
El auge de la tecnología de conversión de texto a video impulsada por IA está revolucionando la forma en que creamos y consumimos contenido. A la vanguardia de esta transformación se encuentran los poderosos modelos Hugging Face, que rápidamente se están convirtiendo en las herramientas preferidas tanto de los creadores de contenido como de las empresas.

Estos modelos de lenguaje de última generación, entrenados con grandes cantidades de datos, poseen la notable capacidad de traducir texto escrito en narrativas visuales cautivadoras. Al aprovechar los últimos avances en procesamiento de lenguaje natural e inteligencia artificial generativa, los modelos Hugging Face pueden transformar sin esfuerzo sus palabras en videos atractivos y de alta calidad que cautivarán a su audiencia.
Comprender la tecnología de texto a vídeo
Los modelos de texto a video transforman las descripciones escritas en imágenes en movimiento. Estos modelos entienden el texto y lo convierten en una secuencia de fotogramas que representan la escena o la acción descrita. Este proceso implica varios pasos, que incluyen el análisis del texto, la generación de contenido visual y la secuenciación de fotogramas. Cada paso requiere algoritmos complejos para garantizar que el video de salida represente con precisión el texto de entrada.
El camino hacia la tecnología de conversión de texto a vídeo comenzó con descripciones de texto sencillas que generaban animaciones básicas. Los primeros modelos se centraban en la creación de imágenes estáticas, pero los avances en inteligencia artificial y aprendizaje automático han permitido el desarrollo de la generación de vídeos dinámicos. A lo largo de los años, los investigadores han integrado redes neuronales sofisticadas, lo que ha dado lugar a mejoras significativas en la calidad y el realismo del vídeo. Estos avances han abierto nuevas posibilidades para la creación de contenidos creativos y diversas aplicaciones en distintos sectores.
Los 5 mejores modelos de IA para convertir texto a video de Huggingface
Aquí tenemos los 5 mejores modelos de texto a video con IA de Huggingface. Estos modelos son muy populares por su funcionalidad distintiva y tienen la mayor cantidad de descargas.
Modelo Scope - 1.7b
El modelo de síntesis de texto a video de ModelScope utiliza un proceso de difusión de varias etapas para generar videos a partir de descripciones de texto. Este modelo avanzado solo admite entradas en inglés y está diseñado para fines de investigación. Consta de tres subredes: extracción de características de texto, difusión del espacio latente de texto a video y mapeo del espacio latente de video al espacio visual.
Con 1.700 millones de parámetros y una estructura UNet3D, elimina de forma iterativa el ruido gaussiano para crear vídeos. Este modelo es adecuado para diversas aplicaciones, como la creación de vídeos a partir de texto arbitrario en inglés. Sin embargo, tiene limitaciones, como sesgos de los datos de entrenamiento y la incapacidad de producir vídeos de alta calidad a nivel de película o texto claro. Los usuarios deben evitar generar contenido dañino o falso. El modelo se entrenó en conjuntos de datos públicos, incluidos LAION5B, ImageNet y Webvid.
Características principales
- Proceso de difusión en múltiples etapas
- Soporte de texto en inglés
- 1.7 mil millones de parámetros
- Arquitectura UNet3D
- Método iterativo de eliminación de ruido
- Enfoque del propósito de la investigación
- Formación sobre conjuntos de datos públicos
- Generación de texto arbitrario
AnimateDiff-Relámpago
AnimateDiff-Lightning es un modelo de generación de texto a video de vanguardia que ofrece mejoras de velocidad con respecto al AnimateDiff original, lo que permite generar videos diez veces más rápido. Desarrollado a partir de AnimateDiff SD1.5 v2, este modelo está disponible en versiones de 1, 2, 4 y 8 pasos, y los modelos de más pasos ofrecen una calidad superior. Se destaca cuando se utiliza con modelos básicos estilizados como epiCRealism y Realistic Vision, así como con modelos de anime y dibujos animados como ToonYou y Mistoon Anime.
Los usuarios pueden lograr resultados óptimos experimentando con diferentes configuraciones, como el uso de Motion LoRAs. Para la implementación, el modelo se puede utilizar con difusores y ComfyUI. Admite la generación de video a video con ControlNet para una salida mejorada. Para obtener más detalles y una demostración, se recomienda a los usuarios consultar el artículo de investigación: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Características principales
- Generación de vídeo ultrarrápida
- Destilado de AnimateDiff
- Puestos de control de varios pasos
- Alta calidad de generación
- Admite modelos estilizados
- Compatibilidad con LoRA de movimiento
- Opciones realistas y de dibujos animados.
- Generación de vídeo a vídeo
Zeroscope V2
El modelo de video zeroscope_v2_567w basado en Modelscope se destaca en la creación de videos 16:9 de alta calidad sin marcas de agua. Entrenado con 9923 clips y 29769 cuadros etiquetados a una resolución de 576x320 y 24 cuadros por segundo, es ideal para una salida de video fluida. Este modelo está diseñado para la renderización inicial antes de escalar con zeroscope_v2_XL usando vid2vid en la extensión 1111 text2video, lo que permite una exploración eficiente a resoluciones más bajas.
La ampliación a 1024x576 permite composiciones superiores. Utiliza 7,9 GB de VRAM para renderizar 30 fotogramas. Para utilizarlo, descargue y reemplace los archivos en el directorio correspondiente.
Para obtener mejores resultados, utilice zeroscope_v2_XL con una intensidad de reducción de ruido entre 0,66 y 0,85. Entre los problemas conocidos se incluyen resultados subóptimos en resoluciones más bajas o menos cuadros. El modelo se puede integrar fácilmente utilizando difusores con pasos de instalación y generación de video simples.
Características principales
- Salida sin marca de agua
- 16:9 de alta calidad
- Salida de vídeo fluida
- Resolución 576x320
- 24 cuadros por segundo
- Ampliación de escala eficiente
- Uso de VRAM de 7,9 GB
- Fácil integración
VGen
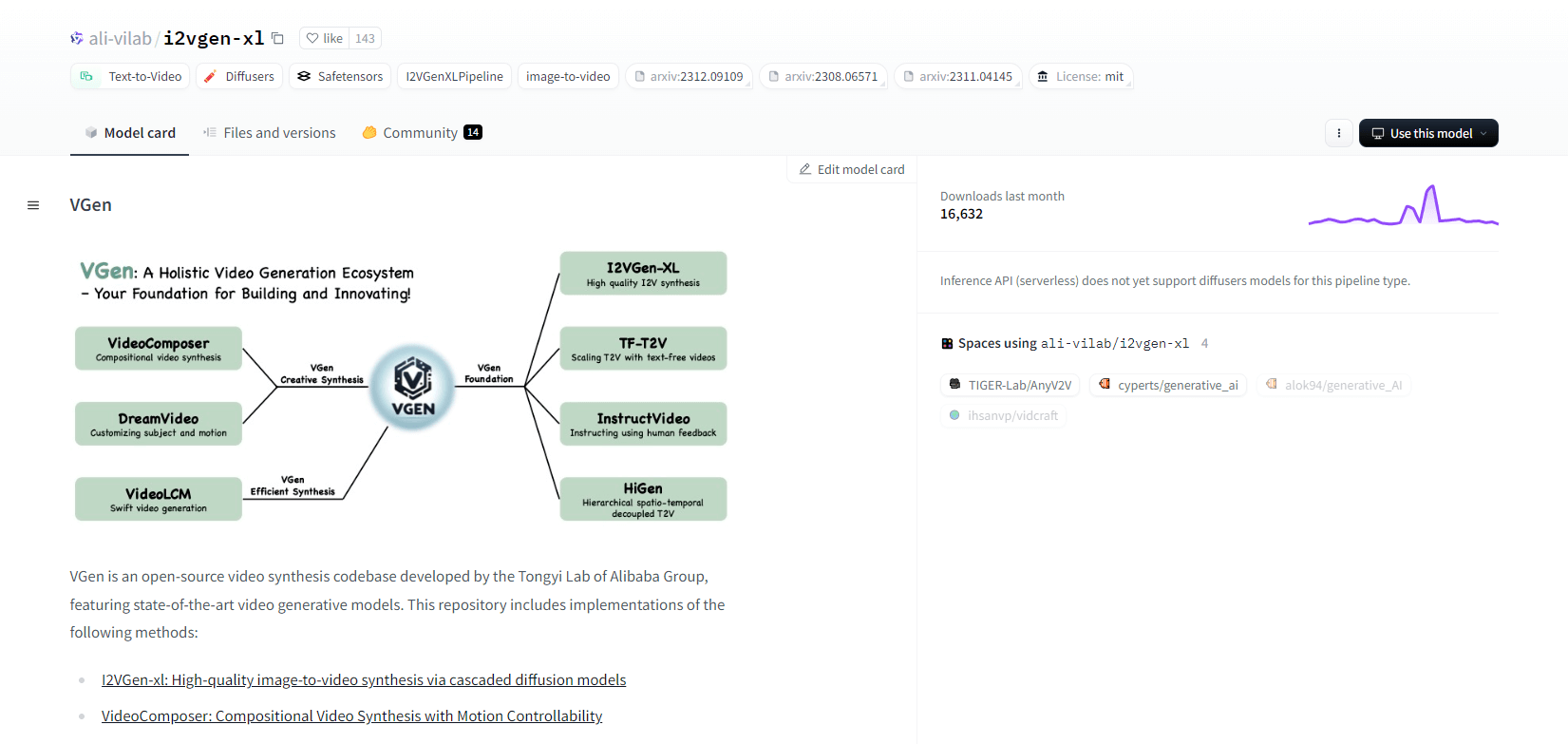
VGen, una base de código de síntesis de video de código abierto del Laboratorio Tongyi de Alibaba, ofrece modelos generativos de video avanzados. Incluye métodos como I2VGen-xl para síntesis de imagen a video de alta calidad, VideoComposer para síntesis de video controlable por movimiento y más. VGen puede crear videos de alta calidad a partir de texto, imágenes, movimientos deseados, sujetos y señales de retroalimentación. El repositorio cuenta con herramientas para visualización, muestreo, entrenamiento, inferencia y entrenamiento conjunto utilizando imágenes y videos. Las actualizaciones recientes incluyen VideoLCM, I2VGen-XL y el método DreamVideo.
VGen se destaca por su capacidad de expansión, rendimiento y completitud. La instalación implica configurar un entorno Python y las bibliotecas necesarias. Los usuarios pueden entrenar modelos de conversión de texto a video y ejecutar I2VGen-XL para generar videos de alta definición. Hay conjuntos de datos de demostración y modelos entrenados previamente disponibles para facilitar la experimentación y la optimización. La base de código garantiza una administración sencilla y una alta eficiencia en las tareas de síntesis de video.
Características principales
- Base de código fuente abierta
- Síntesis de alta calidad
- Controlabilidad del movimiento
- Generación de texto a vídeo
- Conversión de imagen a vídeo
- Marco expandible
- Modelos pre-entrenados
- Herramientas integrales
Tiro caliente XL
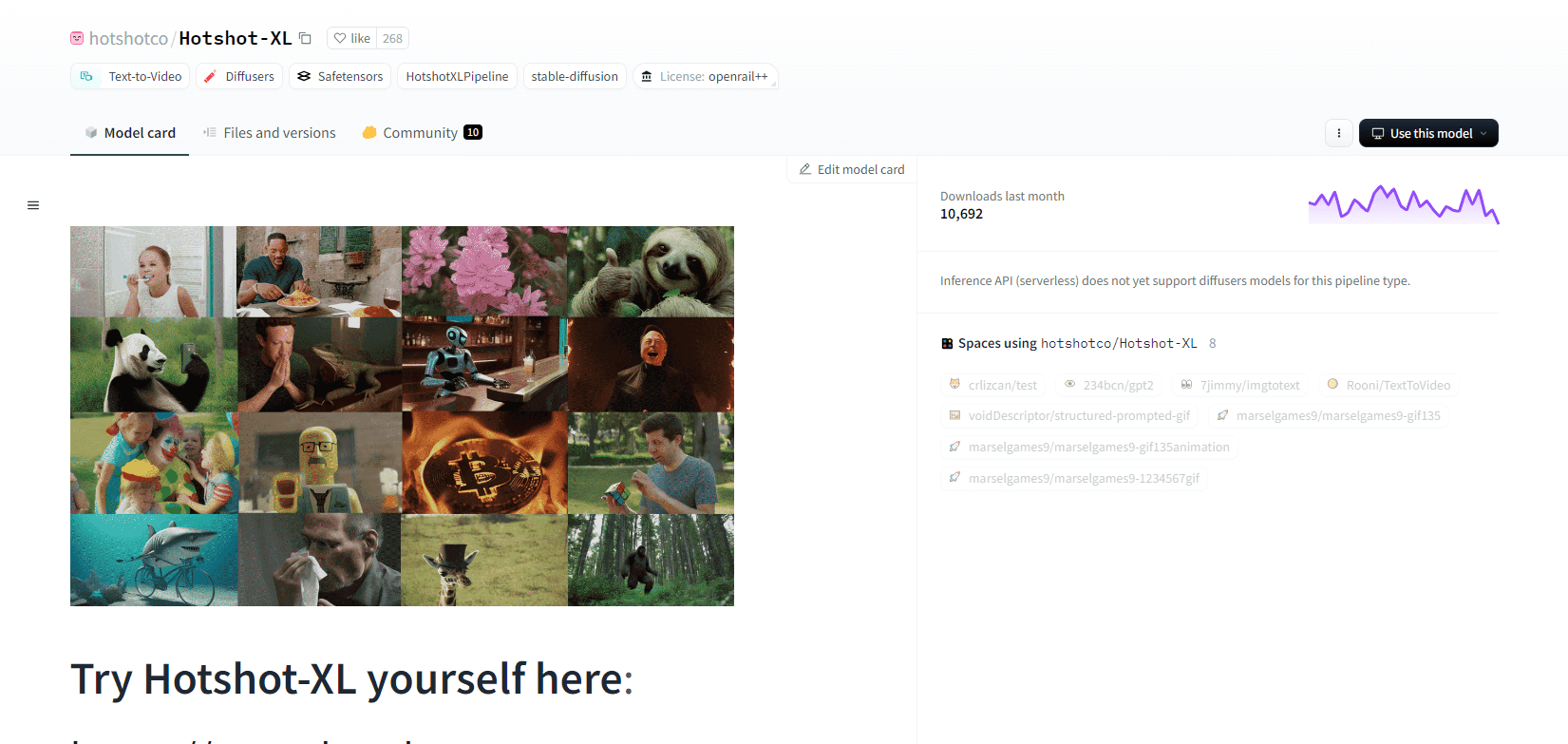
Hotshot-XL, un modelo de texto a GIF con IA desarrollado por Natural Synthetics Inc., funciona a la perfección con Stable Diffusion XL. Permite la generación de GIF utilizando cualquier modelo SDXL ajustado, lo que simplifica la creación de GIF personalizados sin ajustes adicionales. Este modelo se destaca en la generación de GIF de 1 segundo a 8 cuadros por segundo en varias relaciones de aspecto. Aprovecha Latent Diffusion con codificadores de texto entrenados previamente (OpenCLIP-ViT/G y CLIP-ViT/L) para un rendimiento mejorado.
Los usuarios pueden modificar composiciones GIF mediante SDXL ControlNet para obtener diseños personalizados. Si bien es capaz de crear GIF de forma versátil, Hotshot-XL enfrenta desafíos con el fotorrealismo y tareas complejas como la representación de composiciones específicas. La implementación del modelo apunta a integrarse sin problemas en los flujos de trabajo existentes y está disponible para su exploración en GitHub bajo una licencia CreativeML Open RAIL++-M.
Características principales
- Generación de texto a GIF
- Funciona con SDXL
- Genera GIF de 1 segundo
- Admite varias relaciones de aspecto
- Usos de difusión latente
- Codificadores de texto preentrenados
- Personalizable con ControlNet
- Disponible en GitHub
Capacidades futuras de los modelos de IA de conversión de texto a vídeo
Plataformas como Hugging Face están a la vanguardia en el desarrollo de modelos avanzados que pueden transformar texto en contenido de video dinámico de alta calidad. Esto nos lleva a suponer que las futuras capacidades de los modelos de IA de conversión de texto a video son realmente emocionantes.
Estos modelos están preparados para revolucionar la creación de contenido, haciéndola más rápida, eficiente y accesible que nunca. Con solo ingresar un mensaje de texto, los usuarios podrán generar videos atractivos y personalizados que den vida a sus ideas.
Las posibles aplicaciones son muchas: desde marketing y publicidad hasta educación y entretenimiento. Imagine poder crear videos explicativos de calidad profesional o historias animadas con solo hacer clic en un botón. El ahorro de tiempo y dinero para las empresas y los creadores será sustancial.
Además, a medida que estos modelos de conversión de texto a vídeo sigan mejorando en términos de realismo, coherencia y flexibilidad, la calidad del resultado será cada vez más indistinguible de la del vídeo creado por personas. Esta democratización de la producción de vídeo permitirá a más personas compartir sus historias e ideas con el mundo.
El futuro de la creación de contenido es, sin duda, la conversión de texto a vídeo, y Hugging Face está a la vanguardia de esta tecnología transformadora. Prepárese para sorprenderse mientras estos modelos amplían los límites de lo posible.
Terminando
En conclusión, Huggingface ofrece una amplia gama de modelos para tareas de conversión de texto a video, cada uno de los cuales aporta ventajas únicas para generar contenido visual dinámico a partir de descripciones textuales. Ya sea que priorice la precisión, la creatividad o la escalabilidad, estos modelos brindan soluciones sólidas para diversas aplicaciones y prometen avances en la síntesis de video impulsada por IA.








