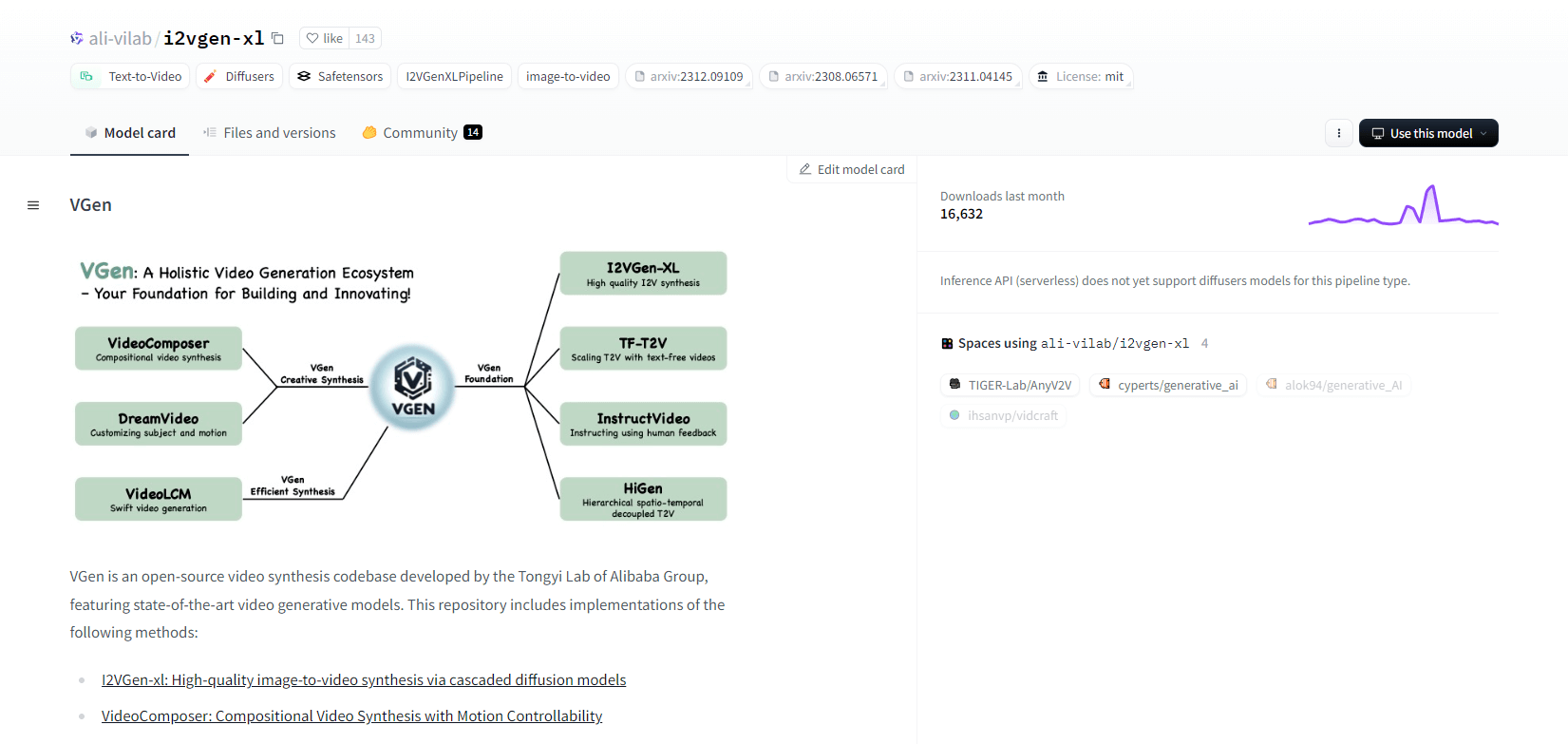
VGen, een open-source videosynthesecodebase van Alibaba's Tongyi Lab, biedt geavanceerde videogeneratiemodellen. Het omvat methoden zoals I2VGen-xl voor hoogwaardige beeld-naar-videosynthese, VideoComposer voor bewegingsgestuurde videosynthese en meer. VGen kan hoogwaardige video's maken van tekst, afbeeldingen, gewenste bewegingen, onderwerpen en feedbacksignalen. De repository bevat hulpmiddelen voor visualisatie, bemonstering, training, gevolgtrekking en gezamenlijke training met behulp van afbeeldingen en video's. Recente updates omvatten VideoLCM, I2VGen-XL en de DreamVideo-methode.
VGen blinkt uit in uitbreidbaarheid, prestaties en volledigheid. Installatie omvat het opzetten van een Python-omgeving en de benodigde bibliotheken. Gebruikers kunnen tekst-naar-videomodellen trainen en I2VGen-XL uitvoeren voor het genereren van high-definition video. Demodatasets en vooraf getrainde modellen zijn beschikbaar om experimenten en optimalisatie te vergemakkelijken. De codebase zorgt voor eenvoudig beheer en hoge efficiëntie in videosynthesetaken.
Belangrijkste kenmerken
- Open-source codebase
- Hoogwaardige synthese
- Bewegingsregelbaarheid
- Tekst-naar-video-generatie
- Conversie van afbeelding naar video
- Uitbreidbaar raamwerk
- Vooraf getrainde modellen
- Uitgebreide tools
Hotshot XL
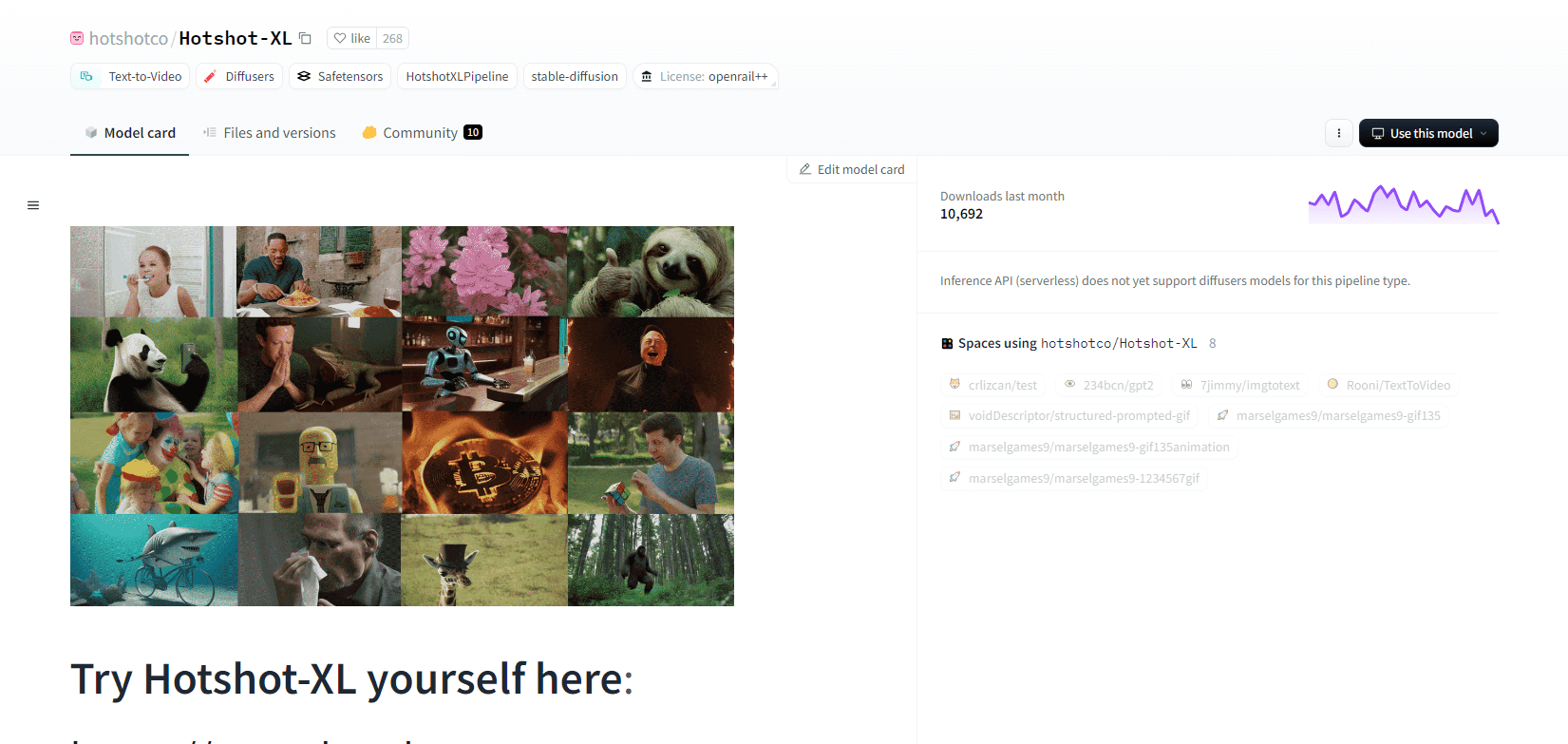
Hotshot-XL, een AI-tekst-naar-GIF-model ontwikkeld door Natural Synthetics Inc., werkt naadloos met Stable Diffusion XL. Het maakt GIF-generatie mogelijk met elk nauwkeurig afgestemd SDXL-model, waardoor het maken van gepersonaliseerde GIF's wordt vereenvoudigd zonder extra fijnafstemming. Dit model blinkt uit in het genereren van 1-seconde GIF's met 8 frames per seconde over verschillende beeldverhoudingen. Het maakt gebruik van Latent Diffusion met vooraf getrainde tekst-encoders (OpenCLIP-ViT/G en CLIP-ViT/L) voor verbeterde prestaties.
Gebruikers kunnen GIF-composities aanpassen met SDXL ControlNet voor aangepaste lay-outs. Hoewel Hotshot-XL veelzijdige GIF-creaties kan maken, kampt het met uitdagingen op het gebied van fotorealisme en complexe taken zoals het renderen van specifieke composities. De implementatie van het model is gericht op soepele integratie in bestaande workflows en is beschikbaar voor verkenning op GitHub onder een CreativeML Open RAIL++-M-licentie.
Belangrijkste kenmerken
- Tekst-naar-GIF-generatie
- Werkt met SDXL
- Genereert GIF's van 1 seconde
- Ondersteunt verschillende beeldverhoudingen
- Maakt gebruik van latente diffusie
- Vooraf getrainde tekst-encoders
- Aanpasbaar met ControlNet
- Beschikbaar op GitHub
Toekomstige mogelijkheden van tekst-naar-video-AI-modellen
Platformen zoals Hugging Face lopen voorop in de ontwikkeling van geavanceerde modellen die tekst kunnen omzetten in hoogwaardige, dynamische videocontent. Dit leidt ons tot de aanname dat - de toekomstige mogelijkheden van tekst-naar-video AI-modellen echt spannend zijn.
Deze modellen zijn klaar om contentcreatie te revolutioneren, waardoor het sneller, efficiënter en toegankelijker wordt dan ooit tevoren. Door simpelweg een tekstprompt in te voeren, kunnen gebruikers boeiende, aangepaste video's genereren die hun ideeën tot leven brengen.
De potentiële toepassingen zijn enorm - van marketing en reclame tot educatie en entertainment. Stel je voor dat je professionele uitlegvideo's of geanimeerde verhalen kunt maken met één druk op de knop. De tijd- en kostenbesparing voor bedrijven en makers zal aanzienlijk zijn.
Bovendien, naarmate deze tekst-naar-videomodellen blijven verbeteren in termen van realisme, coherentie en flexibiliteit, zal de kwaliteit van de output steeds minder te onderscheiden zijn van door mensen gemaakte video. Deze democratisering van videoproductie zal meer mensen in staat stellen hun verhalen en ideeën met de wereld te delen.
De toekomst van contentcreatie is ongetwijfeld tekst-naar-video, en Hugging Face staat voorop in deze transformatieve technologie. Bereid je voor om versteld te staan als deze modellen de grenzen van wat mogelijk is verleggen.
Afronden
Concluderend biedt Huggingface een divers scala aan modellen voor tekst-naar-video-taken, die elk unieke sterke punten bieden bij het genereren van dynamische visuele content uit tekstuele beschrijvingen. Of u nu prioriteit geeft aan precisie, creativiteit of schaalbaarheid, deze modellen bieden robuuste oplossingen voor verschillende toepassingen en beloven vooruitgang in AI-gestuurde videosynthese.







