
Der Aufstieg der KI-gestützten Text-to-Video-Technologie revolutioniert die Art und Weise, wie wir Inhalte erstellen und konsumieren. An der Spitze dieser Transformation stehen die leistungsstarken Hugging Face-Modelle, die sich schnell zu den bevorzugten Tools für Inhaltsersteller und Unternehmen entwickeln.

Diese hochmodernen Sprachmodelle, die anhand riesiger Datenmengen trainiert wurden, verfügen über die bemerkenswerte Fähigkeit, geschriebenen Text in fesselnde visuelle Erzählungen zu übersetzen. Durch die Nutzung der neuesten Fortschritte in der Verarbeitung natürlicher Sprache und der generativen KI können Hugging Face-Modelle Ihre Worte mühelos in ansprechende, qualitativ hochwertige Videos verwandeln, die Ihr Publikum fesseln.
Text-zu-Video-Technologie verstehen
Text-zu-Video-Modelle wandeln schriftliche Beschreibungen in bewegte Bilder um. Diese Modelle verstehen Text und wandeln ihn in eine Bildfolge um, die die beschriebene Szene oder Handlung darstellt. Dieser Prozess umfasst mehrere Schritte, darunter Textanalyse, Generierung visueller Inhalte und Bildsequenzierung. Jeder Schritt erfordert komplexe Algorithmen, um sicherzustellen, dass das Ausgabevideo den Eingabetext genau darstellt.
Die Entwicklung der Text-to-Video-Technologie begann mit einfachen Textbeschreibungen, die einfache Animationen erzeugten. Frühe Modelle konzentrierten sich auf die Erstellung statischer Bilder, doch Fortschritte in der künstlichen Intelligenz und im maschinellen Lernen haben die Entwicklung dynamischer Videogenerierung ermöglicht. Im Laufe der Jahre haben Forscher hochentwickelte neuronale Netzwerke integriert, was zu erheblichen Verbesserungen der Videoqualität und des Realismus geführt hat. Diese Fortschritte haben neue Möglichkeiten für die kreative Inhaltserstellung und verschiedene Anwendungen in verschiedenen Branchen eröffnet.
Die 5 besten Text-zu-Video-KI-Modelle von Huggingface
Hier sind die 5 besten KI-Text-zu-Video-Modelle von huggingface. Diese Modelle sind aufgrund ihrer besonderen Funktionalität sehr beliebt und haben die meisten Downloads.
ModelScope - 1.7b
Das Text-zu-Video-Synthesemodell von ModelScope verwendet einen mehrstufigen Diffusionsprozess, um Videos aus Textbeschreibungen zu generieren. Dieses erweiterte Modell unterstützt nur englische Eingaben und ist für Forschungszwecke konzipiert. Es besteht aus drei Unternetzwerken: Textmerkmalextraktion, Text-zu-Video-Latentraumdiffusion und Video-Latentraum-zu-visuellem Raum-Mapping.
Mit 1,7 Milliarden Parametern und einer UNet3D-Struktur entfernt es iterativ Gaußsches Rauschen, um Videos zu erstellen. Dieses Modell eignet sich für verschiedene Anwendungen, beispielsweise zum Erstellen von Videos aus beliebigem englischen Text. Es weist jedoch Einschränkungen auf, beispielsweise Verzerrungen durch Trainingsdaten und die Unfähigkeit, qualitativ hochwertige Videos auf Filmniveau oder klaren Text zu erstellen. Benutzer müssen die Generierung schädlicher oder falscher Inhalte vermeiden. Das Modell wurde anhand öffentlicher Datensätze trainiert, darunter LAION5B, ImageNet und Webvid.
Hauptmerkmale
- Mehrstufiger Diffusionsprozess
- Englische Textunterstützung
- 1,7 Milliarden Parameter
- UNet3D-Architektur
- Iterative Rauschunterdrückungsmethode
- Forschungszielschwerpunkt
- Training zu öffentlichen Datensätzen
- Beliebige Textgenerierung
AnimateDiff-Blitz
AnimateDiff-Lightning ist ein hochmodernes Modell zur Text-zu-Video-Generierung, das im Vergleich zum ursprünglichen AnimateDiff schnellere Geschwindigkeiten bietet und Videos mehr als zehnmal schneller generiert. Dieses aus AnimateDiff SD1.5 v2 entwickelte Modell ist in den Versionen 1-Schritt, 2-Schritt, 4-Schritt und 8-Schritt verfügbar, wobei die Modelle mit mehr Schritten eine bessere Qualität bieten. Es eignet sich hervorragend für die Verwendung mit stilisierten Basismodellen wie epiCRealism und Realistic Vision sowie Anime- und Cartoon-Modellen wie ToonYou und Mistoon Anime.
Benutzer können optimale Ergebnisse erzielen, indem sie mit verschiedenen Einstellungen experimentieren, z. B. durch die Verwendung von Motion LoRAs. Zur Implementierung kann das Modell mit Diffusoren und ComfyUI verwendet werden. Es unterstützt die Video-zu-Video-Generierung mit ControlNet für eine verbesserte Ausgabe. Weitere Einzelheiten und eine Demo finden Sie im Forschungspapier: AnimateDiff-Lightning: Cross-Model Diffusion Distillation
Hauptmerkmale
- Blitzschnelle Videogenerierung
- Destilliert aus AnimateDiff
- Mehrstufige Kontrollpunkte
- Hohe Erzeugungsqualität
- Unterstützt stilisierte Modelle
- Motion LoRAs-Unterstützung
- Realistische und Cartoon-Optionen
- Video-zu-Video-Generierung
Zeroskop V2
Das Modelscope-basierte Videomodell zeroscope_v2_567w eignet sich hervorragend zum Erstellen hochwertiger 16:9-Videos ohne Wasserzeichen. Es wurde mit 9.923 Clips und 29.769 getaggten Frames bei einer Auflösung von 576 x 320 und 24 Bildern pro Sekunde trainiert und ist ideal für eine flüssige Videoausgabe. Dieses Modell ist für das anfängliche Rendering vor dem Hochskalieren mit zeroscope_v2_XL unter Verwendung von vid2vid in der 1111 text2video-Erweiterung konzipiert und ermöglicht eine effiziente Erkundung bei niedrigeren Auflösungen.
Durch Hochskalieren auf 1024 x 576 werden bessere Kompositionen erzielt. Zum Rendern von 30 Frames werden 7,9 GB VRAM verwendet. Zum Verwenden laden Sie die Dateien herunter und ersetzen Sie sie im entsprechenden Verzeichnis.
Die besten Ergebnisse erzielen Sie mit zeroscope_v2_XL mit einer Rauschunterdrückungsstärke zwischen 0,66 und 0,85. Bekannte Probleme sind eine suboptimale Ausgabe bei niedrigeren Auflösungen oder weniger Frames. Das Modell kann mithilfe von Diffusoren mit einfachen Installations- und Videogenerierungsschritten problemlos integriert werden.
Hauptmerkmale
- Wasserzeichenfreie Ausgabe
- Hochwertiges 16:9
- Reibungslose Videoausgabe
- Auflösung 576 x 320
- 24 Bilder pro Sekunde
- Effizientes Upscaling
- 7,9 GB VRAM-Nutzung
- Einfache Integration
VGen
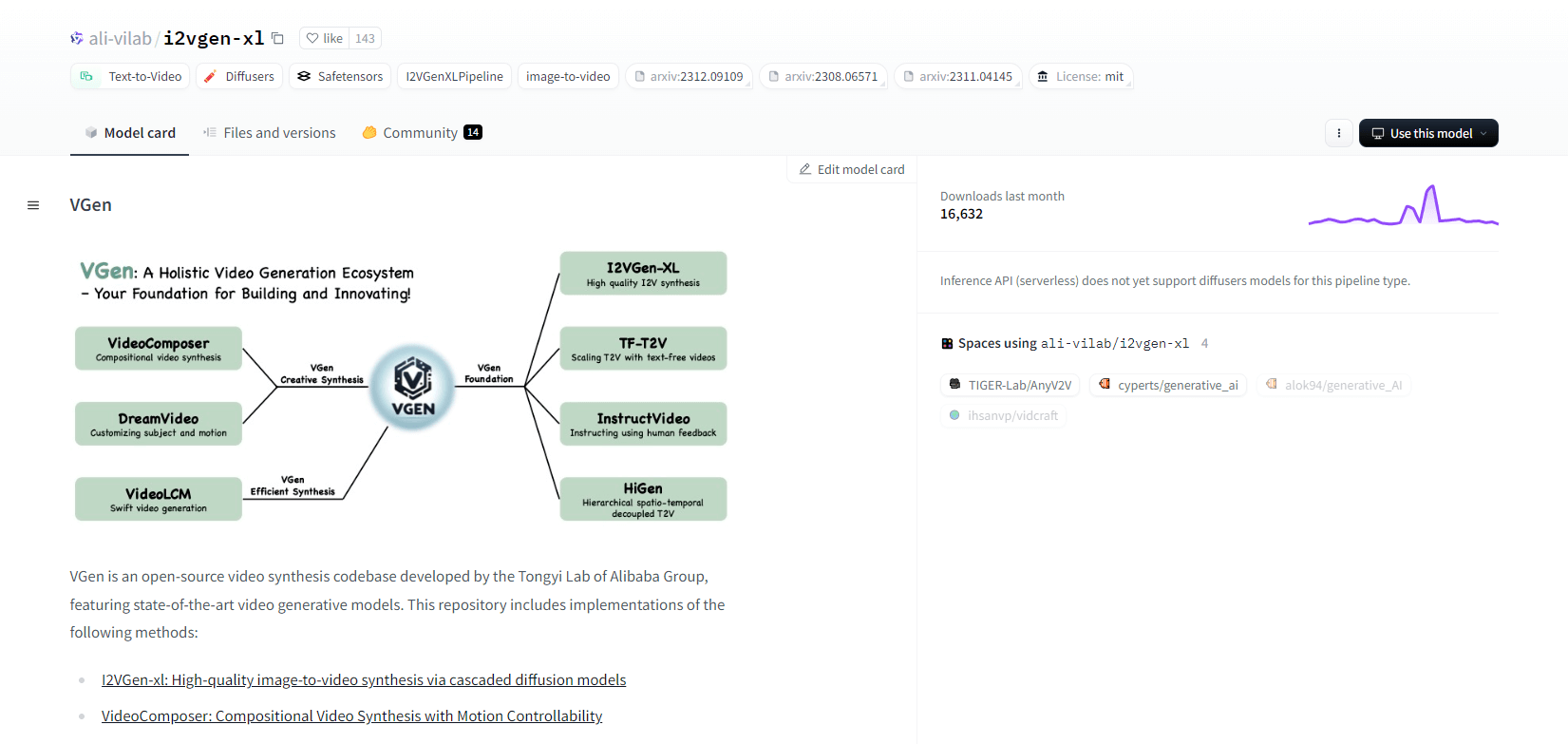
VGen, eine Open-Source-Codebasis für die Videosynthese von Alibabas Tongyi Lab, bietet fortschrittliche Videogenerierungsmodelle. Es umfasst Methoden wie I2VGen-xl für die hochwertige Bild-zu-Video-Synthese, VideoComposer für die bewegungssteuerbare Videosynthese und mehr. VGen kann hochwertige Videos aus Text, Bildern, gewünschten Bewegungen, Motiven und Feedbacksignalen erstellen. Das Repository bietet Tools für Visualisierung, Sampling, Training, Inferenz und gemeinsames Training mit Bildern und Videos. Zu den jüngsten Updates gehören VideoLCM, I2VGen-XL und die DreamVideo-Methode.
VGen zeichnet sich durch Erweiterbarkeit, Leistung und Vollständigkeit aus. Die Installation umfasst das Einrichten einer Python-Umgebung und der erforderlichen Bibliotheken. Benutzer können Text-zu-Video-Modelle trainieren und I2VGen-XL für die Generierung hochauflösender Videos ausführen. Demo-Datensätze und vorab trainierte Modelle stehen zur Verfügung, um Experimente und Optimierungen zu erleichtern. Die Codebasis gewährleistet eine einfache Verwaltung und hohe Effizienz bei Videosyntheseaufgaben.
Hauptmerkmale
- Open-Source-Codebasis
- Hochwertige Synthese
- Bewegungssteuerbarkeit
- Text-zu-Video-Generierung
- Bild-zu-Video-Konvertierung
- Erweiterbares Framework
- Vorab trainierte Modelle
- Umfassende Tools
Heißschuss XL
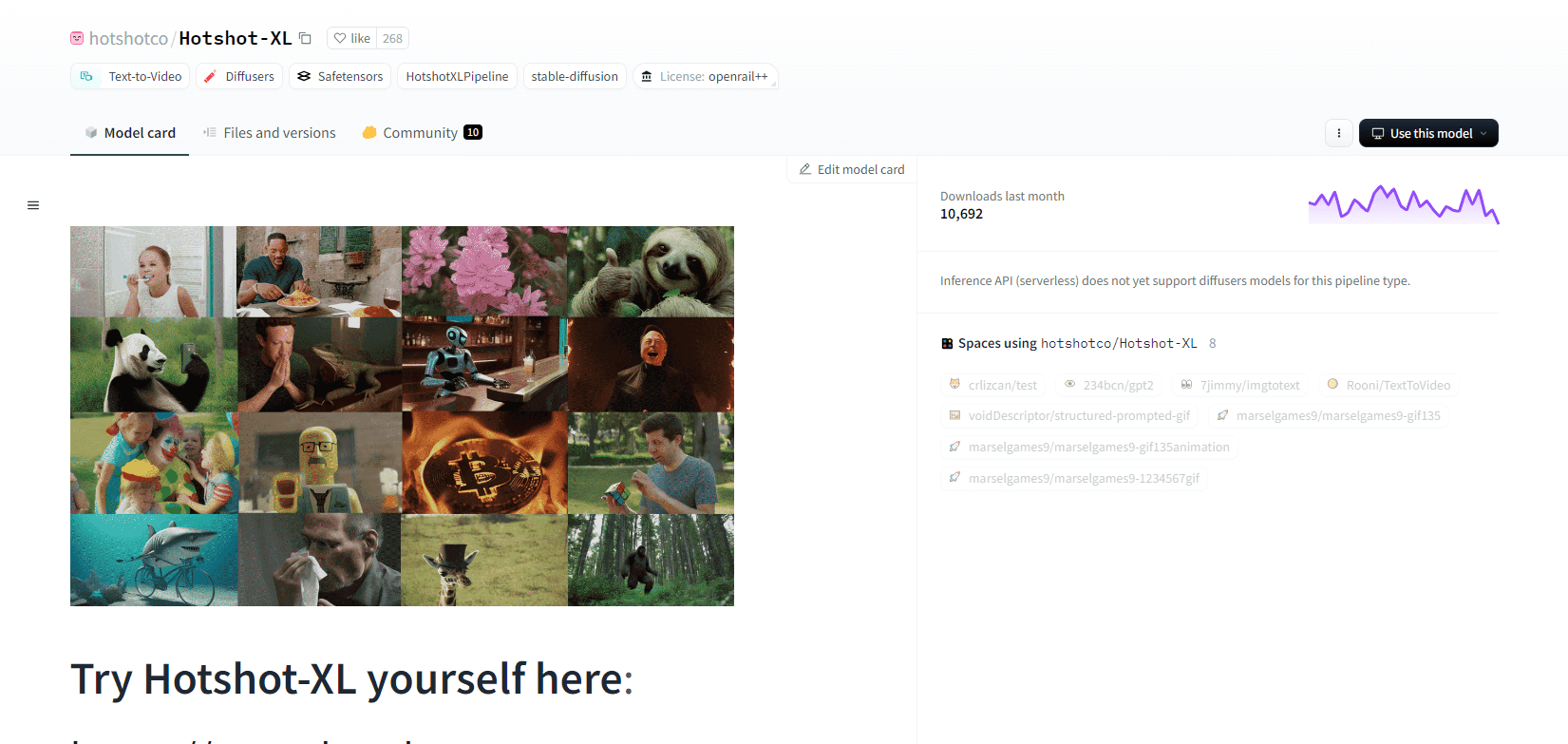
Hotshot-XL, ein KI-Text-zu-GIF-Modell, das von Natural Synthetics Inc. entwickelt wurde, arbeitet nahtlos mit Stable Diffusion XL zusammen. Es ermöglicht die GIF-Generierung mit jedem fein abgestimmten SDXL-Modell und vereinfacht so die Erstellung personalisierter GIFs ohne zusätzliche Feinabstimmung. Dieses Modell zeichnet sich durch die Generierung von 1-Sekunden-GIFs mit 8 Bildern pro Sekunde in verschiedenen Seitenverhältnissen aus. Es nutzt Latent Diffusion mit vorab trainierten Textcodierern (OpenCLIP-ViT/G und CLIP-ViT/L) für eine verbesserte Leistung.
Benutzer können GIF-Kompositionen mit SDXL ControlNet für benutzerdefinierte Layouts ändern. Hotshot-XL ist zwar in der Lage, vielseitige GIF-Dateien zu erstellen, steht jedoch vor Herausforderungen hinsichtlich Fotorealismus und komplexen Aufgaben wie dem Rendern bestimmter Kompositionen. Die Implementierung des Modells soll sich nahtlos in bestehende Arbeitsabläufe integrieren lassen und steht auf GitHub unter einer CreativeML Open RAIL++-M-Lizenz zur Erkundung zur Verfügung.
Hauptmerkmale
- Text-zu-GIF-Generierung
- Funktioniert mit SDXL
- Generiert 1-Sekunden-GIFs
- Unterstützt verschiedene Seitenverhältnisse
- Verwendet latente Diffusion
- Vortrainierte Textencoder
- Anpassbar mit ControlNet
- Verfügbar auf GitHub
Zukünftige Fähigkeiten von Text-zu-Video-KI-Modellen
Plattformen wie Hugging Face sind führend bei der Entwicklung fortschrittlicher Modelle, die Text in hochwertige, dynamische Videoinhalte umwandeln können. Dies lässt uns davon ausgehen, dass die zukünftigen Möglichkeiten von Text-zu-Video-KI-Modellen wirklich spannend sind.
Diese Modelle werden die Inhaltserstellung revolutionieren und sie schneller, effizienter und zugänglicher machen als je zuvor. Durch einfache Eingabe einer Textaufforderung können Benutzer ansprechende, benutzerdefinierte Videos erstellen, die ihre Ideen zum Leben erwecken.
Die potenziellen Anwendungen sind vielfältig – von Marketing und Werbung bis hin zu Bildung und Unterhaltung. Stellen Sie sich vor, Sie könnten mit einem Mausklick professionelle Erklärvideos oder animierte Geschichten erstellen. Die Zeit- und Kostenersparnisse für Unternehmen und Entwickler wären beträchtlich.
Und da diese Text-zu-Video-Modelle immer realistischer, stimmiger und flexibler werden, wird die Qualität der Ausgabe immer weniger von der eines von Menschen erstellten Videos zu unterscheiden sein. Diese Demokratisierung der Videoproduktion wird es mehr Menschen ermöglichen, ihre Geschichten und Ideen mit der Welt zu teilen.
Die Zukunft der Inhaltserstellung liegt zweifellos in der Text-zu-Video-Technologie, und Hugging Face steht an der Spitze dieser bahnbrechenden Technologie. Lassen Sie sich überraschen, wenn diese Modelle die Grenzen des Möglichen erweitern.
Einpacken
Zusammenfassend lässt sich sagen, dass Huggingface eine breite Palette von Modellen für Text-zu-Video-Aufgaben bietet, von denen jedes einzigartige Stärken bei der Generierung dynamischer visueller Inhalte aus Textbeschreibungen mitbringt. Unabhängig davon, ob Sie Präzision, Kreativität oder Skalierbarkeit priorisieren, bieten diese Modelle robuste Lösungen für verschiedene Anwendungen und versprechen Fortschritte bei der KI-gesteuerten Videosynthese.









