
Hugging Face は、自然言語処理に携わる人にとっては金鉱です。さまざまなアプリケーションで非常に簡単に使用できる、さまざまな事前トレーニング済みの言語モデルが満載です。大規模言語モデル (LLM) に関しては、Hugging Face が最有力候補です。この記事では、Hugging Face の上位 10 の LLM について詳しく説明します。各 LLM は、言語の理解と生成の進化に重要な役割を果たしています。

始めましょう!
大規模言語モデルとは何ですか?
大規模言語モデル (LLM) は、人間の言語を理解して生成するように設計された高度なタイプの人工知能です。これらは、ディープラーニング技術、特にトランスフォーマーと呼ばれる一種のニューラル ネットワークを使用して構築されます。
わかりやすくするために、以下に内訳を示します。
- 大量データに関するトレーニング: LLM は、書籍、記事、Web サイトなどを含む膨大なデータセットでトレーニングを受けます。この広範なトレーニングにより、文法、文脈、さらにはある程度の推論を含む言語のニュアンスを習得できます。
- トランスフォーマー: ほとんどの LLM の背後にあるアーキテクチャはトランスフォーマーと呼ばれます。このモデルは、アテンション メカニズムを使用して文中のさまざまな単語の重要性を評価し、以前のモデルよりもコンテキストをより適切に理解できるようにします。
- 実行するタスク: トレーニングを受けた後、LLM はさまざまな言語タスクを実行できます。これには、質問への回答、テキストの要約、言語の翻訳、クリエイティブ ライティングの作成、コーディングなどが含まれます。
- 人気のモデル: よく知られている LLM には、GPT-3、BERT、T5 などがあります。これらの事前トレーニング済みモデルは、特定のタスクに合わせて微調整できるため、開発者や研究者にとって多目的なツールになります。
- アプリケーション: LLM は、チャットボット、仮想アシスタント、自動コンテンツ作成などで使用されます。機械が人間の言語をより自然に理解して応答できるようにすることで、ユーザーとテクノロジーのインタラクションの改善に役立ちます。
本質的に、大規模言語モデルはコンピューターのスーパーチャージされた頭脳のようなもので、驚くほどの正確さと汎用性で人間の言語を処理および生成することを可能にします。
ハギングフェイス&LLM
Hugging Face は、自然言語処理 (NLP) と機械学習のハブとなっている企業でありプラットフォームです。開発者や研究者が機械学習モデル、特に言語の理解と生成に関連するモデルを簡単に構築および使用できるようにするためのツール、ライブラリ、リソースを提供しています。
Hugging Face はオープンソースライブラリ、特にTransformersで知られており、幅広い事前トレーニング済み言語モデルに簡単にアクセスできます。
Hugging Face は、GPT-3、BERT、T5 などの最先端の LLM を多数ホストしています。これらのモデルは、大規模なデータセットで事前トレーニングされており、さまざまなアプリケーションですぐに使用できます。
このプラットフォームは、機械学習に関する深い専門知識を必要とせずにこれらのモデルをアプリケーションに統合するためのシンプルな API とツールを提供します。
Hugging Face のツールを使用すると、これらの事前トレーニング済みの LLM を独自のデータで簡単に微調整し、特定のタスクやドメインに適応させることができます。
研究者や開発者は、Hugging Face プラットフォームでモデルや拡張機能を共有し、NLP のイノベーションと応用を加速できます。
あなたが利用すべきHuggingfaceのトップ5のLLMモデル
ストーリーテリングに優れ、GPT をも上回る、Hugging Face のトップ LLM モデルをいくつか見てみましょう。
ミストラル-7B-v0.1
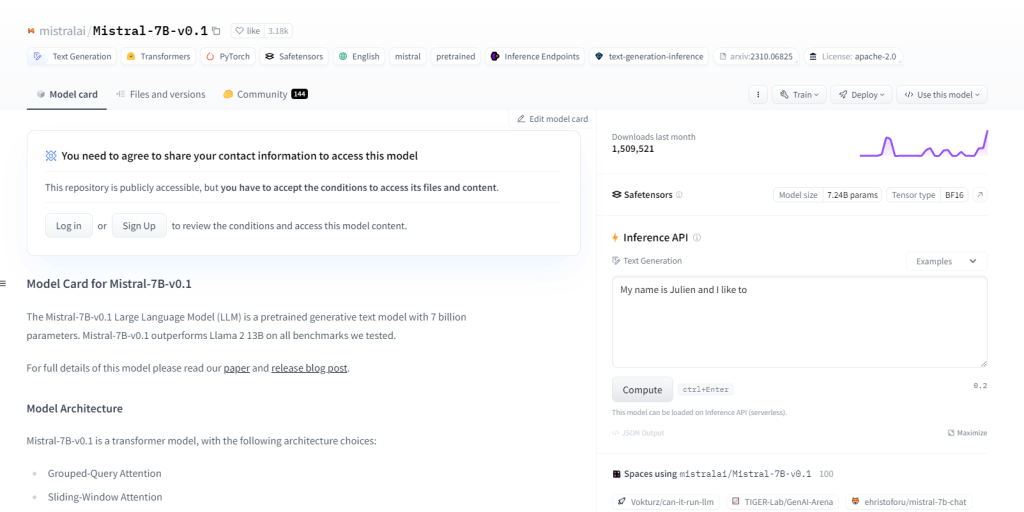
70 億のパラメータを持つ大規模言語モデル (LLM) である Mistral-7B-v0.1 は、さまざまなドメインで Llama 2 13B などのベンチマークよりも優れたパフォーマンスを発揮します。特定のアテンション メカニズムとバイト フォールバック BPE トークナイザーを備えたトランスフォーマー アーキテクチャを活用しています。テキスト生成、自然言語理解、言語翻訳に優れており、NLP プロジェクトの研究開発の基本モデルとして機能します。
主な特徴
- 70億のパラメータ
- Llama 213Bなどのベンチマークを上回る
- トランスフォーマーアーキテクチャ
- BPE トークナイザー
- NLPプロジェクト開発
- 自然言語理解
- 言語翻訳
- グループクエリアテンション
スターリング-LM-11B-アルファ
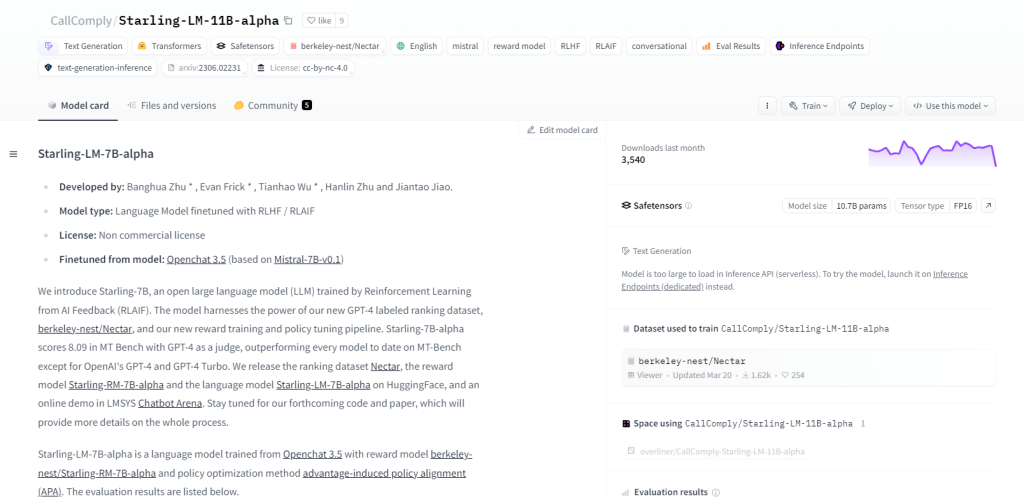
Starling-LM-11B-alpha は、110 億のパラメータを持つ大規模言語モデル (LLM) で、OpenChat 3.5 モデルをベースとして NurtureAI から登場しました。微調整は、人間によるラベル付けランキングによってガイドされる AI フィードバックからの強化学習 (RLAIF) によって実現されます。このモデルは、オープンソース フレームワークと、NLP タスク、機械学習の研究、教育、クリエイティブ コンテンツの生成などの多目的アプリケーションによって、人間と機械のインタラクションを再構築することを約束します。
主な特徴
- 110億のパラメータ
- NurtureAIによって開発
- OpenChat 3.5モデルに基づく
- RLAIFによる微調整
- トレーニングのための人間によるラベル付けランキング
- オープンソースの性質
- 多様な機能
- 研究、教育、クリエイティブコンテンツの生成に使用
Yi-34B-ラマ
340 億のパラメータを持つ Yi-34B-Llama は、優れた学習能力を備えています。マルチモーダル処理に優れ、テキスト、コード、画像を効率的に処理します。ゼロショット学習を採用しているため、新しいタスクにシームレスに適応します。ステートフルな性質により、過去のやり取りを記憶し、ユーザー エンゲージメントを強化できます。使用例には、テキスト生成、機械翻訳、質問応答、対話、コード生成、画像キャプション作成などがあります。
主な特徴
- 340億のパラメータ
- マルチモーダル処理
- ゼロショット学習機能
- ステートフルな性質
- テキスト生成
- 機械翻訳
- 質問への回答
- 画像キャプション
DeepSeek LLM 67B ベース
670億のパラメータを持つ大規模言語モデル(LLM)であるDeepSeek LLM 67B Baseは、推論、コーディング、数学のタスクで優れた性能を発揮します。GPT-3.5やLlama2 70B Baseを上回る優れたスコアを持ち、コードの理解と生成に優れ、優れた数学スキルを発揮します。MITライセンスによるオープンソースの性質により、自由な探索が可能です。使用例は、プログラミング、教育、研究、コンテンツ作成、翻訳、質問応答など多岐にわたります。
主な特徴
- 670億のパラメータ
- 推論、コーディング、数学における優れたパフォーマンス
- HumanEval Pass@1 スコア 73.78
- 優れたコード理解と生成
- GSM8K 0ショットの高得点(84.1)
- 言語能力においてGPT-3.5を上回る
- MITライセンスに基づくオープンソース
- 優れたストーリーテリングとコンテンツ作成能力。
Skote - Svelte 管理者およびダッシュボード テンプレート
Marcoroni-7B-v3 は、テキスト生成、言語翻訳、クリエイティブ コンテンツの作成、質問への回答など、さまざまなタスクを実行できる強力な 70 億のパラメータを持つ多言語生成モデルです。テキストとコードの両方の処理に優れており、事前のトレーニングなしでタスクを迅速に実行するためにゼロ ショット学習を活用します。オープンソースで許容ライセンスの Marcoroni-7B-v3 は、幅広い使用と実験を可能にします。
主な特徴
- 詩、コード、スクリプト、電子メールなどのテキスト生成。
- 高精度の機械翻訳。
- 自然な会話で魅力的なチャットボットを作成します。
- 自然言語記述からのコード生成。
- 包括的な質問回答機能。
- 長いテキストを簡潔な要約にまとめます。
- 元の意味を保ちながら効果的に言い換えます。
- テキストコンテンツの感情分析。
まとめ
Hugging Face の大規模言語モデルのコレクションは、開発者、研究者、愛好家にとって画期的なものです。これらのモデルは、その多様なアーキテクチャと機能により、自然言語の理解と生成の限界を押し広げる上で大きな役割を果たしています。テクノロジーが進化するにつれ、これらのモデルの用途と影響は無限です。大規模言語モデルの探求と革新の旅は継続しており、今後の刺激的な開発が期待されます。







