
AI 기반 텍스트-비디오 기술의 부상은 우리가 콘텐츠를 만들고 소비하는 방식에 혁명을 일으키고 있습니다. 이러한 변화의 최전선에는 강력한 Hugging Face 모델이 있으며, 이는 콘텐츠 제작자와 기업 모두에게 필수적인 도구가 되어 가고 있습니다.

방대한 양의 데이터로 훈련된 이 최첨단 언어 모델은 쓰여진 텍스트를 매혹적인 시각적 내러티브로 번역하는 놀라운 능력을 보유하고 있습니다. 자연어 처리 및 생성 AI의 최신 발전을 활용하여 Hugging Face 모델은 귀하의 단어를 청중을 사로잡는 매력적이고 고품질의 비디오로 손쉽게 변환할 수 있습니다.
텍스트-비디오 기술 이해
텍스트-비디오 모델은 서면 설명을 움직이는 이미지로 변환합니다. 이러한 모델은 텍스트를 이해하고 설명된 장면이나 동작을 묘사하는 프레임 시퀀스로 변환합니다. 이 프로세스에는 텍스트 분석, 시각적 콘텐츠 생성, 프레임 시퀀싱을 포함한 여러 단계가 포함됩니다. 각 단계에는 출력 비디오가 입력 텍스트를 정확하게 나타내도록 하는 복잡한 알고리즘이 필요합니다.
텍스트-비디오 기술의 여정은 기본 애니메이션을 생성하는 간단한 텍스트 설명으로 시작되었습니다. 초기 모델은 정적 이미지를 만드는 데 중점을 두었지만 AI와 머신 러닝의 발전으로 동적 비디오 생성이 가능해졌습니다. 수년에 걸쳐 연구자들은 정교한 신경망을 통합하여 비디오 품질과 사실성이 크게 향상되었습니다. 이러한 발전은 산업 전반에 걸쳐 창의적인 콘텐츠 제작과 다양한 응용 분야에 새로운 가능성을 열었습니다.
Huggingface의 5가지 최고의 텍스트-비디오 AI 모델
여기 huggingface의 5가지 최고의 AI 텍스트-비디오 모델이 있습니다. 이 모델들은 독특한 기능으로 인해 매우 인기가 많고 다운로드 수가 가장 많습니다.
모델스코프 - 1.7b
ModelScope의 텍스트-비디오 합성 모델은 다단계 확산 프로세스를 사용하여 텍스트 설명에서 비디오를 생성합니다. 이 고급 모델은 영어 입력만 지원하며 연구 목적으로 설계되었습니다. 텍스트 피처 추출, 텍스트-비디오 잠재 공간 확산, 비디오 잠재 공간에서 시각 공간 매핑의 세 가지 하위 네트워크로 구성됩니다.
17억 개의 매개변수와 UNet3D 구조를 사용하여 반복적으로 가우시안 노이즈를 제거하여 비디오를 만듭니다. 이 모델은 임의의 영어 텍스트에서 비디오를 만드는 것과 같은 다양한 응용 프로그램에 적합합니다. 그러나 훈련 데이터의 편향 및 고품질 필름 수준 비디오나 일반 텍스트를 생성할 수 없는 것과 같은 한계가 있습니다. 사용자는 유해하거나 거짓된 콘텐츠를 생성하지 않아야 합니다. 이 모델은 LAION5B, ImageNet, Webvid를 포함한 공개 데이터 세트에서 훈련되었습니다.
주요 특징
- 다단계 확산 공정
- 영어 텍스트 지원
- 17억개의 매개변수
- UNet3D 아키텍처
- 반복적 노이즈 제거 방법
- 연구 목적 초점
- 공개 데이터 세트 교육
- 임의의 텍스트 생성
AnimateDiff-Lightning
AnimateDiff-Lightning은 원래 AnimateDiff보다 속도가 향상된 최첨단 텍스트-비디오 생성 모델로, 10배 이상 빠르게 비디오를 생성합니다. AnimateDiff SD1.5 v2에서 개발된 이 모델은 1단계, 2단계, 4단계 및 8단계 버전으로 제공되며, 더 높은 단계 모델은 뛰어난 품질을 제공합니다. epiCRealism 및 Realistic Vision과 같은 양식화된 기본 모델과 ToonYou 및 Mistoon Anime과 같은 애니메이션 및 만화 모델과 함께 사용하면 탁월합니다.
사용자는 Motion LoRA를 사용하는 것과 같은 다양한 설정을 실험하여 최적의 결과를 얻을 수 있습니다. 구현을 위해 이 모델은 Diffusers 및 ComfyUI와 함께 사용할 수 있습니다. 향상된 출력을 위해 ControlNet을 사용하여 비디오 대 비디오 생성을 지원합니다. 자세한 내용과 데모를 보려면 사용자는 연구 논문 AnimateDiff-Lightning: Cross-Model Diffusion Distillation을 참조하는 것이 좋습니다.
주요 특징
- 번개처럼 빠른 비디오 생성
- AnimateDiff에서 추출
- 여러 단계의 체크포인트
- 고품질 세대
- 스타일화된 모델 지원
- 모션 LoRA 지원
- 현실적이고 만화적인 옵션
- 비디오-비디오 생성
제로스코프 V2
Modelscope 기반 zeroscope_v2_567w 비디오 모델은 워터마크 없이 고품질 16:9 비디오를 만드는 데 탁월합니다. 576x320 해상도와 초당 24프레임으로 9,923개 클립과 29,769개 태그 프레임에서 학습되었으며, 매끄러운 비디오 출력에 이상적입니다. 이 모델은 1111 text2video 확장에서 vid2vid를 사용하여 zeroscope_v2_XL로 업스케일링하기 전에 초기 렌더링을 위해 설계되어 낮은 해상도에서 효율적인 탐색이 가능합니다.
1024x576으로 업스케일링하면 뛰어난 구성이 제공됩니다. 30개 프레임을 렌더링하는 데 7.9GB의 VRAM을 사용합니다. 사용하려면 적절한 디렉토리에서 파일을 다운로드하고 교체하세요.
최상의 결과를 위해 0.66~0.85 사이의 노이즈 제거 강도로 zeroscope_v2_XL을 사용하여 업스케일합니다. 알려진 문제로는 낮은 해상도 또는 더 적은 프레임에서 최적이 아닌 출력이 있습니다. 이 모델은 간단한 설치 및 비디오 생성 단계를 통해 Diffusers를 사용하여 쉽게 통합할 수 있습니다.
주요 특징
- 워터마크 없는 출력
- 고품질 16:9
- 부드러운 비디오 출력
- 576x320 해상도
- 초당 24프레임
- 효율적인 업스케일링
- 7.9GB VRAM 사용량
- 쉬운 통합
VGen
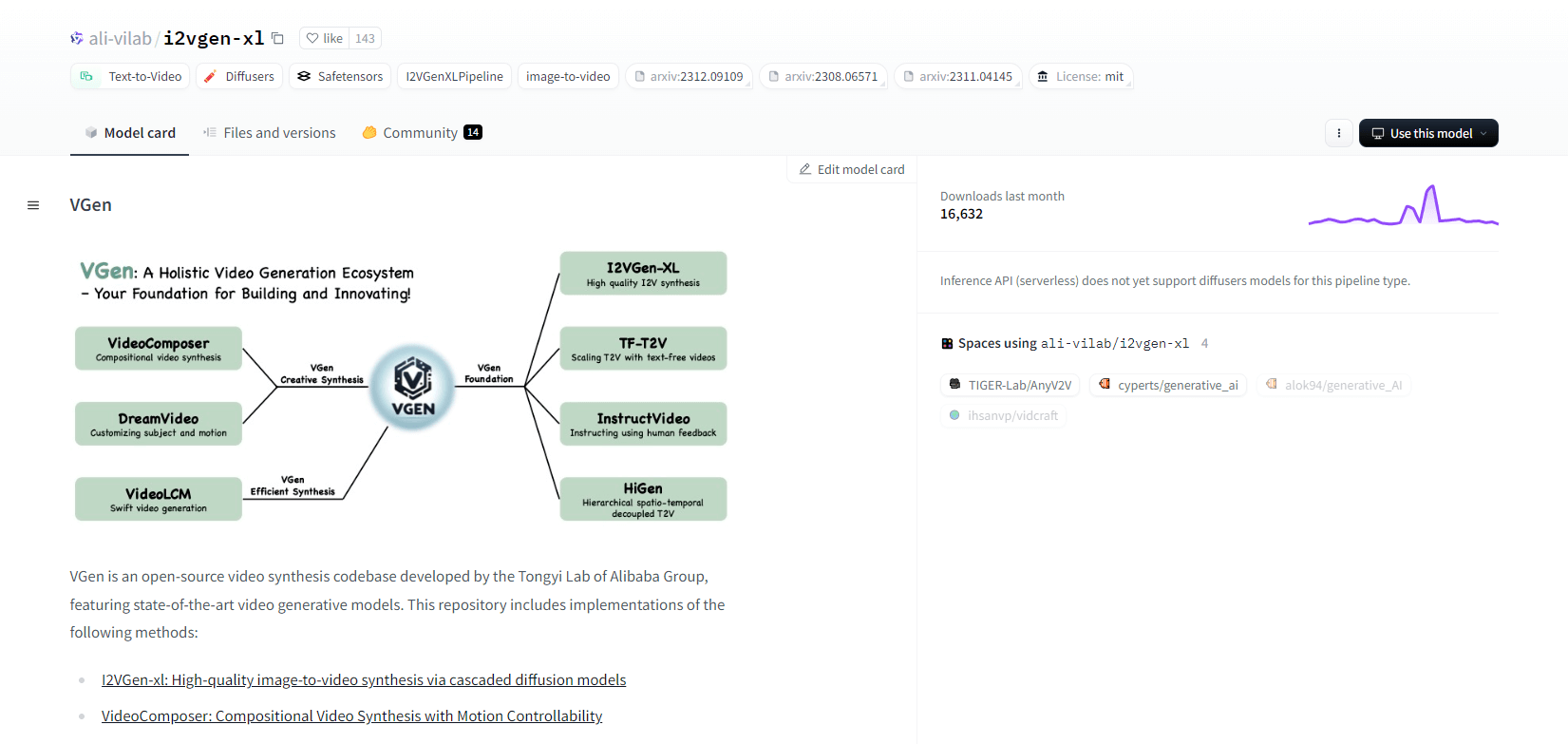
Alibaba의 Tongyi Lab의 오픈소스 비디오 합성 코드베이스인 VGen은 고급 비디오 생성 모델을 제공합니다. 여기에는 고품질 이미지-비디오 합성을 위한 I2VGen-xl, 동작 제어 가능한 비디오 합성을 위한 VideoComposer 등의 방법이 포함됩니다. VGen은 텍스트, 이미지, 원하는 동작, 피사체 및 피드백 신호로부터 고품질 비디오를 만들 수 있습니다. 이 저장소에는 이미지와 비디오를 사용한 시각화, 샘플링, 훈련, 추론 및 공동 훈련을 위한 도구가 있습니다. 최근 업데이트에는 VideoLCM, I2VGen-XL 및 DreamVideo 방법이 포함됩니다.
VGen은 확장성, 성능 및 완전성에서 뛰어납니다. 설치에는 Python 환경과 필요한 라이브러리를 설정하는 것이 포함됩니다. 사용자는 텍스트-비디오 모델을 훈련하고 고화질 비디오 생성을 위해 I2VGen-XL을 실행할 수 있습니다. 실험과 최적화를 용이하게 하기 위해 데모 데이터 세트와 사전 훈련된 모델을 사용할 수 있습니다. 코드베이스는 비디오 합성 작업에서 쉬운 관리와 높은 효율성을 보장합니다.
주요 특징
- 오픈소스 코드베이스
- 고품질 합성
- 동작 제어성
- 텍스트-비디오 생성
- 이미지-비디오 변환
- 확장 가능한 프레임워크
- 사전 훈련된 모델
- 포괄적인 도구
핫샷 XL
Natural Synthetics Inc.에서 개발한 AI 텍스트-GIF 모델인 Hotshot-XL은 Stable Diffusion XL과 원활하게 작동합니다. 미세 조정된 모든 SDXL 모델을 사용하여 GIF를 생성할 수 있으므로 추가 미세 조정 없이 개인화된 GIF를 만드는 것이 간소화됩니다. 이 모델은 다양한 종횡비에서 초당 8프레임으로 1초 GIF를 생성하는 데 탁월합니다. 사전 훈련된 텍스트 인코더(OpenCLIP-ViT/G 및 CLIP-ViT/L)를 사용하여 Latent Diffusion을 활용하여 성능을 향상시킵니다.
사용자는 SDXL ControlNet을 사용하여 사용자 지정 레이아웃을 위해 GIF 구성을 수정할 수 있습니다. Hotshot-XL은 다양한 GIF를 생성할 수 있지만, 포토리얼리즘과 특정 구성을 렌더링하는 것과 같은 복잡한 작업에서 어려움을 겪습니다. 이 모델의 구현은 기존 워크플로에 원활하게 통합하는 것을 목표로 하며 CreativeML Open RAIL++-M 라이선스에 따라 GitHub에서 탐색할 수 있습니다.
주요 특징
- 텍스트-GIF 생성
- SDXL과 함께 작동
- 1초 GIF 생성
- 다양한 종횡비 지원
- 잠복 확산을 사용합니다
- 사전 훈련된 텍스트 인코더
- ControlNet으로 사용자 정의 가능
- GitHub에서 사용 가능
텍스트-비디오 AI 모델의 미래 역량
Hugging Face와 같은 플랫폼은 텍스트를 고품질의 동적 비디오 콘텐츠로 변환할 수 있는 고급 모델을 개발하는 데 앞장서고 있습니다. 이는 텍스트-비디오 AI 모델의 미래 역량이 정말 흥미진진하다는 가정으로 이어집니다.
이러한 모델은 콘텐츠 제작에 혁명을 일으켜 그 어느 때보다 더 빠르고, 더 효율적이며, 더 쉽게 접근할 수 있도록 합니다. 사용자는 텍스트 프롬프트를 입력하기만 하면 아이디어를 현실로 만들어주는 매력적이고 맞춤화된 비디오를 제작할 수 있습니다.
잠재적인 응용 분야는 마케팅과 광고부터 교육과 엔터테인먼트까지 광범위합니다. 버튼 하나만 클릭하면 전문가 수준의 설명 비디오나 애니메이션 스토리를 만들 수 있다고 상상해보세요. 기업과 크리에이터의 시간 및 비용 절감은 상당할 것입니다.
게다가 이러한 텍스트-비디오 모델이 사실성, 일관성, 유연성 측면에서 지속적으로 개선됨에 따라 출력 품질은 인간이 만든 비디오와 점점 더 구별하기 어려워질 것입니다. 이러한 비디오 제작의 민주화는 더 많은 사람들이 자신의 이야기와 아이디어를 세상과 공유할 수 있도록 해줄 것입니다.
콘텐츠 제작의 미래는 의심할 여지 없이 텍스트-비디오이며, Hugging Face는 이 혁신적인 기술의 최전선에 있습니다. 이러한 모델이 가능성의 경계를 넓히는 모습을 보고 놀라실 준비를 하세요.
마무리하기
결론적으로, Huggingface는 텍스트-비디오 작업을 위한 다양한 모델을 제공하며, 각각 텍스트 설명에서 동적 시각적 콘텐츠를 생성하는 데 고유한 강점을 제공합니다. 정밀도, 창의성 또는 확장성을 우선시하든 이러한 모델은 다양한 애플리케이션에 대한 강력한 솔루션을 제공하여 AI 기반 비디오 합성의 발전을 약속합니다.







