
Meningkatnya teknologi teks-ke-video yang didukung AI merevolusi cara kita membuat dan mengonsumsi konten. Model Hugging Face yang canggih menjadi yang terdepan dalam transformasi ini, yang dengan cepat menjadi alat andalan bagi kreator konten dan bisnis.

Model bahasa canggih ini, yang dilatih pada kumpulan data yang sangat banyak, memiliki kemampuan luar biasa untuk menerjemahkan teks tertulis menjadi narasi visual yang memikat. Dengan memanfaatkan kemajuan terbaru dalam pemrosesan bahasa alami dan AI generatif, model Hugging Face dapat dengan mudah mengubah kata-kata Anda menjadi video menarik dan berkualitas tinggi yang memikat audiens Anda.
Memahami Teknologi Teks-ke-Video
Model teks-ke-video mengubah deskripsi tertulis menjadi gambar bergerak. Model ini memahami teks dan mengubahnya menjadi serangkaian bingkai yang menggambarkan adegan atau tindakan yang dijelaskan. Proses ini melibatkan beberapa langkah, termasuk analisis teks, pembuatan konten visual, dan pengurutan bingkai. Setiap langkah memerlukan algoritme yang kompleks untuk memastikan video keluaran secara akurat mewakili teks masukan.
Perjalanan teknologi teks-ke-video dimulai dengan deskripsi teks sederhana yang menghasilkan animasi dasar. Model awal difokuskan pada pembuatan gambar statis, tetapi kemajuan dalam AI dan pembelajaran mesin telah memungkinkan pengembangan pembuatan video dinamis. Selama bertahun-tahun, para peneliti telah mengintegrasikan jaringan saraf yang canggih, yang menghasilkan peningkatan signifikan dalam kualitas dan realisme video. Kemajuan ini telah membuka kemungkinan baru untuk pembuatan konten kreatif dan berbagai aplikasi di seluruh industri.
5 Model AI Teks ke Video Terbaik dari Huggingface
Berikut ini adalah 5 model AI text-to-video terbaik dari huggingface. Model-model ini sangat populer karena fungsinya yang unik dan memiliki jumlah unduhan terbanyak.
Lingkup Model - 1.7b
Model sintesis teks ke video dari ModelScope menggunakan proses difusi multitahap untuk menghasilkan video dari deskripsi teks. Model canggih ini hanya mendukung masukan bahasa Inggris dan dirancang untuk keperluan penelitian. Model ini terdiri dari tiga subjaringan: ekstraksi fitur teks, difusi ruang laten teks ke video, dan pemetaan ruang laten video ke ruang visual.
Dengan 1,7 miliar parameter dan struktur UNet3D, model ini secara berulang menghilangkan derau Gaussian untuk membuat video. Model ini cocok untuk berbagai aplikasi, seperti membuat video dari teks bahasa Inggris yang sembarangan. Akan tetapi, model ini memiliki keterbatasan, seperti bias dari data pelatihan dan ketidakmampuan untuk menghasilkan video berkualitas tinggi atau teks yang jelas. Pengguna harus menghindari pembuatan konten yang berbahaya atau salah. Model ini dilatih pada kumpulan data publik, termasuk LAION5B, ImageNet, dan Webvid.
Fitur Utama
- Proses difusi multi tahap
- Dukungan teks bahasa Inggris
- 1,7 miliar parameter
- Arsitektur UNet3D
- Metode pengurangan derau berulang
- Fokus tujuan penelitian
- Pelatihan kumpulan data publik
- Pembuatan teks sembarangan
AnimasiDiff-Petir
AnimateDiff-Lightning adalah model pembuatan teks ke video yang canggih yang menawarkan peningkatan kecepatan dibanding AnimateDiff asli, menghasilkan video lebih dari sepuluh kali lebih cepat. Dikembangkan dari AnimateDiff SD1.5 v2, model ini tersedia dalam versi 1 langkah, 2 langkah, 4 langkah, dan 8 langkah, dengan model langkah yang lebih tinggi menawarkan kualitas yang lebih unggul. Model ini unggul saat digunakan dengan model dasar bergaya seperti epiCRealism dan Realistic Vision, serta model anime dan kartun seperti ToonYou dan Mistoon Anime.
Pengguna dapat memperoleh hasil optimal dengan bereksperimen dengan pengaturan yang berbeda, seperti menggunakan Motion LoRA. Untuk implementasi, model dapat digunakan dengan Diffusers dan ComfyUI. Model ini mendukung pembuatan video-ke-video dengan ControlNet untuk hasil yang lebih baik. Untuk detail lebih lanjut dan demo, pengguna dianjurkan untuk merujuk ke makalah penelitian: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Fitur Utama
- Pembuatan video secepat kilat
- Disuling dari AnimateDiff
- Titik pemeriksaan multi-langkah
- Kualitas generasi tinggi
- Mendukung model bergaya
- Dukungan Motion LoRA
- Pilihan realistis dan kartun
- Pembuatan video ke video
Zeroskop V2
Model video zeroscope_v2_567w berbasis Modelscope unggul dalam membuat video 16:9 berkualitas tinggi tanpa tanda air. Dilatih pada 9.923 klip dan 29.769 bingkai yang diberi tag pada resolusi 576x320 dan 24 bingkai per detik, model ini ideal untuk keluaran video yang lancar. Model ini dirancang untuk rendering awal sebelum peningkatan skala dengan zeroscope_v2_XL menggunakan vid2vid dalam ekstensi text2video 1111, yang memungkinkan eksplorasi yang efisien pada resolusi yang lebih rendah.
Peningkatan ke 1024x576 menghasilkan komposisi yang lebih baik. VRAM sebesar 7,9 GB digunakan untuk merender 30 frame. Untuk menggunakannya, unduh dan ganti file di direktori yang sesuai.
Untuk hasil terbaik, tingkatkan skala menggunakan zeroscope_v2_XL dengan kekuatan denoise antara 0,66 dan 0,85. Masalah yang diketahui meliputi output yang kurang optimal pada resolusi yang lebih rendah atau lebih sedikit frame. Model dapat dengan mudah diintegrasikan menggunakan Diffusers dengan langkah-langkah instalasi dan pembuatan video yang sederhana.
Fitur Utama
- Keluaran bebas tanda air
- Kualitas tinggi 16:9
- Output video lancar
- Resolusi 576x320
- 24 bingkai per detik
- Peningkatan yang efisien
- Penggunaan VRAM 7,9 GB
- Integrasi yang mudah
VGen
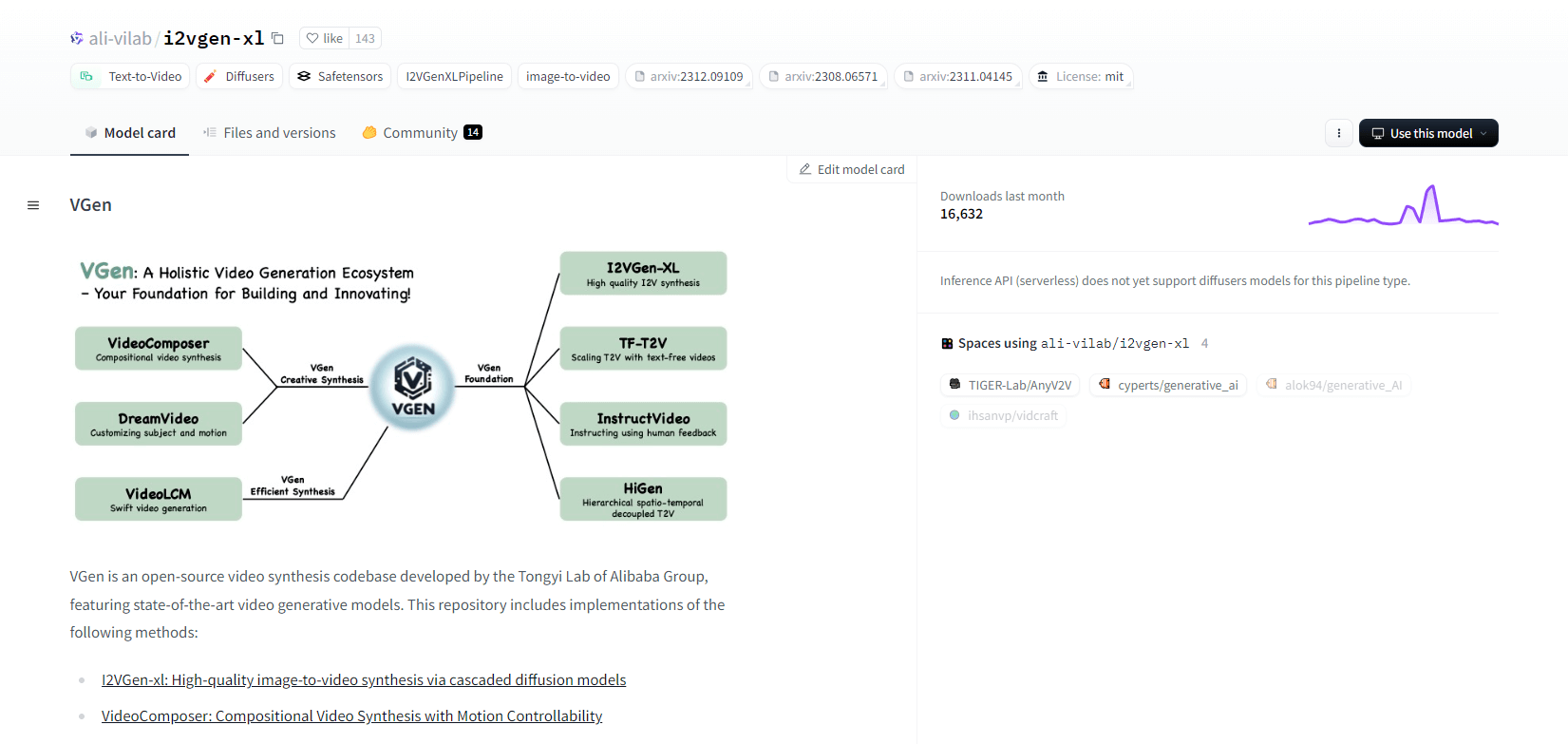
VGen, basis kode sintesis video sumber terbuka dari Tongyi Lab milik Alibaba, menawarkan model generatif video yang canggih. VGen mencakup metode seperti I2VGen-xl untuk sintesis gambar-ke-video berkualitas tinggi, VideoComposer untuk sintesis video yang dapat dikontrol gerakan, dan banyak lagi. VGen dapat membuat video berkualitas tinggi dari teks, gambar, gerakan yang diinginkan, subjek, dan sinyal umpan balik. Repositori ini menyediakan alat untuk visualisasi, pengambilan sampel, pelatihan, inferensi, dan pelatihan gabungan menggunakan gambar dan video. Pembaruan terkini mencakup VideoLCM, I2VGen-XL, dan metode DreamVideo.
VGen unggul dalam hal perluasan, kinerja, dan kelengkapan. Instalasi melibatkan pengaturan lingkungan Python dan pustaka yang diperlukan. Pengguna dapat melatih model teks-ke-video dan menjalankan I2VGen-XL untuk pembuatan video definisi tinggi. Kumpulan data demo dan model yang telah dilatih sebelumnya tersedia untuk memfasilitasi eksperimen dan pengoptimalan. Basis kode memastikan pengelolaan yang mudah dan efisiensi tinggi dalam tugas sintesis video.
Fitur Utama
- Basis kode sumber terbuka
- Sintesis berkualitas tinggi
- Pengendalian gerakan
- Pembuatan teks ke video
- Konversi gambar ke video
- Kerangka kerja yang dapat diperluas
- Model yang telah dilatih sebelumnya
- Alat yang komprehensif
Hotshot XL
Hotshot-XL, model AI text-to-GIF yang dikembangkan oleh Natural Synthetics Inc., beroperasi dengan lancar dengan Stable Diffusion XL. Model ini memungkinkan pembuatan GIF menggunakan model SDXL yang telah disetel dengan baik, menyederhanakan pembuatan GIF yang dipersonalisasi tanpa penyetelan tambahan. Model ini unggul dalam menghasilkan GIF 1 detik pada 8 bingkai per detik di berbagai rasio aspek. Model ini memanfaatkan Latent Diffusion dengan encoder teks yang telah dilatih sebelumnya (OpenCLIP-ViT/G dan CLIP-ViT/L) untuk meningkatkan kinerja.
Pengguna dapat memodifikasi komposisi GIF menggunakan SDXL ControlNet untuk tata letak yang disesuaikan. Meskipun mampu membuat GIF yang serbaguna, Hotshot-XL menghadapi tantangan dengan fotorealisme dan tugas-tugas rumit seperti merender komposisi tertentu. Implementasi model ini bertujuan untuk terintegrasi dengan lancar ke dalam alur kerja yang ada dan tersedia untuk dieksplorasi di GitHub di bawah Lisensi CreativeML Open RAIL++-M.
Fitur Utama
- Pembuatan teks ke GIF
- Bekerja dengan SDXL
- Menghasilkan GIF 1 detik
- Mendukung berbagai rasio aspek
- Menggunakan Difusi Laten
- Encoder teks yang telah dilatih sebelumnya
- Dapat disesuaikan dengan ControlNet
- Tersedia di GitHub
Kemampuan Masa Depan Model AI Teks ke Video
Platform seperti Hugging Face memimpin dalam pengembangan model canggih yang dapat mengubah teks menjadi konten video dinamis berkualitas tinggi. Hal ini membawa kita pada asumsi bahwa - kemampuan masa depan model AI teks-ke-video benar-benar menarik.
Model-model ini siap merevolusi pembuatan konten, membuatnya lebih cepat, lebih efisien, dan lebih mudah diakses daripada sebelumnya. Dengan hanya memasukkan perintah teks, pengguna akan dapat membuat video yang menarik dan disesuaikan yang mewujudkan ide-ide mereka.
Potensi penerapannya sangat luas - mulai dari pemasaran dan periklanan hingga pendidikan dan hiburan. Bayangkan jika Anda dapat membuat video penjelasan atau cerita animasi bermutu profesional hanya dengan mengklik tombol. Penghematan waktu dan biaya bagi bisnis dan kreator akan sangat besar.
Selain itu, seiring dengan peningkatan realisme, koherensi, dan fleksibilitas model teks-ke-video ini, kualitas output akan semakin sulit dibedakan dari video buatan manusia. Demokratisasi produksi video ini akan memberdayakan lebih banyak orang untuk berbagi cerita dan ide mereka dengan dunia.
Masa depan pembuatan konten tidak diragukan lagi adalah teks ke video, dan Hugging Face berada di garis depan teknologi transformatif ini. Bersiaplah untuk takjub saat model-model ini melampaui batas-batas yang mungkin.
Penutup
Sebagai kesimpulan, Huggingface menawarkan beragam model untuk tugas mengubah teks menjadi video, yang masing-masing memiliki keunggulan unik dalam menghasilkan konten visual dinamis dari deskripsi tekstual. Apakah Anda mengutamakan presisi, kreativitas, atau skalabilitas, model-model ini menyediakan solusi tangguh untuk berbagai aplikasi, yang menjanjikan kemajuan dalam sintesis video berbasis AI.







