
এআই-চালিত টেক্সট-টু-ভিডিও প্রযুক্তির উত্থান আমাদের বিষয়বস্তু তৈরি এবং ব্যবহার করার পদ্ধতিতে বিপ্লব ঘটাচ্ছে। এই রূপান্তরের অগ্রভাগে রয়েছে শক্তিশালী আলিঙ্গন ফেস মডেল, যা দ্রুত সামগ্রী নির্মাতা এবং ব্যবসার জন্য একইভাবে গো-টু টুল হয়ে উঠছে।

এই অত্যাধুনিক ভাষার মডেলগুলি, বিপুল পরিমাণ ডেটার উপর প্রশিক্ষিত, লিখিত পাঠকে চিত্তাকর্ষক ভিজ্যুয়াল বর্ণনায় অনুবাদ করার অসাধারণ ক্ষমতার অধিকারী। ন্যাচারাল ল্যাঙ্গুয়েজ প্রসেসিং এবং জেনারেটিভ AI-তে সাম্প্রতিক অগ্রগতিগুলিকে কাজে লাগিয়ে, Hugging Face মডেলগুলি অনায়াসে আপনার কথাগুলিকে আকর্ষক, উচ্চ-মানের ভিডিওতে রূপান্তরিত করতে পারে যা আপনার দর্শকদের মোহিত করে৷
টেক্সট-টু-ভিডিও প্রযুক্তি বোঝা
টেক্সট-টু-ভিডিও মডেল লিখিত বর্ণনাকে চলমান ছবিতে রূপান্তরিত করে। এই মডেলগুলি পাঠ্য বোঝে এবং এটিকে ফ্রেমের একটি ক্রমানুসারে রূপান্তর করে যা বর্ণিত দৃশ্য বা ক্রিয়াকে চিত্রিত করে। এই প্রক্রিয়াটিতে পাঠ্য বিশ্লেষণ, ভিজ্যুয়াল কন্টেন্ট জেনারেশন এবং ফ্রেম সিকোয়েন্সিং সহ একাধিক ধাপ জড়িত। আউটপুট ভিডিও সঠিকভাবে ইনপুট টেক্সট উপস্থাপন করে তা নিশ্চিত করার জন্য প্রতিটি ধাপে জটিল অ্যালগরিদমের প্রয়োজন।
টেক্সট-টু-ভিডিও প্রযুক্তির যাত্রা শুরু হয়েছিল সাধারণ টেক্সট বর্ণনা যা মৌলিক অ্যানিমেশন তৈরি করে। প্রারম্ভিক মডেলগুলি স্ট্যাটিক ইমেজ তৈরির উপর দৃষ্টি নিবদ্ধ করেছিল, কিন্তু এআই এবং মেশিন লার্নিংয়ের অগ্রগতি গতিশীল ভিডিও প্রজন্মের বিকাশকে সক্ষম করেছে। বছরের পর বছর ধরে, গবেষকরা অত্যাধুনিক নিউরাল নেটওয়ার্কগুলিকে একীভূত করেছেন, যা ভিডিওর গুণমান এবং বাস্তবতার ক্ষেত্রে উল্লেখযোগ্য উন্নতি ঘটায়। এই অগ্রগতিগুলি সৃজনশীল বিষয়বস্তু তৈরি এবং শিল্প জুড়ে বিভিন্ন অ্যাপ্লিকেশনের জন্য নতুন সম্ভাবনা উন্মুক্ত করেছে।
হাগিংফেস থেকে ভিডিও এআই মডেলের জন্য 5টি সেরা পাঠ্য
এখানে আমাদের কাছে আছে 5টি সেরা AI টেক্সট-টু-ভিডিও মডেল। এই মডেলগুলি তাদের স্বতন্ত্র কার্যকারিতার জন্য খুব জনপ্রিয় এবং ডাউনলোডের সংখ্যা সর্বাধিক।
মডেলস্কোপ - 1.7 বি
মডেলস্কোপ থেকে টেক্সট-টু-ভিডিও সংশ্লেষণ মডেল টেক্সট বর্ণনা থেকে ভিডিও তৈরি করতে একটি মাল্টি-স্টেজ ডিফিউশন প্রক্রিয়া ব্যবহার করে। এই উন্নত মডেল শুধুমাত্র ইংরেজি ইনপুট সমর্থন করে এবং গবেষণার উদ্দেশ্যে ডিজাইন করা হয়েছে। এটি তিনটি সাব-নেটওয়ার্ক নিয়ে গঠিত: পাঠ্য বৈশিষ্ট্য নিষ্কাশন, পাঠ্য থেকে ভিডিও সুপ্ত স্থান বিস্তার, এবং ভিডিও সুপ্ত স্থান থেকে ভিজ্যুয়াল স্পেস ম্যাপিং।
1.7 বিলিয়ন প্যারামিটার এবং একটি UNet3D কাঠামো সহ, এটি ভিডিও তৈরি করার জন্য গাউসিয়ান শব্দকে পুনরাবৃত্তি করে। এই মডেলটি বিভিন্ন অ্যাপ্লিকেশনের জন্য উপযুক্ত, যেমন ইচ্ছাকৃত ইংরেজি পাঠ্য থেকে ভিডিও তৈরি করা। যাইহোক, এর সীমাবদ্ধতা রয়েছে, যেমন প্রশিক্ষণ ডেটা থেকে পক্ষপাতিত্ব এবং উচ্চ-মানের ফিল্ম-লেভেল ভিডিও বা স্পষ্ট পাঠ্য তৈরি করতে অক্ষমতা। ব্যবহারকারীদের অবশ্যই ক্ষতিকারক বা মিথ্যা সামগ্রী তৈরি করা এড়াতে হবে। মডেলটিকে LAION5B, ImageNet, এবং Webvid সহ পাবলিক ডেটাসেটে প্রশিক্ষণ দেওয়া হয়েছিল।
মূল বৈশিষ্ট্য
- মাল্টি-স্টেজ ডিফিউশন প্রক্রিয়া
- ইংরেজি পাঠ্য সমর্থন
- 1.7 বিলিয়ন প্যারামিটার
- UNet3D আর্কিটেকচার
- পুনরাবৃত্তিমূলক ডিনোইসিং পদ্ধতি
- গবেষণা উদ্দেশ্য ফোকাস
- পাবলিক ডেটাসেট প্রশিক্ষণ
- নির্বিচারে পাঠ্য প্রজন্ম
অ্যানিমেটডিফ-লাইটনিং
অ্যানিমেটডিফ-লাইটনিং হল একটি অত্যাধুনিক, টেক্সট-টু-ভিডিও জেনারেশন মডেল যা মূল অ্যানিমেটডিফের তুলনায় গতির উন্নতির প্রস্তাব করে, দশ গুণেরও বেশি দ্রুত ভিডিও তৈরি করে৷ AnimateDiff SD1.5 v2 থেকে তৈরি, এই মডেলটি 1-পদক্ষেপ, 2-পদক্ষেপ, 4-পদক্ষেপ, এবং 8-পদক্ষেপ সংস্করণে উপলব্ধ, উচ্চ-পদক্ষেপের মডেলগুলি উচ্চতর মানের অফার করে৷ epiCRealism এবং Realistic Vision এর মত স্টাইলাইজড বেস মডেলের সাথে সাথে Anime এবং কার্টুন মডেল যেমন ToonYou এবং Mistoon Anime এর সাথে ব্যবহার করা হলে এটি উৎকৃষ্ট।
ব্যবহারকারীরা বিভিন্ন সেটিংস, যেমন Motion LoRAs ব্যবহার করে পরীক্ষা করে সর্বোত্তম ফলাফল অর্জন করতে পারে। বাস্তবায়নের জন্য, মডেলটি Diffusers এবং ComfyUI এর সাথে ব্যবহার করা যেতে পারে। এটি উন্নত আউটপুটের জন্য কন্ট্রোলনেট সহ ভিডিও-টু-ভিডিও প্রজন্মকে সমর্থন করে। আরও বিশদ বিবরণ এবং একটি ডেমোর জন্য, ব্যবহারকারীদের গবেষণাপত্রটি উল্লেখ করতে উত্সাহিত করা হয়: অ্যানিমেটডিফ-লাইটনিং: ক্রস-মডেল ডিফিউশন ডিস্টিলেশন
মূল বৈশিষ্ট্য
- বাজ-দ্রুত ভিডিও প্রজন্ম
- অ্যানিমেটডিফ থেকে পাতিত
- একাধিক ধাপে চেকপয়েন্ট
- উচ্চ প্রজন্মের গুণমান
- স্টাইলাইজড মডেল সমর্থন করে
- মোশন LoRAs সমর্থন
- বাস্তবসম্মত এবং কার্টুন বিকল্প
- ভিডিও থেকে ভিডিও প্রজন্ম
জিরোস্কোপ V2
মডেলস্কোপ-ভিত্তিক zeroscope_v2_567w ভিডিও মডেলটি ওয়াটারমার্ক ছাড়াই উচ্চ-মানের 16:9 ভিডিও তৈরি করতে পারদর্শী। 9,923 ক্লিপ এবং 29,769 ট্যাগযুক্ত ফ্রেমে 576x320 রেজোলিউশন এবং 24 ফ্রেম প্রতি সেকেন্ডে প্রশিক্ষিত, এটি মসৃণ ভিডিও আউটপুটের জন্য আদর্শ। এই মডেলটি 1111 টেক্সট2ভিডিও এক্সটেনশনে vid2vid ব্যবহার করে zeroscope_v2_XL দিয়ে আপস্কেল করার আগে প্রাথমিক রেন্ডারিংয়ের জন্য ডিজাইন করা হয়েছে, কম রেজোলিউশনে দক্ষ অনুসন্ধানের অনুমতি দেয়।
1024x576 পর্যন্ত উচ্চতর কম্পোজিশন প্রদান করে। এটি 30টি ফ্রেম রেন্ডার করার জন্য 7.9GB VRAM ব্যবহার করে। উপযুক্ত ডিরেক্টরিতে ফাইলগুলি ব্যবহার, ডাউনলোড এবং প্রতিস্থাপন করতে।
সর্বোত্তম ফলাফলের জন্য, 0.66 এবং 0.85 এর মধ্যে ডিনোইস শক্তি সহ zeroscope_v2_XL ব্যবহার করে আপস্কেল করুন। পরিচিত সমস্যাগুলির মধ্যে নিম্ন রেজোলিউশন বা কম ফ্রেমে সাবঅপ্টিমাল আউটপুট অন্তর্ভুক্ত। মডেলটি সহজ ইনস্টলেশন এবং ভিডিও তৈরির ধাপগুলির সাথে ডিফিউজার ব্যবহার করে সহজেই একত্রিত করা যেতে পারে।
মূল বৈশিষ্ট্য
- ওয়াটারমার্ক-মুক্ত আউটপুট
- উচ্চ-মানের 16:9
- মসৃণ ভিডিও আউটপুট
- 576x320 রেজোলিউশন
- প্রতি সেকেন্ডে 24 ফ্রেম
- দক্ষ আপস্কেলিং
- 7.9GB VRAM ব্যবহার
- সহজ ইন্টিগ্রেশন
ভিজেন
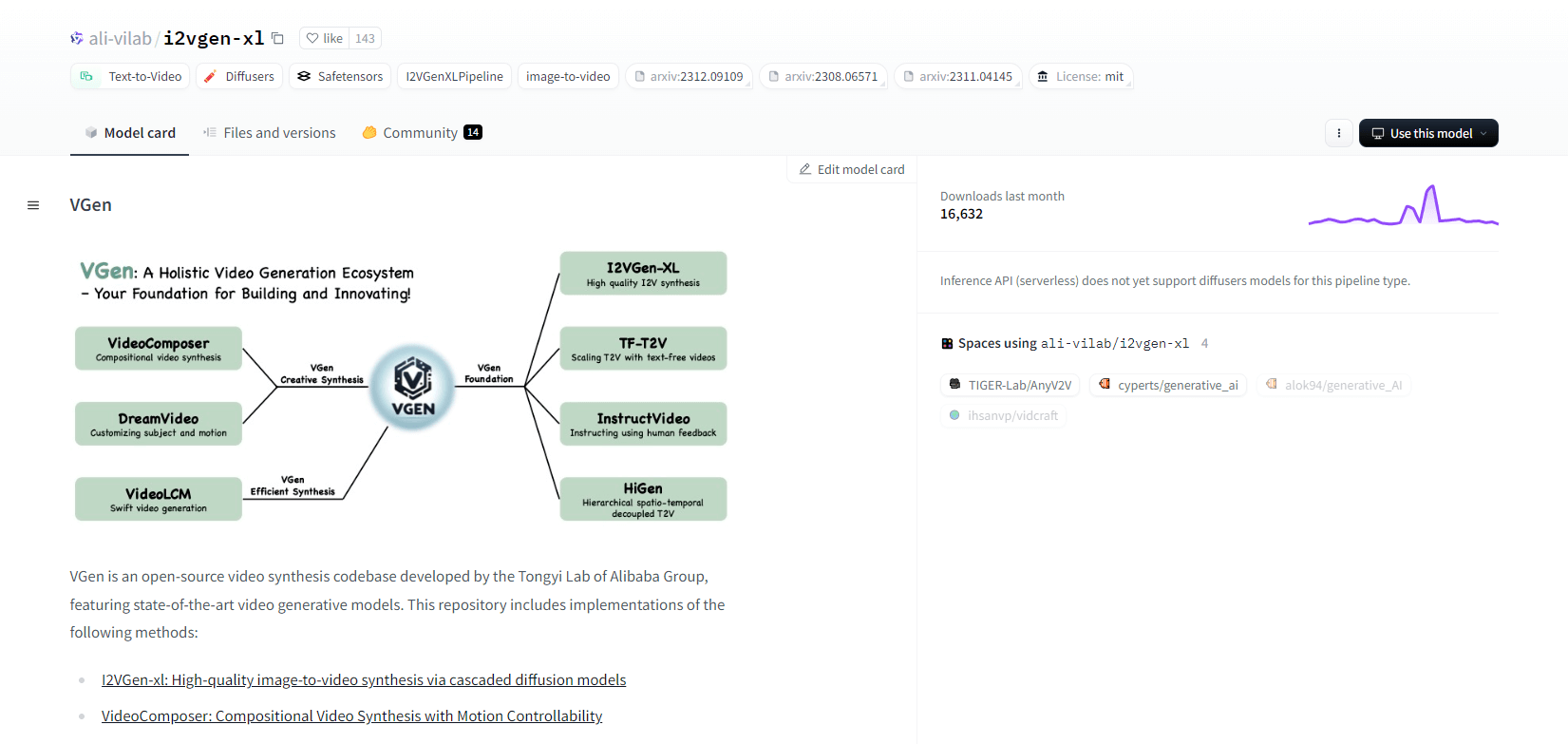
ভিজেন, আলিবাবার টঙ্গি ল্যাব থেকে একটি ওপেন-সোর্স ভিডিও সংশ্লেষণ কোডবেস, উন্নত ভিডিও জেনারেটিভ মডেল অফার করে। এতে উচ্চ-মানের ইমেজ-টু-ভিডিও সংশ্লেষণের জন্য I2VGen-xl, গতি-নিয়ন্ত্রণযোগ্য ভিডিও সংশ্লেষণের জন্য ভিডিও কম্পোজার এবং আরও অনেক কিছুর মতো পদ্ধতি অন্তর্ভুক্ত রয়েছে। VGen পাঠ্য, ছবি, পছন্দসই গতি, বিষয় এবং প্রতিক্রিয়া সংকেত থেকে উচ্চ মানের ভিডিও তৈরি করতে পারে। সংগ্রহস্থলটিতে চিত্র এবং ভিডিও ব্যবহার করে ভিজ্যুয়ালাইজেশন, স্যাম্পলিং, প্রশিক্ষণ, অনুমান এবং যৌথ প্রশিক্ষণের সরঞ্জাম রয়েছে। সাম্প্রতিক আপডেটের মধ্যে রয়েছে VideoLCM, I2VGen-XL, এবং DreamVideo পদ্ধতি।
VGen প্রসারণযোগ্যতা, কর্মক্ষমতা, এবং সম্পূর্ণতায় উৎকর্ষ। ইনস্টলেশনের সাথে একটি পাইথন পরিবেশ এবং প্রয়োজনীয় লাইব্রেরি সেট আপ করা জড়িত। ব্যবহারকারীরা টেক্সট-টু-ভিডিও মডেল প্রশিক্ষণ দিতে পারে এবং হাই-ডেফিনিশন ভিডিও জেনারেশনের জন্য I2VGen-XL চালাতে পারে। ডেমো ডেটাসেট এবং প্রাক-প্রশিক্ষিত মডেলগুলি পরীক্ষা এবং অপ্টিমাইজেশনের সুবিধার্থে উপলব্ধ। কোডবেস ভিডিও সংশ্লেষণের কাজগুলিতে সহজ ব্যবস্থাপনা এবং উচ্চ দক্ষতা নিশ্চিত করে।
মূল বৈশিষ্ট্য
- ওপেন সোর্স কোডবেস
- উচ্চ মানের সংশ্লেষণ
- গতি নিয়ন্ত্রণযোগ্যতা
- পাঠ্য থেকে ভিডিও প্রজন্ম
- ছবি থেকে ভিডিও রূপান্তর
- প্রসারণযোগ্য কাঠামো
- প্রাক-প্রশিক্ষিত মডেল
- ব্যাপক সরঞ্জাম
হটশট এক্সএল
Hotshot-XL, Natural Synthetics Inc. দ্বারা তৈরি একটি AI টেক্সট-টু-GIF মডেল, স্টেবল ডিফিউশন XL-এর সাথে নির্বিঘ্নে কাজ করে। এটি অতিরিক্ত সূক্ষ্ম-টিউনিং ছাড়াই ব্যক্তিগতকৃত GIF তৈরিকে সহজ করে, যেকোনো সূক্ষ্ম-টিউনড SDXL মডেল ব্যবহার করে GIF তৈরি করতে সক্ষম করে। এই মডেলটি বিভিন্ন আকৃতির অনুপাত জুড়ে প্রতি সেকেন্ডে 8 ফ্রেমে 1-সেকেন্ডের GIF তৈরি করতে পারদর্শী। এটি উন্নত কর্মক্ষমতার জন্য প্রাক প্রশিক্ষিত টেক্সট এনকোডার (OpenCLIP-ViT/G এবং CLIP-ViT/L) সহ সুপ্ত বিস্তার লাভ করে।
ব্যবহারকারীরা কাস্টমাইজড লেআউটের জন্য SDXL ControlNet ব্যবহার করে GIF কম্পোজিশন পরিবর্তন করতে পারেন। বহুমুখী GIF তৈরিতে সক্ষম হলেও, Hotshot-XL ফটোরিয়েলিজম এবং নির্দিষ্ট কম্পোজিশন রেন্ডার করার মতো জটিল কাজগুলির সাথে চ্যালেঞ্জের সম্মুখীন হয়। মডেলটির বাস্তবায়নের লক্ষ্য বিদ্যমান ওয়ার্কফ্লোতে মসৃণভাবে সংহত করা এবং একটি CreativeML ওপেন RAIL++-M লাইসেন্সের অধীনে GitHub-এ অনুসন্ধানের জন্য উপলব্ধ।
মূল বৈশিষ্ট্য
- টেক্সট-টু-জিআইএফ প্রজন্ম
- SDXL এর সাথে কাজ করে
- 1-সেকেন্ডের GIF তৈরি করে
- বিভিন্ন আকৃতির অনুপাত সমর্থন করে
- সুপ্ত প্রসারণ ব্যবহার করে
- পূর্বপ্রশিক্ষিত পাঠ্য এনকোডার
- ControlNet সঙ্গে কাস্টমাইজযোগ্য
- GitHub এ উপলব্ধ
টেক্সট টু ভিডিও এআই মডেলের ভবিষ্যত ক্ষমতা
আলিঙ্গন মুখের মতো প্ল্যাটফর্মগুলি উন্নত মডেলগুলি বিকাশের পথে নেতৃত্ব দিচ্ছে যা পাঠ্যকে উচ্চ-মানের, গতিশীল ভিডিও সামগ্রীতে রূপান্তর করতে পারে। এটি আমাদের একটি অনুমানের দিকে নিয়ে যায় যে - পাঠ্য থেকে ভিডিও এআই মডেলের ভবিষ্যত ক্ষমতা সত্যিই উত্তেজনাপূর্ণ।
এই মডেলগুলি বিষয়বস্তু তৈরিতে বিপ্লব ঘটাতে প্রস্তুত, এটিকে আগের চেয়ে দ্রুত, আরও দক্ষ এবং আরও অ্যাক্সেসযোগ্য করে তোলে৷ শুধুমাত্র একটি টেক্সট প্রম্পট ইনপুট করার মাধ্যমে, ব্যবহারকারীরা আকর্ষক, কাস্টমাইজড ভিডিও তৈরি করতে সক্ষম হবেন যা তাদের ধারণাগুলিকে জীবন্ত করে তোলে।
সম্ভাব্য অ্যাপ্লিকেশনগুলি বিশাল - বিপণন এবং বিজ্ঞাপন থেকে শিক্ষা এবং বিনোদন পর্যন্ত। একটি বোতামের ক্লিকে পেশাদার-গ্রেড ব্যাখ্যাকারী ভিডিও বা অ্যানিমেটেড গল্প তৈরি করতে সক্ষম হওয়ার কল্পনা করুন। ব্যবসা এবং নির্মাতাদের জন্য সময় এবং খরচ সাশ্রয় যথেষ্ট হবে।
অধিকন্তু, এই পাঠ্য-টু-ভিডিও মডেলগুলি বাস্তবতা, সুসংগততা এবং নমনীয়তার পরিপ্রেক্ষিতে উন্নতি করতে থাকলে, আউটপুটের গুণমান মানব-সৃষ্ট ভিডিও থেকে ক্রমশ আলাদা করা যায় না। ভিডিও উত্পাদনের এই গণতন্ত্রীকরণ আরও বেশি লোককে তাদের গল্প এবং ধারণাগুলি বিশ্বের সাথে ভাগ করে নেওয়ার ক্ষমতা দেবে৷
বিষয়বস্তু তৈরির ভবিষ্যৎ নিঃসন্দেহে টেক্সট-টু-ভিডিও, এবং এই রূপান্তরকারী প্রযুক্তির অগ্রভাগে রয়েছে Hugging Face। এই মডেলগুলি যা সম্ভব তার সীমানা ঠেলে বিস্মিত হওয়ার জন্য প্রস্তুত হন৷
আপ মোড়ানো
উপসংহারে, Huggingface টেক্সট-টু-ভিডিও টাস্কের জন্য বিভিন্ন ধরণের মডেল অফার করে, প্রতিটি পাঠ্য বিবরণ থেকে গতিশীল ভিজ্যুয়াল সামগ্রী তৈরিতে অনন্য শক্তি নিয়ে আসে। আপনি নির্ভুলতা, সৃজনশীলতা বা মাপযোগ্যতাকে অগ্রাধিকার দেন না কেন, এই মডেলগুলি বিভিন্ন অ্যাপ্লিকেশনের জন্য শক্তিশালী সমাধান প্রদান করে, AI-চালিত ভিডিও সংশ্লেষণে প্রতিশ্রুতিশীল অগ্রগতি।







