
Hugging Face è una miniera d'oro per chiunque sia interessato all'elaborazione del linguaggio naturale, ricco di una varietà di modelli linguistici preaddestrati che sono semplicissimi da usare in diverse applicazioni. Quando si tratta di Large Language Models (LLM), Hugging Face è la scelta migliore. In questo articolo, approfondiremo i 10 LLM migliori su Hugging Face, ognuno dei quali svolge un ruolo fondamentale nel far progredire il modo in cui comprendiamo e generiamo il linguaggio.

Iniziamo!
Cos'è il modello del linguaggio ampio?
I Large Language Models (LLM) sono tipi avanzati di intelligenza artificiale progettati per comprendere e generare il linguaggio umano. Sono costruiti utilizzando tecniche di deep learning, in particolare una sorta di rete neurale chiamata trasformatore.
Ecco una ripartizione per renderlo chiaro:
- Formazione su enormi quantità di dati : gli LLM vengono formati su enormi set di dati che includono libri, articoli, siti Web e altro ancora. Questa formazione approfondita li aiuta ad apprendere le sfumature della lingua, inclusa la grammatica, il contesto e persino un certo livello di ragionamento.
- Trasformatori : l'architettura dietro la maggior parte degli LLM è chiamata trasformatore. Questo modello utilizza meccanismi di attenzione per valutare l’importanza delle diverse parole in una frase, consentendogli di comprendere il contesto meglio rispetto ai modelli precedenti.
- Compiti che svolgono : una volta formati, i LLM possono eseguire vari compiti linguistici. Questi includono rispondere a domande, riassumere testi, tradurre lingue, generare scrittura creativa e codifica.
- Modelli popolari : alcuni LLM ben noti includono GPT-3, BERT e T5. Questi modelli pre-addestrati possono essere ottimizzati per compiti specifici, rendendoli strumenti versatili per sviluppatori e ricercatori.
- Applicazioni : gli LLM vengono utilizzati in chatbot, assistenti virtuali, creazione automatizzata di contenuti e molto altro. Aiutano a migliorare le interazioni dell'utente con la tecnologia facendo sì che le macchine comprendano e rispondano al linguaggio umano in modo più naturale.
In sostanza, i modelli linguistici di grandi dimensioni sono come cervelli potenziati per i computer, consentendo loro di gestire e generare il linguaggio umano con impressionante precisione e versatilità.
HuggingFace e LLM
Hugging Face è un'azienda e una piattaforma diventata un hub per l'elaborazione del linguaggio naturale (PNL) e l'apprendimento automatico. Forniscono strumenti, librerie e risorse per rendere più semplice per sviluppatori e ricercatori la creazione e l'utilizzo di modelli di apprendimento automatico, in particolare quelli relativi alla comprensione e alla generazione del linguaggio.
Hugging Face è noto per le sue librerie open source, in particolare Transformers , che forniscono un facile accesso a un'ampia gamma di modelli linguistici pre-addestrati.
Hugging Face ospita molti LLM all'avanguardia come GPT-3, BERT e T5. Questi modelli sono pre-addestrati su set di dati di grandi dimensioni e sono pronti per essere utilizzati per varie applicazioni.
La piattaforma fornisce API e strumenti semplici per integrare questi modelli nelle applicazioni senza richiedere una profonda esperienza nell'apprendimento automatico.
Utilizzando gli strumenti di Hugging Face, puoi facilmente mettere a punto questi LLM preaddestrati sui tuoi dati, permettendoti di adattarli ad attività o domini specifici.
Ricercatori e sviluppatori possono condividere i propri modelli e miglioramenti sulla piattaforma Hugging Face, accelerando l'innovazione e l'applicazione nella PNL.
I 5 migliori modelli LLM su Huggingface che dovresti usare
Esploriamo alcuni dei migliori modelli LLM su Hugging Face che eccellono nella narrazione e superano persino GPT.
Mistral-7B-v0.1
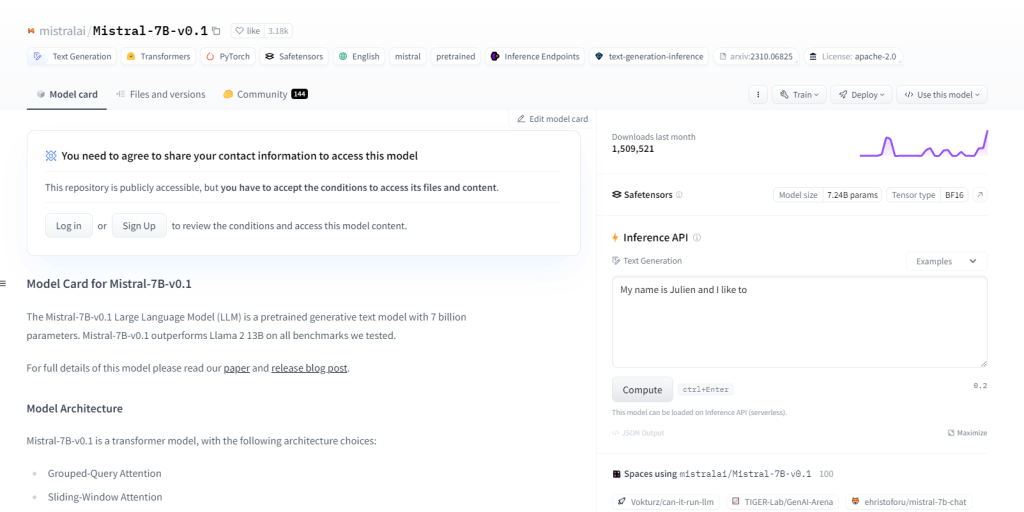
Il Mistral-7B-v0.1, un Large Language Model (LLM) con 7 miliardi di parametri, supera i benchmark come Llama 2 13B in tutti i domini. Utilizza l'architettura del trasformatore con meccanismi di attenzione specifici e un tokenizzatore BPE con fallback di byte. Eccelle nella generazione di testi, nella comprensione del linguaggio naturale, nella traduzione linguistica e funge da modello base per la ricerca e lo sviluppo nei progetti di PNL.
Caratteristiche principali
- 7 miliardi di parametri
- Supera i benchmark come Llama 213B
- Architettura del trasformatore
- Tokenizzatore BPE
- Sviluppo di progetti di PNL
- Comprensione del linguaggio naturale
- Traduzione linguistica
- Attenzione alle query raggruppate
Starling-LM-11B-alfa
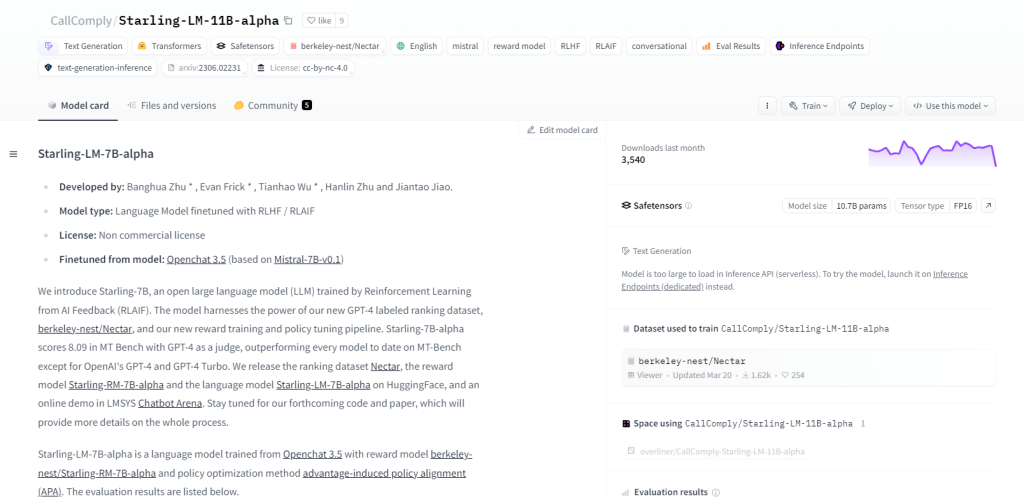
Starling-LM-11B-alpha, un modello linguistico di grandi dimensioni (LLM) con 11 miliardi di parametri, emerge da NurtureAI, sfruttando il modello OpenChat 3.5 come base. La messa a punto viene ottenuta attraverso l'apprendimento per rinforzo dal feedback dell'intelligenza artificiale (RLAIF), guidato da classifiche etichettate dagli esseri umani. Questo modello promette di rimodellare l’interazione uomo-macchina con il suo framework open source e applicazioni versatili, tra cui attività di PNL, ricerca sull’apprendimento automatico, istruzione e generazione di contenuti creativi.
Caratteristiche principali
- 11 miliardi di parametri
- Sviluppato da NurtureAI
- Basato sul modello OpenChat 3.5
- Ottimizzato tramite RLAIF
- Classifiche con etichetta umana per la formazione
- Natura open source
- Capacità diverse
- Utilizzare per la ricerca, l'istruzione e la generazione di contenuti creativi
Yi-34B-Lama
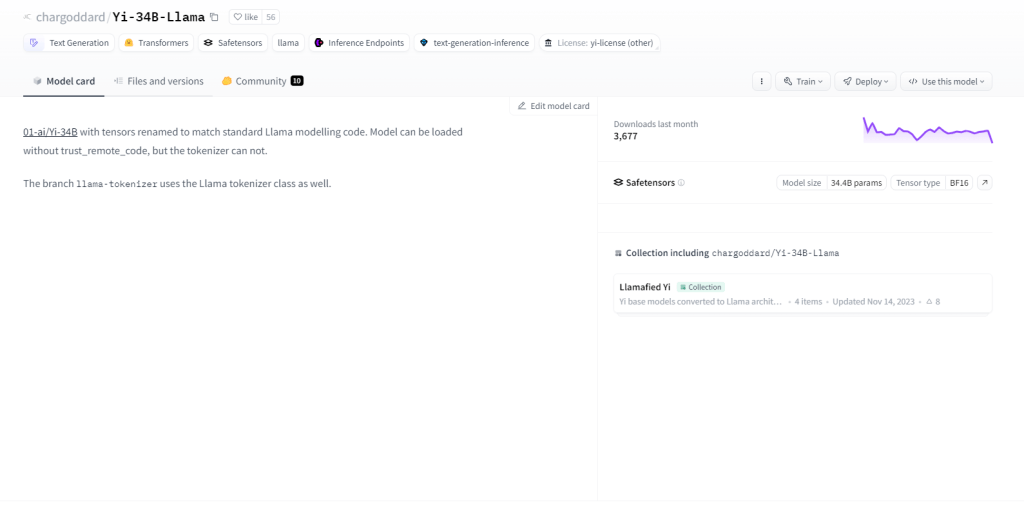
Yi-34B-Llama, con i suoi 34 miliardi di parametri, mostra una capacità di apprendimento superiore. Eccelle nell'elaborazione multimodale, nella gestione efficiente di testo, codice e immagini. Abbracciando l'apprendimento zero-shot, si adatta perfettamente alle nuove attività. La sua natura con stato gli consente di ricordare le interazioni passate, migliorando il coinvolgimento dell'utente. I casi d'uso includono la generazione di testo, la traduzione automatica, la risposta alle domande, il dialogo, la generazione di codice e i sottotitoli delle immagini.
Caratteristiche principali
- 34 miliardi di parametri
- Elaborazione multimodale
- Capacità di apprendimento zero-shot
- Natura statale
- Generazione del testo
- Traduzione automatica
- Risposta alla domanda
- Didascalia delle immagini
Base DeepSeek LLM67B
DeepSeek LLM 67B Base, un modello LLM (Large Language Model) da 67 miliardi di parametri, eccelle nei compiti di ragionamento, codifica e matematica. Con punteggi eccezionali che superano GPT-3.5 e Llama2 70B Base, eccelle nella comprensione e generazione di codice e dimostra notevoli capacità matematiche. La sua natura open source sotto la licenza MIT consente l'esplorazione gratuita. I casi d'uso spaziano dalla programmazione, all'istruzione, alla ricerca, alla creazione di contenuti, alla traduzione e alla risposta alle domande.
Caratteristiche principali
- Parametro di 67 miliardi
- Prestazioni eccezionali nel ragionamento, nella codifica e nella matematica
- Punteggio HumanEval Pass@1 di 73,78
- Eccezionale comprensione e generazione del codice
- Punteggi alti su GSM8K 0-shot (84,1)
- Supera GPT-3.5 nelle capacità linguistiche
- Open source sotto licenza MIT
- Eccellente capacità di narrazione e creazione di contenuti.
Skote: modello di amministrazione e dashboard snello
Marcoroni-7B-v3 è un potente modello generativo multilingue da 7 miliardi di parametri in grado di svolgere diverse attività, tra cui la generazione di testi, la traduzione linguistica, la creazione di contenuti creativi e la risposta a domande. Eccelle nell'elaborazione sia di testo che di codice, sfruttando l'apprendimento zero-shot per eseguire rapidamente le attività senza formazione preventiva. Open source e con una licenza permissiva, Marcoroni-7B-v3 facilita un ampio utilizzo e sperimentazione.
Caratteristiche principali
- Generazione di testo per poesie, codice, script, e-mail e altro ancora.
- Traduzione automatica ad alta precisione.
- Creazione di chatbot coinvolgenti con conversazioni naturali.
- Generazione di codice da descrizioni in linguaggio naturale.
- Funzionalità complete di risposta alle domande.
- Riassunto di testi lunghi in riassunti concisi.
- Parafrasi efficace preservando il significato originale.
- Analisi del sentiment per contenuti testuali.
Avvolgendo
La raccolta di modelli linguistici di grandi dimensioni di Hugging Face rappresenta un punto di svolta per sviluppatori, ricercatori e appassionati. Questi modelli svolgono un ruolo importante nello ampliare i confini della comprensione e della generazione del linguaggio naturale, grazie alle loro diverse architetture e capacità. Con l’evolversi della tecnologia, le applicazioni e l’impatto di questi modelli sono infiniti. Il viaggio di esplorazione e innovazione con i modelli linguistici di grandi dimensioni è in corso e promette sviluppi entusiasmanti in futuro.









