
L'essor de la technologie de conversion de texte en vidéo basée sur l'IA révolutionne la façon dont nous créons et consommons du contenu. À l'avant-garde de cette transformation se trouvent les puissants modèles Hugging Face, qui deviennent rapidement les outils incontournables des créateurs de contenu et des entreprises.

Ces modèles linguistiques de pointe, formés à partir de vastes volumes de données, possèdent la capacité remarquable de traduire un texte écrit en récits visuels captivants. En tirant parti des dernières avancées en matière de traitement du langage naturel et d'IA générative, les modèles Hugging Face peuvent transformer sans effort vos mots en vidéos attrayantes et de haute qualité qui captivent votre public.
Comprendre la technologie de conversion de texte en vidéo
Les modèles de conversion de texte en vidéo transforment les descriptions écrites en images animées. Ces modèles comprennent le texte et le convertissent en une séquence d'images qui illustrent la scène ou l'action décrite. Ce processus implique plusieurs étapes, notamment l'analyse du texte, la génération de contenu visuel et le séquençage des images. Chaque étape nécessite des algorithmes complexes pour garantir que la vidéo de sortie représente avec précision le texte d'entrée.
Le parcours de la technologie de conversion de texte en vidéo a commencé avec de simples descriptions textuelles générant des animations de base. Les premiers modèles se concentraient sur la création d'images statiques, mais les progrès de l'IA et de l'apprentissage automatique ont permis le développement de la génération de vidéos dynamiques. Au fil des ans, les chercheurs ont intégré des réseaux neuronaux sophistiqués, ce qui a conduit à des améliorations significatives de la qualité et du réalisme des vidéos. Ces avancées ont ouvert de nouvelles possibilités de création de contenu créatif et de diverses applications dans tous les secteurs.
Les 5 meilleurs modèles d'IA de conversion de texte en vidéo de Huggingface
Nous avons ici les 5 meilleurs modèles de conversion de texte en vidéo d'IA de huggingface. Ces modèles sont très populaires pour leurs fonctionnalités distinctes et comptent le plus grand nombre de téléchargements.
ModèleScope - 1.7b
Le modèle de synthèse texte-vidéo de ModelScope utilise un processus de diffusion en plusieurs étapes pour générer des vidéos à partir de descriptions textuelles. Ce modèle avancé ne prend en charge que la saisie en anglais et est conçu à des fins de recherche. Il se compose de trois sous-réseaux: extraction de caractéristiques textuelles, diffusion de l'espace latent texte-vidéo et mappage de l'espace latent vidéo vers l'espace visuel.
Avec 1,7 milliard de paramètres et une structure UNet3D, il élimine de manière itérative le bruit gaussien pour créer des vidéos. Ce modèle convient à diverses applications, comme la création de vidéos à partir de texte anglais arbitraire. Cependant, il présente des limites, telles que des biais liés aux données d'entraînement et une incapacité à produire des vidéos de qualité cinématographique ou du texte clair. Les utilisateurs doivent éviter de générer du contenu nuisible ou faux. Le modèle a été formé sur des ensembles de données publics, notamment LAION5B, ImageNet et Webvid.
Caractéristiques principales
- Procédé de diffusion en plusieurs étapes
- Prise en charge du texte en anglais
- 1,7 milliard de paramètres
- Architecture UNet3D
- Méthode itérative de débruitage
- Objectif de la recherche
- Formation sur les jeux de données publics
- Génération de texte arbitraire
AnimateDiff-Lightning
AnimateDiff-Lightning est un modèle de génération de texte en vidéo de pointe qui offre des améliorations de vitesse par rapport à l'AnimateDiff original, générant des vidéos plus de dix fois plus rapidement. Développé à partir d'AnimateDiff SD1.5 v2, ce modèle est disponible en versions 1 étape, 2 étapes, 4 étapes et 8 étapes, les modèles à étapes plus élevées offrant une qualité supérieure. Il excelle lorsqu'il est utilisé avec des modèles de base stylisés comme epicCRealism et Realistic Vision, ainsi qu'avec des modèles d'anime et de dessin animé tels que ToonYou et Mistoon Anime.
Les utilisateurs peuvent obtenir des résultats optimaux en expérimentant différents paramètres, comme l'utilisation de Motion LoRA. Pour la mise en œuvre, le modèle peut être utilisé avec des diffuseurs et ComfyUI. Il prend en charge la génération de vidéo à vidéo avec ControlNet pour une sortie améliorée. Pour plus de détails et une démonstration, les utilisateurs sont encouragés à se référer au document de recherche : AnimateDiff-Lightning : Distillation par diffusion inter-modèles
Caractéristiques principales
- Génération de vidéos ultra-rapide
- Distillé à partir d'AnimateDiff
- Points de contrôle à plusieurs étapes
- Haute qualité de production
- Prend en charge les modèles stylisés
- Prise en charge des LoRA de mouvement
- Options réalistes et de dessin animé
- Génération de vidéo à vidéo
Zéroscope V2
Le modèle vidéo zeroscope_v2_567w basé sur Modelscope excelle dans la création de vidéos 16:9 de haute qualité sans filigrane. Formé sur 9923 clips et 29769 images étiquetées à une résolution de 576x320 et 24 images par seconde, il est idéal pour une sortie vidéo fluide. Ce modèle est conçu pour le rendu initial avant la mise à l'échelle avec zeroscope_v2_XL en utilisant vid2vid dans l'extension text2video 1111, permettant une exploration efficace à des résolutions inférieures.
La mise à l'échelle vers 1024x576 offre des compositions de qualité supérieure. Il utilise 7,9 Go de VRAM pour le rendu de 30 images. Pour l'utiliser, téléchargez et remplacez les fichiers dans le répertoire approprié.
Pour de meilleurs résultats, effectuez une mise à l'échelle à l'aide de zeroscope_v2_XL avec une intensité de réduction du bruit comprise entre 0,66 et 0,85. Les problèmes connus incluent une sortie sous-optimale à des résolutions inférieures ou avec moins d'images. Le modèle peut être facilement intégré à l'aide de diffuseurs avec des étapes d'installation et de génération de vidéo simples.
Caractéristiques principales
- Sortie sans filigrane
- 16:9 de haute qualité
- Sortie vidéo fluide
- Résolution 576x320
- 24 images par seconde
- Mise à l'échelle efficace
- Utilisation de 7,9 Go de VRAM
- Intégration facile
VGen
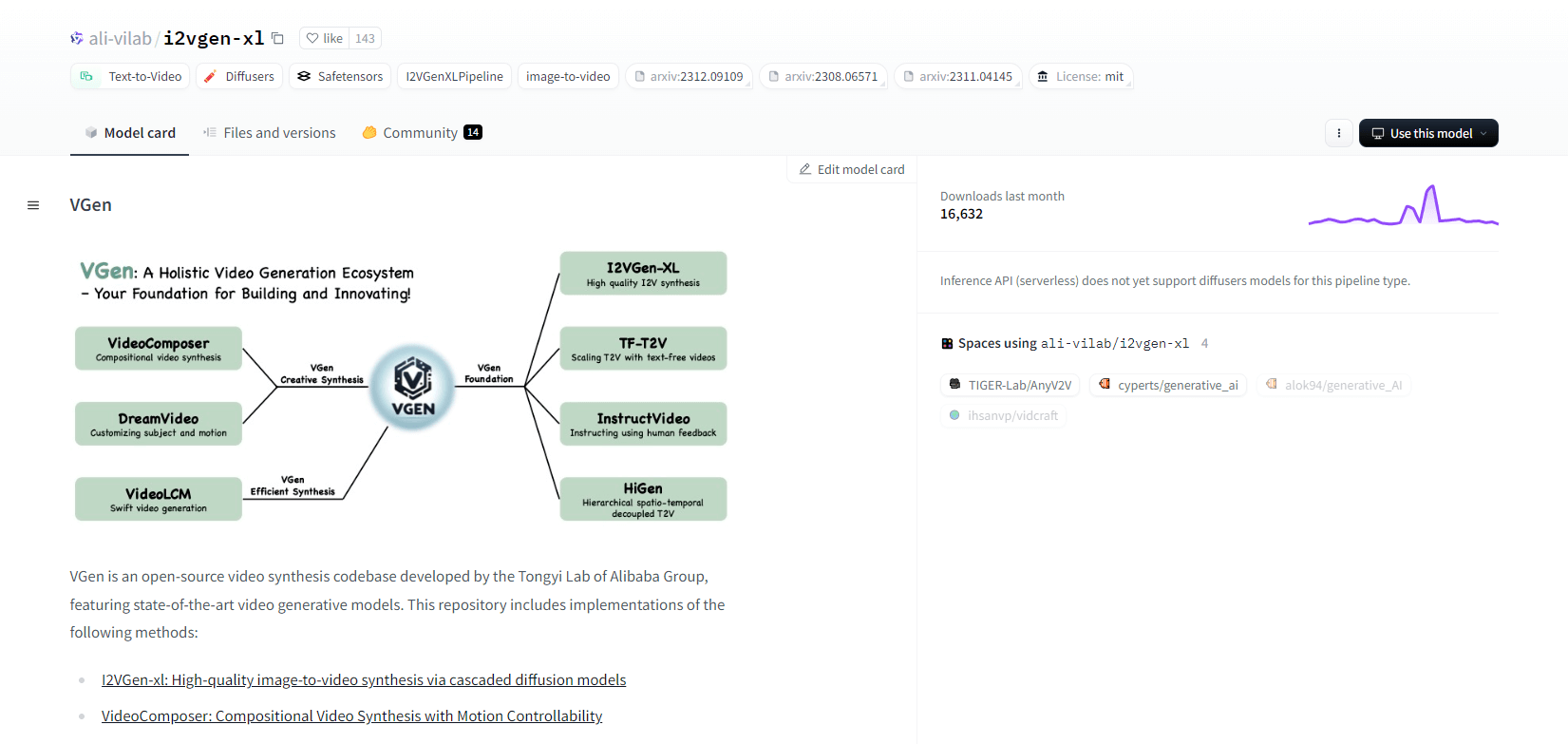
VGen, une base de code de synthèse vidéo open source du laboratoire Tongyi d'Alibaba, propose des modèles de génération vidéo avancés. Il comprend des méthodes telles que I2VGen-xl pour la synthèse d'image en vidéo de haute qualité, VideoComposer pour la synthèse vidéo contrôlable par le mouvement, et bien plus encore. VGen peut créer des vidéos de haute qualité à partir de texte, d'images, de mouvements souhaités, de sujets et de signaux de rétroaction. Le référentiel propose des outils de visualisation, d'échantillonnage, d'entraînement, d'inférence et d'entraînement conjoint à l'aide d'images et de vidéos. Les mises à jour récentes incluent VideoLCM, I2VGen-XL et la méthode DreamVideo.
VGen excelle en termes d'évolutivité, de performances et d'exhaustivité. L'installation implique la configuration d'un environnement Python et des bibliothèques nécessaires. Les utilisateurs peuvent former des modèles texte-vidéo et exécuter I2VGen-XL pour la génération de vidéos haute définition. Des jeux de données de démonstration et des modèles pré-entraînés sont disponibles pour faciliter l'expérimentation et l'optimisation. La base de code garantit une gestion facile et une grande efficacité dans les tâches de synthèse vidéo.
Caractéristiques principales
- Base de code open source
- Synthèse de haute qualité
- Contrôle du mouvement
- Génération de texte en vidéo
- Conversion d'image en vidéo
- Cadre extensible
- Modèles pré-entraînés
- Des outils complets
Hotshot XL
Hotshot-XL, un modèle d'IA de conversion de texte en GIF développé par Natural Synthetics Inc., fonctionne de manière transparente avec Stable Diffusion XL. Il permet la génération de GIF à l'aide de n'importe quel modèle SDXL affiné, simplifiant la création de GIF personnalisés sans réglage supplémentaire. Ce modèle excelle dans la génération de GIF d'une seconde à 8 images par seconde dans différents rapports hauteur/largeur. Il exploite la diffusion latente avec des encodeurs de texte pré-entraînés (OpenCLIP-ViT/G et CLIP-ViT/L) pour des performances améliorées.
Les utilisateurs peuvent modifier les compositions GIF à l'aide de SDXL ControlNet pour des mises en page personnalisées. Bien que capable de créer des GIF polyvalents, Hotshot-XL est confronté à des défis liés au photoréalisme et à des tâches complexes telles que le rendu de compositions spécifiques. L'implémentation du modèle vise à s'intégrer en douceur dans les flux de travail existants et est disponible pour exploration sur GitHub sous une licence CreativeML Open RAIL++-M.
Caractéristiques principales
- Génération de texte en GIF
- Fonctionne avec SDXL
- Génère des GIF d'une seconde
- Prend en charge divers rapports hauteur/largeur
- Utilisations de la diffusion latente
- Encodeurs de texte pré-entraînés
- Personnalisable avec ControlNet
- Disponible sur GitHub
Capacités futures des modèles d'IA de conversion de texte en vidéo
Des plateformes comme Hugging Face ouvrent la voie au développement de modèles avancés capables de transformer du texte en contenu vidéo dynamique de haute qualité. Cela nous amène à penser que les capacités futures des modèles d'IA de conversion de texte en vidéo sont vraiment passionnantes.
Ces modèles sont sur le point de révolutionner la création de contenu, la rendant plus rapide, plus efficace et plus accessible que jamais. En saisissant simplement une invite de texte, les utilisateurs pourront générer des vidéos attrayantes et personnalisées qui donneront vie à leurs idées.
Les applications potentielles sont vastes : du marketing et de la publicité à l'éducation et au divertissement. Imaginez pouvoir créer des vidéos explicatives ou des histoires animées de qualité professionnelle en un seul clic. Les économies de temps et d'argent pour les entreprises et les créateurs seront substantielles.
De plus, à mesure que ces modèles de conversion de texte en vidéo continueront de s’améliorer en termes de réalisme, de cohérence et de flexibilité, la qualité du résultat deviendra de plus en plus indiscernable de celle d’une vidéo créée par l’homme. Cette démocratisation de la production vidéo permettra à davantage de personnes de partager leurs histoires et leurs idées avec le monde.
L'avenir de la création de contenu est sans aucun doute la conversion de texte en vidéo, et Hugging Face est à l'avant-garde de cette technologie transformatrice. Préparez-vous à être surpris par ces modèles qui repoussent les limites du possible.
Pour conclure
En conclusion, Huggingface propose une gamme variée de modèles pour les tâches de conversion de texte en vidéo, chacun apportant des atouts uniques dans la génération de contenu visuel dynamique à partir de descriptions textuelles. Que vous privilégiiez la précision, la créativité ou l'évolutivité, ces modèles fournissent des solutions robustes pour diverses applications, promettant des avancées dans la synthèse vidéo pilotée par l'IA.








