
L'ascesa della tecnologia text-to-video basata sull'intelligenza artificiale sta rivoluzionando il modo in cui creiamo e consumiamo contenuti. In prima linea in questa trasformazione ci sono i potenti modelli Hugging Face, che stanno rapidamente diventando gli strumenti preferiti sia dai creatori di contenuti che dalle aziende.

Questi modelli linguistici all'avanguardia, addestrati su vaste quantità di dati, possiedono la straordinaria capacità di tradurre il testo scritto in accattivanti narrazioni visive. Sfruttando gli ultimi progressi nell'elaborazione del linguaggio naturale e nell'intelligenza artificiale generativa, i modelli Hugging Face possono trasformare senza sforzo le tue parole in video coinvolgenti e di alta qualità che catturano il tuo pubblico.
Comprendere la tecnologia Text-to-Video
I modelli text-to-video trasformano le descrizioni scritte in immagini in movimento. Questi modelli comprendono il testo e lo convertono in una sequenza di fotogrammi che raffigurano la scena o l'azione descritta. Questo processo comporta più passaggi, tra cui l'analisi del testo, la generazione di contenuti visivi e il sequenziamento dei fotogrammi. Ogni passaggio richiede algoritmi complessi per garantire che il video di output rappresenti accuratamente il testo di input.
Il viaggio della tecnologia text-to-video è iniziato con semplici descrizioni di testo che generavano animazioni di base. I primi modelli si concentravano sulla creazione di immagini statiche, ma i progressi nell'intelligenza artificiale e nell'apprendimento automatico hanno consentito lo sviluppo della generazione di video dinamici. Nel corso degli anni, i ricercatori hanno integrato sofisticate reti neurali, portando a significativi miglioramenti nella qualità e nel realismo dei video. Questi progressi hanno aperto nuove possibilità per la creazione di contenuti creativi e varie applicazioni in tutti i settori.
I 5 migliori modelli di intelligenza artificiale da testo a video di Huggingface
Ecco i 5 migliori modelli AI text-to-video di huggingface. Questi modelli sono molto popolari per la loro funzionalità distinta e hanno il maggior numero di download.
ModelloScope - 1.7b
Il modello di sintesi testo-video di ModelScope utilizza un processo di diffusione multi-stadio per generare video da descrizioni di testo. Questo modello avanzato supporta solo input in inglese ed è progettato per scopi di ricerca. È costituito da tre sottoreti: estrazione di caratteristiche di testo, diffusione di spazio latente testo-video e mappatura di spazio latente video in spazio visivo.
Con 1,7 miliardi di parametri e una struttura UNet3D, denoise iterativamente il rumore gaussiano per creare video. Questo modello è adatto a varie applicazioni, come la creazione di video da testo inglese arbitrario. Tuttavia, presenta delle limitazioni, come i bias dei dati di training e l'incapacità di produrre video di alta qualità a livello di film o testo chiaro. Gli utenti devono evitare di generare contenuti dannosi o falsi. Il modello è stato addestrato su set di dati pubblici, tra cui LAION5B, ImageNet e Webvid.
Caratteristiche principali
- Processo di diffusione multistadio
- Supporto testo inglese
- 1,7 miliardi di parametri
- Architettura UNet3D
- Metodo di denoising iterativo
- Obiettivo della ricerca
- Formazione sui set di dati pubblici
- Generazione di testo arbitrario
AnimateDiff-Fulmine
AnimateDiff-Lightning è un modello di generazione testo-video all'avanguardia che offre miglioramenti di velocità rispetto all'AnimateDiff originale, generando video più di dieci volte più velocemente. Sviluppato da AnimateDiff SD1.5 v2, questo modello è disponibile nelle versioni a 1, 2, 4 e 8 step, con modelli a step più elevati che offrono una qualità superiore. Eccelle quando utilizzato con modelli base stilizzati come epiCRealism e Realistic Vision, così come modelli anime e cartoon come ToonYou e Mistoon Anime.
Gli utenti possono ottenere risultati ottimali sperimentando diverse impostazioni, come l'utilizzo di Motion LoRA. Per l'implementazione, il modello può essere utilizzato con Diffusers e ComfyUI. Supporta la generazione video-video con ControlNet per un output migliorato. Per maggiori dettagli e una demo, gli utenti sono incoraggiati a fare riferimento al documento di ricerca: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Caratteristiche principali
- Generazione video ultraveloce
- Distillato da AnimateDiff
- Punti di controllo a più fasi
- Alta qualità di generazione
- Supporta modelli stilizzati
- Supporto Motion LoRA
- Opzioni realistiche e cartoon
- Generazione video-video
Zeroscopio V2
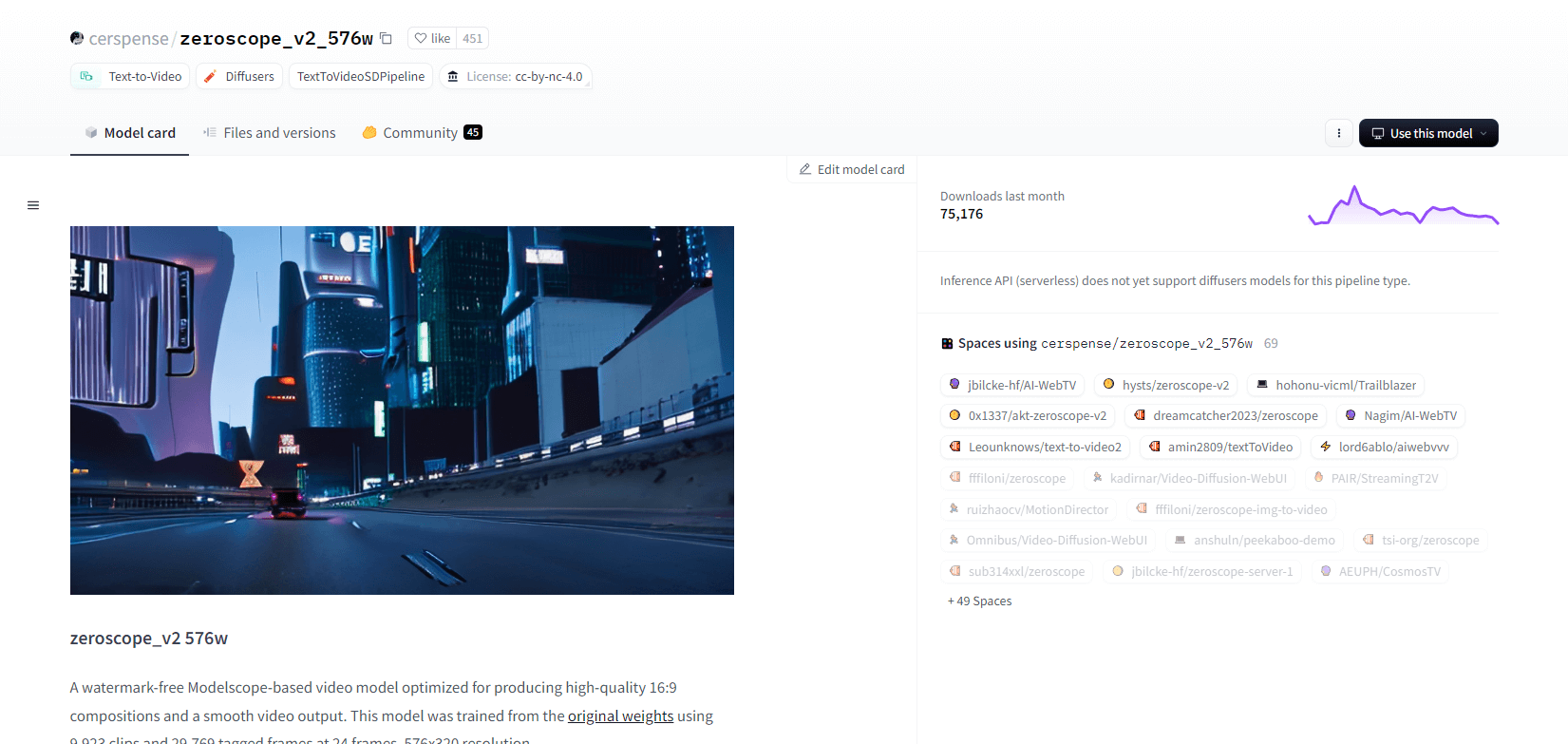
Il modello video zeroscope_v2_567w basato su Modelscope eccelle nella creazione di video 16:9 di alta qualità senza filigrane. Addestrato su 9.923 clip e 29.769 frame taggati a risoluzione 576x320 e 24 frame al secondo, è ideale per un output video fluido. Questo modello è progettato per il rendering iniziale prima dell'upscaling con zeroscope_v2_XL utilizzando vid2vid nell'estensione text2video 1111, consentendo un'esplorazione efficiente a risoluzioni inferiori.
L'upscaling a 1024x576 fornisce composizioni superiori. Utilizza 7,9 GB di VRAM per il rendering di 30 frame. Per utilizzarlo, scarica e sostituisci i file nella directory appropriata.
Per ottenere risultati ottimali, esegui l'upscaling usando zeroscope_v2_XL con una forza di denoise compresa tra 0,66 e 0,85. I problemi noti includono output non ottimali a risoluzioni inferiori o con meno frame. Il modello può essere facilmente integrato usando Diffusers con semplici passaggi di installazione e generazione video.
Caratteristiche principali
- Output senza filigrana
- Alta qualità 16:9
- Uscita video fluida
- Risoluzione 576x320
- 24 fotogrammi al secondo
- Upscaling efficiente
- Utilizzo di VRAM pari a 7,9 GB
- Facile integrazione
V-Gene
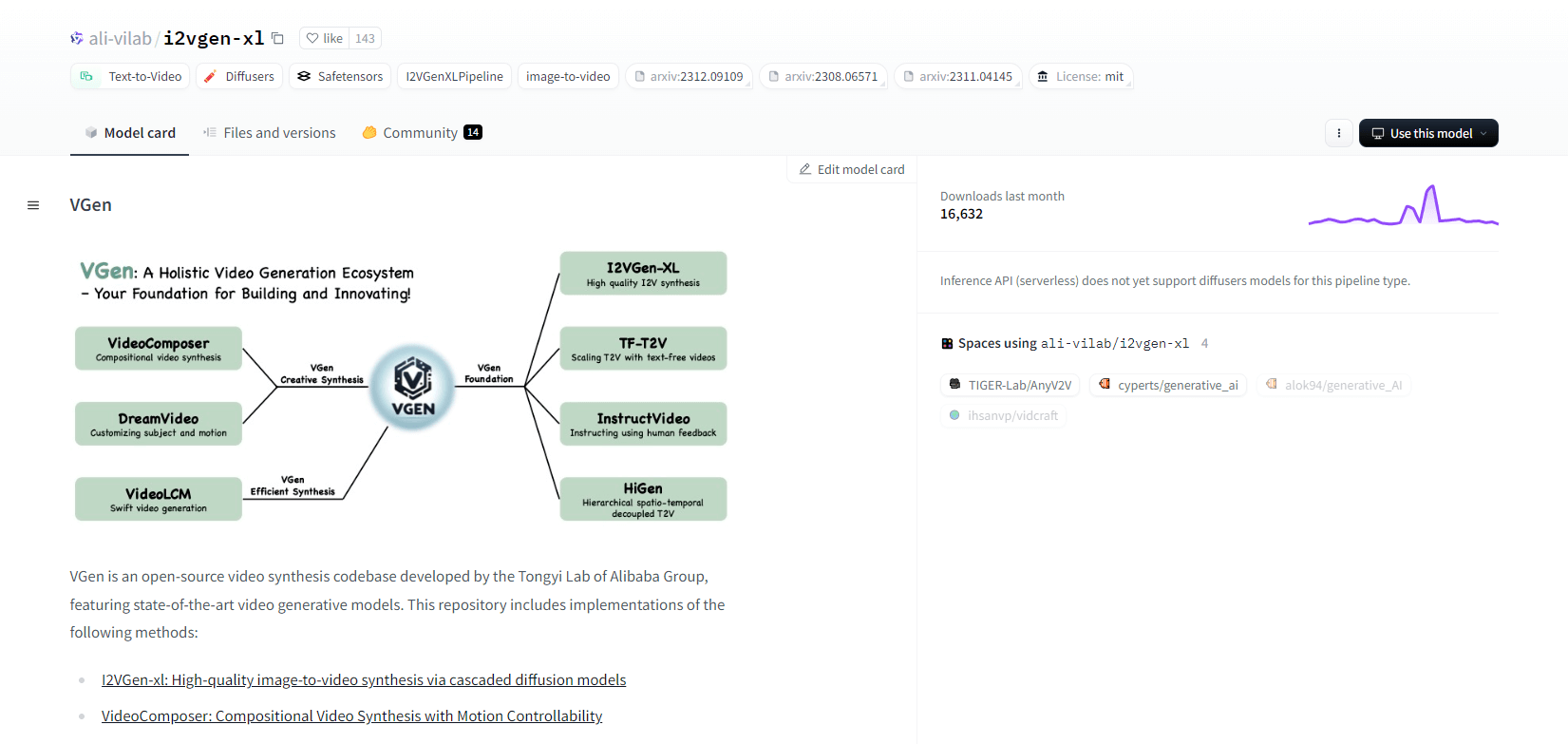
VGen, un codice di sintesi video open source del Tongyi Lab di Alibaba, offre modelli di generazione video avanzati. Include metodi come I2VGen-xl per la sintesi di immagini in video di alta qualità, VideoComposer per la sintesi video controllabile dal movimento e altro ancora. VGen può creare video di alta qualità da testo, immagini, movimenti desiderati, soggetti e segnali di feedback. Il repository include strumenti per la visualizzazione, il campionamento, l'addestramento, l'inferenza e l'addestramento congiunto utilizzando immagini e video. Gli aggiornamenti recenti includono VideoLCM, I2VGen-XL e il metodo DreamVideo.
VGen eccelle in espandibilità, prestazioni e completezza. L'installazione comporta la configurazione di un ambiente Python e delle librerie necessarie. Gli utenti possono addestrare modelli text-to-video ed eseguire I2VGen-XL per la generazione di video ad alta definizione. Sono disponibili set di dati demo e modelli pre-addestrati per facilitare la sperimentazione e l'ottimizzazione. La base di codice garantisce una gestione semplice e un'elevata efficienza nelle attività di sintesi video.
Caratteristiche principali
- Base di codice open source
- Sintesi di alta qualità
- Controllabilità del movimento
- Generazione testo-video
- Conversione da immagine a video
- Framework espandibile
- Modelli pre-addestrati
- Strumenti completi
Colpo forte XL
Hotshot-XL, un modello AI text-to-GIF sviluppato da Natural Synthetics Inc., funziona in modo fluido con Stable Diffusion XL. Consente la generazione di GIF utilizzando qualsiasi modello SDXL ottimizzato, semplificando la creazione di GIF personalizzate senza ulteriori ottimizzazioni. Questo modello eccelle nella generazione di GIF da 1 secondo a 8 frame al secondo su vari aspect ratio. Sfrutta Latent Diffusion con codificatori di testo pre-addestrati (OpenCLIP-ViT/G e CLIP-ViT/L) per prestazioni migliorate.
Gli utenti possono modificare le composizioni GIF usando SDXL ControlNet per layout personalizzati. Sebbene in grado di creare GIF versatili, Hotshot-XL affronta sfide con il fotorealismo e attività complesse come il rendering di composizioni specifiche. L'implementazione del modello mira a integrarsi senza problemi nei flussi di lavoro esistenti ed è disponibile per l'esplorazione su GitHub con una licenza CreativeML Open RAIL++-M.
Caratteristiche principali
- Generazione di testo in GIF
- Funziona con SDXL
- Genera GIF di 1 secondo
- Supporta vari rapporti di aspetto
- Utilizza la diffusione latente
- Codificatori di testo preaddestrati
- Personalizzabile con ControlNet
- Disponibile su GitHub
Capacità future dei modelli di intelligenza artificiale da testo a video
Piattaforme come Hugging Face stanno aprendo la strada allo sviluppo di modelli avanzati in grado di trasformare il testo in contenuti video dinamici di alta qualità. Ciò ci porta a supporre che le capacità future dei modelli AI text-to-video siano davvero entusiasmanti.
Questi modelli sono pronti a rivoluzionare la creazione di contenuti, rendendola più veloce, più efficiente e più accessibile che mai. Semplicemente inserendo un prompt di testo, gli utenti saranno in grado di generare video coinvolgenti e personalizzati che danno vita alle loro idee.
Le potenziali applicazioni sono vaste, dal marketing e dalla pubblicità all'istruzione e all'intrattenimento. Immagina di poter creare video esplicativi di livello professionale o storie animate con un clic. Il risparmio di tempo e denaro per aziende e creatori sarà notevole.
Inoltre, man mano che questi modelli text-to-video continuano a migliorare in termini di realismo, coerenza e flessibilità, la qualità dell'output diventerà sempre più indistinguibile dal video creato dall'uomo. Questa democratizzazione della produzione video consentirà a più persone di condividere le proprie storie e idee con il mondo.
Il futuro della creazione di contenuti è senza dubbio il text-to-video, e Hugging Face è all'avanguardia di questa tecnologia trasformativa. Preparatevi a rimanere stupiti mentre questi modelli spingono i confini di ciò che è possibile.
Conclusione
In conclusione, Huggingface offre una vasta gamma di modelli per attività di conversione da testo a video, ognuno dei quali apporta punti di forza unici nella generazione di contenuti visivi dinamici da descrizioni testuali. Che si dia priorità alla precisione, alla creatività o alla scalabilità, questi modelli forniscono soluzioni solide per varie applicazioni, promettendo progressi nella sintesi video basata sull'intelligenza artificiale.








