
Stable Diffusion hat die Welt der generativen KI im Sturm erobert und ermöglicht es Benutzern, aus einfachen Textaufforderungen hochdetaillierte und realistische Bilder zu generieren.

Zwar gibt es Online-Tools wie DreamStudio und Hugging Face, die Zugriff auf Stable Diffusion bieten, doch die lokale Ausführung auf Ihrem eigenen Server bietet mehrere Vorteile.
Indem Sie Stable Diffusion auf Ihrem Server hosten, erhalten Sie eine größere Kontrolle über die Parameter und Anpassungen des Modells und stellen sicher, dass die generierten Bilder besser Ihren spezifischen Anforderungen entsprechen.
Darüber hinaus müssen Sie sich durch die lokale Ausführung des Modells nicht mehr auf Dienste von Drittanbietern verlassen, was Ihnen mehr Privatsphäre und Datensouveränität bietet. In diesem Artikel führen wir Sie durch den Prozess der Einrichtung und Ausführung von Stable Diffusion auf Ihrem Server, damit Sie das volle Potenzial dieses leistungsstarken generativen KI-Tools ausschöpfen können.
Erstellen Sie erstaunliche Websites
Mit dem besten kostenlosen Seite Builder Elementor
Jetzt anfangenArbeitsprozess des stabilen Diffusionsmodells
Stabile Diffusion fällt in die Klasse der Deep-Learning-Modelle, die als Diffusionsmodelle bekannt sind. Dabei handelt es sich um generative Modelle, d. h. sie werden trainiert, um neue Daten zu generieren, die denen ähneln, die sie aus den Trainingsdaten gelernt haben.
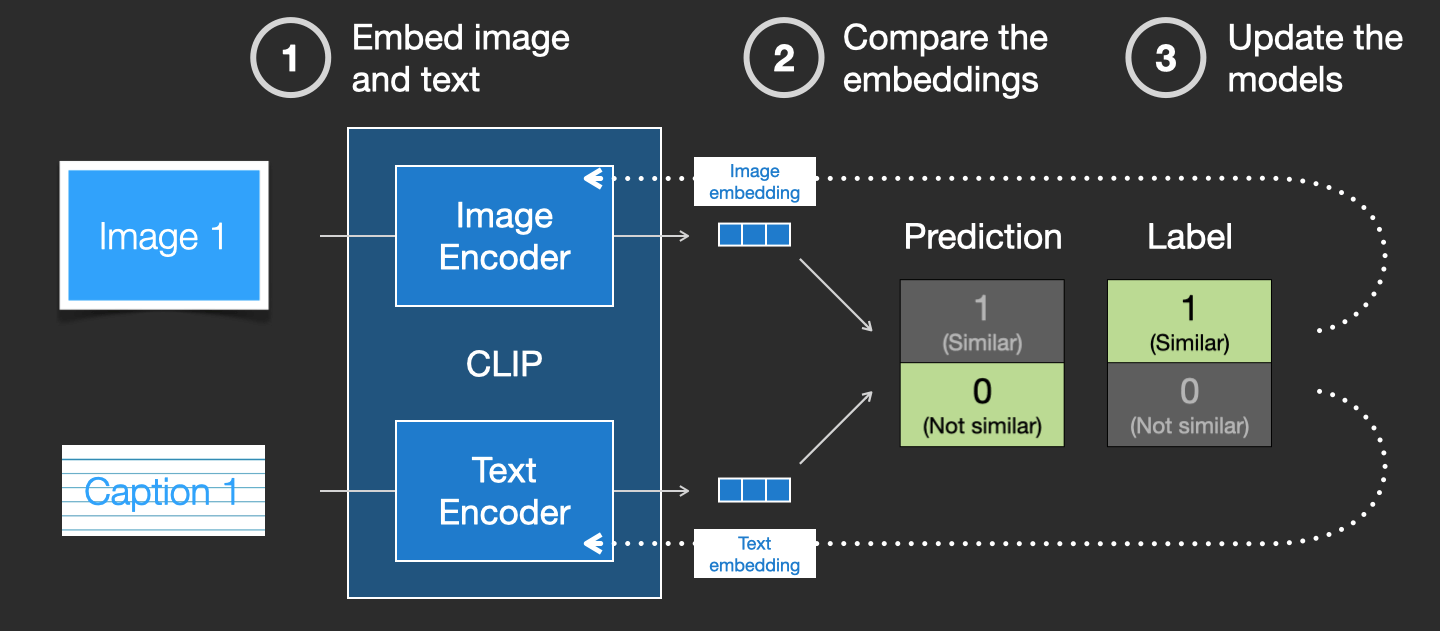
Das Modell wird aufgrund seiner mathematischen Ähnlichkeiten mit dem physikalischen Prozess der Diffusion „Diffusion“ genannt. Es funktioniert, indem mit reinem Rauschen (zufälligen Pixeln) begonnen wird und dieses Rauschen schrittweise in vielen Schritten in Richtung des Zielbildes korrigiert wird, wobei die bereitgestellte Texteingabeaufforderung verwendet wird.
Die wichtigste Neuerung von Stable Diffusion besteht darin, dass es sich um ein latentes Diffusionsmodell handelt. Anstatt direkt im Pixelraum zu arbeiten, arbeitet es in einem komprimierten latenten Raum, der von einem vorherigen Bild-zu-Latent-Encodermodell erlernt wurde. Diese komprimierte Darstellung ermöglicht effizientes Lernen und Generieren.
Im Großen und Ganzen funktioniert der Prozess wie folgt:
- Die Textaufforderung wird mithilfe eines Kodierungsmodells wie CLIP in eine Texteinbettung kodiert.
- Zufälliges Rauschen wird im latenten Raum abgetastet.
- Das Rauschen wird durch mehrere Diffusionsschritte schrittweise in Richtung der Zielbildverteilung korrigiert, abhängig von der Texteinbettung.
- Schließlich wird das entrauschte latente Bild durch einen Decoder geleitet, um das Ausgabebild zu erzeugen.
Dieser iterative Rauschminderungsprozess ermöglicht es dem Modell, zusammenhängende Bilder zu erzeugen, die der Beschreibung des Eingabetexts genau entsprechen. Das Training nutzt fortgeschrittene Techniken wie die klassifikatorfreie Anleitung, um die Qualität der Bild-Text-Ausrichtung zu verbessern.
Ausführen einer stabilen Diffusion auf einem lokalen Server
Mit Stable Diffusion auf Ihrem Computer können Sie verschiedene Texteingaben ausprobieren und Bilder erstellen, die Ihren Anforderungen besser entsprechen. Außerdem können Sie das Modell mit Ihren eigenen Daten anpassen, um die Ergebnisse basierend auf Ihren Eingaben zu verbessern.
Hinweis: Zum stabilen Ausführen von Diffusion auf Ihrem PC ist eine GPU erforderlich.
Python- und Git-Installation
Um Stable Diffusion auszuführen, muss Python 3.10.6 auf Ihrem Computer installiert sein. Sie können es von der offiziellen Python-Website installieren.
Um zu bestätigen, dass die Installation erfolgreich war, öffnen Sie die Eingabeaufforderung, geben Sie „ python “ ein und drücken Sie die Eingabetaste. Daraufhin sollte die von Ihnen installierte Python-Version angezeigt werden.
Denken Sie daran, dass dies die einzige Version ist, mit der Sie fortfahren sollten.
Installieren Sie dann das Code-Repository-Verwaltungssystem Git .
GitHub und Hugging Face-Konto
GitHub ist ein Ort, an dem Entwickler ihren Code speichern und gemeinsam an Softwareprojekten arbeiten. Sie verwenden es, um Änderungen zu verfolgen und mit anderen zusammenzuarbeiten.
Auf der anderen Seite ist Hugging Face eine Community, die sich auf KI konzentriert und Menschen dazu ermutigt, zu Open-Source-Projekten beizutragen. Es ist wie ein zentraler Knotenpunkt für verschiedene Modelle, beispielsweise für die Verarbeitung natürlicher Sprache und Computervision. Um die neueste Version von Stable Diffusion herunterzuladen, müssen Sie ein Konto erstellen, aber darauf gehen wir später ein.
Stabiles Diffusion-Web-UI-Klonen
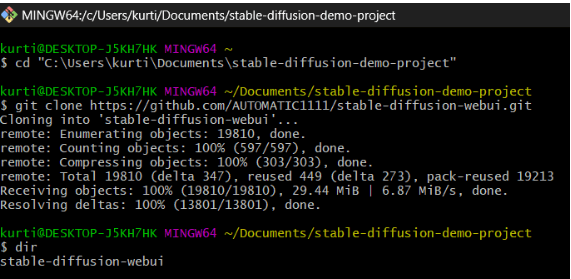
Dieser Schritt ist entscheidend, kann aber etwas knifflig werden. Wir müssen lediglich das Basis-Setup der stabilen Diffusion-Installation auf unseren Computer herunterladen. Es ist hilfreich, einen Ordner (wie „stable-diffusion-demo-project“) zu erstellen, in den das Repository heruntergeladen werden kann, aber das ist nicht zwingend erforderlich.
Um diesen Schritt abzuschließen, benötigen Sie Git Bash. Gehen Sie einfach mit dem folgenden Befehl zu dem Ordner, in dem Sie die stabile Diffusion-Web-Benutzeroberfläche klonen möchten:
cd path/to/folder Dann sollten Sie den unten angegebenen Befehl ausführen -
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitWenn alles gut gegangen ist, sehen Sie einen Ordner mit dem Namen „stable-diffusion-webui“.
Herunterladen des stabilen Diffusionsmodells
Melden Sie sich zunächst bei Ihrem Hugging Face-Konto an. Laden Sie dann ein stabiles Diffusionsmodell herunter . Dies kann einige Minuten dauern, da es sich um eine große Datei handelt.
Sobald es heruntergeladen ist, gehen Sie zum Ordner „models“ im Ordner der stabilen Diffusion-Weboberfläche. Darin finden Sie einen Ordner namens „stable-diffusion“ mit einer Textdatei namens „Put Stable Diffusion Checkpoints here“.
Verschieben Sie nun einfach das heruntergeladene stabile Diffusionsmodell in diesen Ordner.
stable-diffusion-webui\models\Stable-diffusionWeb-UI-Einrichtung
Als nächstes müssen Sie die für eine stabile Diffusion erforderlichen Werkzeuge einrichten. Dies kann etwa 10 Minuten dauern.
cd path/to/stable-diffusion-webuiÖffnen Sie Ihre Eingabeaufforderung und gehen Sie zum Ordner „stable-diffusion-webui“, indem Sie einen bestimmten Befehl eingeben.
webui-user.batFühren Sie dort einen weiteren Befehl aus, um eine virtuelle Umgebung zu erstellen und alles zu installieren, was für den Vorgang erforderlich ist.
Beginnen Sie mit der stabilen Diffusion
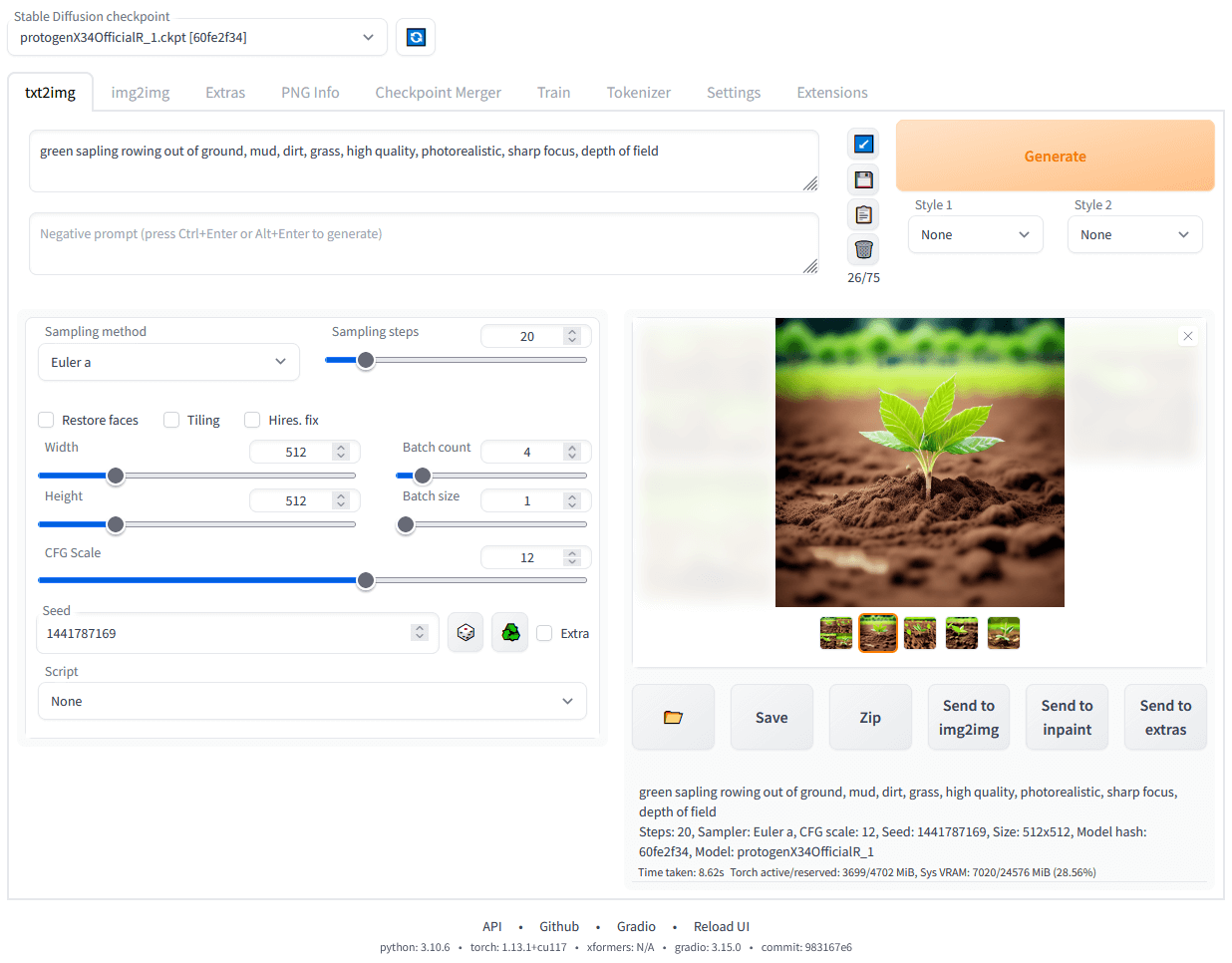
Sobald Sie alle notwendigen Dinge installiert haben, wird in Ihrem Befehlsfenster eine Webadresse wie „http://127.0.0.1:7860“ angezeigt. Kopieren Sie diese einfach und fügen Sie sie in die Adressleiste Ihres Webbrowsers ein, um die Stable Diffusion-Weboberfläche zu verwenden.
Einpacken
Wenn Sie Stable Diffusion auf Ihrem eigenen Server ausführen, entfaltet es sein wahres Potenzial und gibt Ihnen die volle Kontrolle über Anpassungen und Feinabstimmungen.
Mit einer lokalen Installation können Sie das Modell an Ihre individuellen Anforderungen anpassen, mit verschiedenen Eingabeaufforderungen und Techniken experimentieren und die Grenzen der generativen KI erweitern.
Da sich diese Technologie rasant weiterentwickelt, sind Sie mit Stable Diffusion vor Ort ganz vorne mit dabei und können die Zukunft der visuellen Generation gestalten, erneuern und formen. Nutzen Sie die Möglichkeiten verantwortungsbewusst und lassen Sie Ihrer Fantasie in diesem faszinierenden Bereich freien Lauf.



