
AI を活用したテキストから動画への変換技術の台頭により、コンテンツの作成と消費の方法が変革しています。この変革の最前線にあるのが、コンテンツ作成者や企業にとって急速に頼りになるツールになりつつある強力な Hugging Face モデルです。

膨大なデータでトレーニングされたこれらの最先端の言語モデルは、書かれたテキストを魅力的な視覚的物語に変換する優れた能力を備えています。自然言語処理と生成 AI の最新の進歩を活用することで、Hugging Face モデルはあなたの言葉を視聴者を魅了する魅力的で高品質のビデオに簡単に変換できます。
テキストからビデオへの変換技術を理解する
テキストからビデオへのモデルは、記述された説明を動画に変換します。これらのモデルはテキストを理解し、それを、説明されているシーンやアクションを表すフレームのシーケンスに変換します。このプロセスには、テキスト分析、ビジュアル コンテンツの生成、フレームのシーケンスなど、複数のステップが含まれます。各ステップでは、出力ビデオが入力テキストを正確に表すように、複雑なアルゴリズムが必要です。
テキストから動画への変換技術の歩みは、シンプルなテキスト記述から基本的なアニメーションを生成することから始まりました。初期のモデルは静止画像の作成に重点を置いていましたが、AI と機械学習の進歩により、動的な動画生成の開発が可能になりました。長年にわたり、研究者は洗練されたニューラル ネットワークを統合し、動画の品質とリアリティを大幅に向上させました。これらの進歩により、クリエイティブなコンテンツの作成やさまざまな業界への応用に新たな可能性が開かれました。
Huggingface の 5 つの最高のテキストからビデオへの AI モデル
ここでは、huggingface の 5 つの最高の AI テキスト動画変換モデルを紹介します。これらのモデルは、その独特の機能で非常に人気があり、ダウンロード数も最も多くなっています。
モデルスコープ - 1.7b
ModelScope のテキストからビデオへの合成モデルは、多段階の拡散プロセスを使用して、テキストの説明からビデオを生成します。この高度なモデルは英語の入力のみをサポートし、研究目的で設計されています。このモデルは、テキスト特徴抽出、テキストからビデオへの潜在空間拡散、ビデオ潜在空間から視覚空間へのマッピングという 3 つのサブネットワークで構成されています。
17 億のパラメータと UNet3D 構造により、ガウス ノイズを反復的に除去してビデオを作成します。このモデルは、任意の英語テキストからビデオを作成するなど、さまざまなアプリケーションに適しています。ただし、トレーニング データからのバイアスや、高品質の映画レベルのビデオやクリア テキストを作成できないなどの制限があります。ユーザーは、有害または虚偽のコンテンツの生成を避ける必要があります。このモデルは、LAION5B、ImageNet、Webvid などのパブリック データセットでトレーニングされました。
主な特徴
- 多段階拡散プロセス
- 英語テキストサポート
- 17億のパラメータ
- UNet3Dアーキテクチャ
- 反復ノイズ除去法
- 研究目的の焦点
- 公開データセットのトレーニング
- 任意のテキスト生成
AnimateDiff-ライトニング
AnimateDiff-Lightning は、最先端のテキストからビデオを生成するモデルで、オリジナルの AnimateDiff よりも速度が向上し、ビデオの生成速度が 10 倍以上高速化されています。AnimateDiff SD1.5 v2 から開発されたこのモデルは、1 ステップ、2 ステップ、4 ステップ、8 ステップのバージョンが用意されており、ステップ数が多いモデルほど品質が向上します。epiCRealism や Realistic Vision などの様式化された基本モデルや、ToonYou や Mistoon Anime などのアニメや漫画のモデルと組み合わせて使用すると、優れた効果を発揮します。
ユーザーは、Motion LoRAs を使用するなど、さまざまな設定を試すことで最適な結果を得ることができます。実装では、モデルを Diffusers および ComfyUI とともに使用できます。出力を強化するために、ControlNet を使用したビデオからビデオへの生成をサポートしています。詳細とデモについては、研究論文「AnimateDiff-Lightning: Cross-Model Diffusion Distillation」を参照してください。
主な特徴
- 超高速ビデオ生成
- AnimateDiff から抽出
- 複数ステップのチェックポイント
- 高い発電品質
- 様式化されたモデルをサポート
- モーションLoRAsサポート
- リアルと漫画のオプション
- ビデオからビデオへの生成
ゼロスコープ V2
Modelscope ベースの zeroscope_v2_567w ビデオ モデルは、透かしのない高品質の 16:9 ビデオの作成に優れています。576x320 解像度、24 フレーム/秒で 9,923 個のクリップと 29,769 個のタグ付きフレームでトレーニングされており、スムーズなビデオ出力に最適です。このモデルは、1111 text2video 拡張機能の vid2vid を使用して zeroscope_v2_XL でアップスケールする前の初期レンダリング用に設計されており、低解像度での効率的な探索を可能にします。
1024x576 にアップスケールすると、優れた構成が得られます。30 フレームのレンダリングには 7.9 GB の VRAM を使用します。使用するには、適切なディレクトリ内のファイルをダウンロードして置き換えます。
最良の結果を得るには、ノイズ除去強度を 0.66 ~ 0.85 にして、zeroscope_v2_XL を使用してアップスケールします。既知の問題としては、解像度が低い場合やフレーム数が少ない場合に出力が最適にならないことが挙げられます。モデルは、簡単なインストールとビデオ生成手順で、ディフューザーを使用して簡単に統合できます。
主な特徴
- 透かしのない出力
- 高画質16:9
- スムーズなビデオ出力
- 576x320解像度
- 毎秒24フレーム
- 効率的なアップスケーリング
- 7.9GB VRAM使用量
- 簡単な統合
VGen
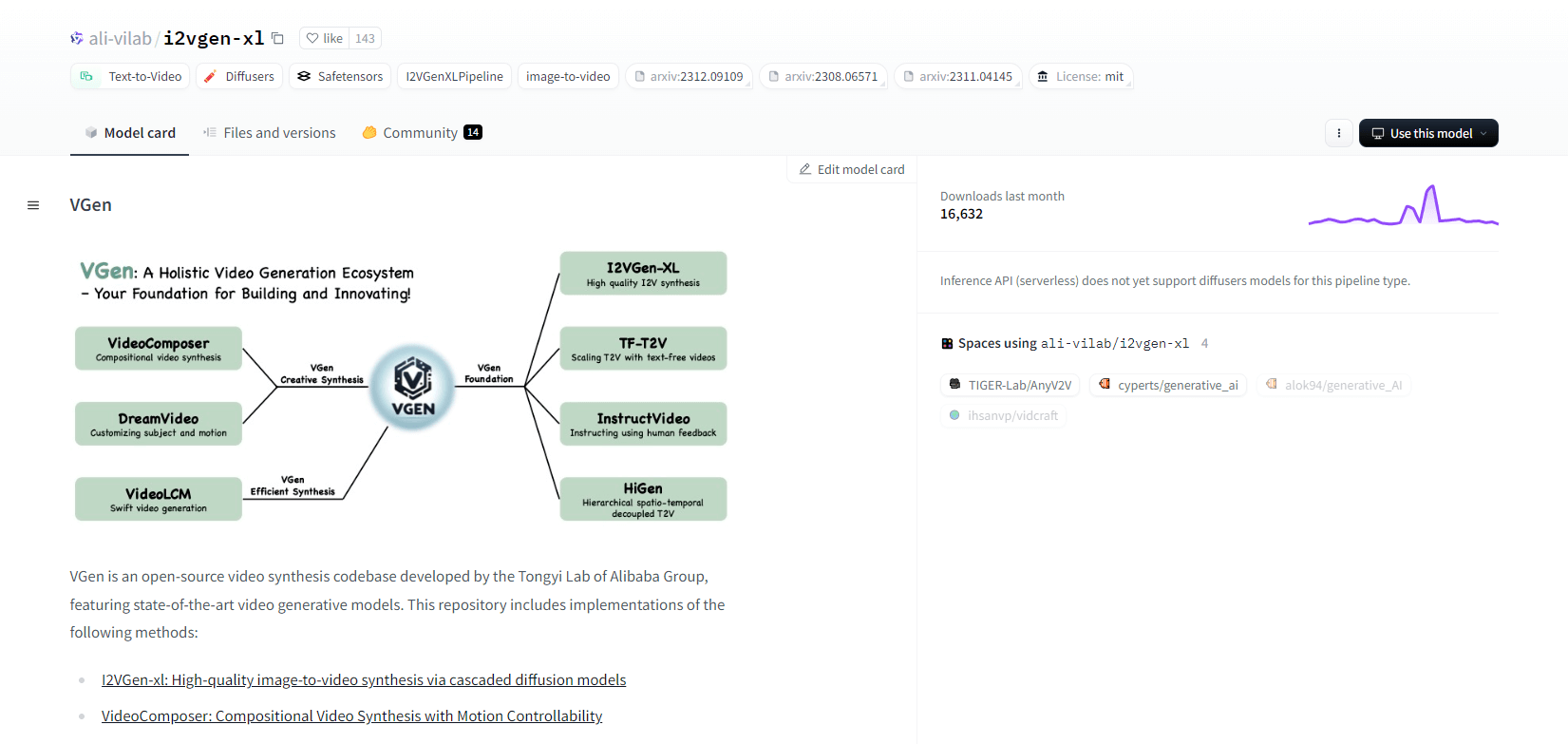
Alibaba の Tongyi Lab のオープンソース ビデオ合成コードベースである VGen は、高度なビデオ生成モデルを提供します。これには、高品質の画像からビデオへの合成のための I2VGen-xl、モーション制御可能なビデオ合成のための VideoComposer などのメソッドが含まれます。VGen は、テキスト、画像、目的の動き、被写体、フィードバック信号から高品質のビデオを作成できます。リポジトリには、画像とビデオを使用した視覚化、サンプリング、トレーニング、推論、共同トレーニングのためのツールが用意されています。最近の更新には、VideoLCM、I2VGen-XL、DreamVideo メソッドが含まれます。
VGen は拡張性、パフォーマンス、完全性に優れています。インストールには、Python 環境と必要なライブラリの設定が含まれます。ユーザーはテキストからビデオへのモデルをトレーニングし、I2VGen-XL を実行して高解像度のビデオを生成できます。実験と最適化を容易にするために、デモ データセットと事前トレーニング済みモデルが用意されています。コードベースにより、ビデオ合成タスクの管理が容易になり、効率が向上します。
主な特徴
- オープンソースのコードベース
- 高品質な合成
- 動作制御性
- テキストからビデオへの生成
- 画像からビデオへの変換
- 拡張可能なフレームワーク
- 事前学習済みモデル
- 包括的なツール
ホットショットXL
Natural Synthetics Inc. が開発した AI テキストから GIF への変換モデルである Hotshot-XL は、Stable Diffusion XL とシームレスに動作します。微調整された SDXL モデルを使用して GIF を生成できるため、追加の微調整なしでパーソナライズされた GIF を簡単に作成できます。このモデルは、さまざまなアスペクト比で 1 秒あたり 8 フレームで 1 秒の GIF を生成するのに優れています。事前トレーニング済みのテキスト エンコーダー (OpenCLIP-ViT/G および CLIP-ViT/L) を備えた Latent Diffusion を活用してパフォーマンスを強化します。
ユーザーは SDXL ControlNet を使用して GIF 構成を変更し、レイアウトをカスタマイズできます。Hotshot-XL は多用途の GIF 作成が可能ですが、フォトリアリズムや特定の構成のレンダリングなどの複雑なタスクでは課題があります。このモデルの実装は、既存のワークフローにスムーズに統合することを目的としており、CreativeML Open RAIL++-M ライセンスの下で GitHub で探索できます。
主な特徴
- テキストからGIFへの生成
- SDXLで動作
- 1秒のGIFを生成します
- さまざまなアスペクト比をサポート
- 潜在拡散を利用する
- 事前学習済みテキストエンコーダ
- ControlNetでカスタマイズ可能
- GitHubで利用可能
テキストからビデオへの AI モデルの将来の機能
Hugging Face のようなプラットフォームは、テキストを高品質で動的なビデオ コンテンツに変換できる高度なモデルの開発をリードしています。このことから、テキストからビデオへの AI モデルの将来の機能は非常にエキサイティングであると推測できます。
これらのモデルはコンテンツ作成に革命をもたらし、これまで以上に高速で効率的、そしてアクセスしやすいものにします。テキストプロンプトを入力するだけで、ユーザーは自分のアイデアを現実のものにできる魅力的でカスタマイズされたビデオを生成できます。
潜在的な用途は、マーケティングや広告から教育やエンターテイメントまで多岐にわたります。ボタンをクリックするだけで、プロ仕様の説明ビデオやアニメーションストーリーを作成できると想像してみてください。企業やクリエイターにとって、時間とコストの節約は大幅に増えるでしょう。
さらに、これらのテキストからビデオへの変換モデルは、リアリティ、一貫性、柔軟性の面で向上し続けており、出力の品質は人間が作成したビデオとますます区別がつかなくなっています。ビデオ制作の民主化により、より多くの人々が自分のストーリーやアイデアを世界と共有できるようになります。
コンテンツ作成の未来は間違いなくテキストから動画への変換であり、Hugging Face はこの変革的テクノロジーの最前線に立っています。これらのモデルが可能性の限界を押し広げていく様子に、きっと驚かされることでしょう。
まとめ
結論として、Huggingface はテキストからビデオへのタスクのための多様なモデルを提供しており、それぞれがテキストの説明から動的なビジュアル コンテンツを生成する独自の強みを持っています。精度、創造性、スケーラビリティのどれを優先するかにかかわらず、これらのモデルはさまざまなアプリケーションに堅牢なソリューションを提供し、AI 駆動型ビデオ合成の進歩を約束します。







