
আলিঙ্গন মুখ প্রাকৃতিক ভাষা প্রক্রিয়াকরণের জন্য যে কারো জন্য একটি সোনার খনি, যা বিভিন্ন ধরনের প্রাক-প্রশিক্ষিত ভাষা মডেলের সাথে পরিপূর্ণ যা বিভিন্ন অ্যাপ্লিকেশনে ব্যবহার করা খুবই সহজ। লার্জ ল্যাঙ্গুয়েজ মডেলের (এলএলএম) কথা আসলে, আলিঙ্গন করা মুখটি শীর্ষ পছন্দ। এই অংশে, আমরা আলিঙ্গন মুখের শীর্ষ 10টি এলএলএম-এর মধ্যে ডুব দেব, প্রত্যেকটি কীভাবে আমরা ভাষা বুঝতে এবং তৈরি করি তা অগ্রসর করতে অগ্রণী ভূমিকা পালন করে।

চল শুরু করি!
বড় ভাষা মডেল কি?
লার্জ ল্যাঙ্গুয়েজ মডেল (LLMs) হল উন্নত ধরনের কৃত্রিম বুদ্ধিমত্তা যা মানুষের ভাষা বোঝা এবং তৈরি করার জন্য ডিজাইন করা হয়েছে। এগুলি গভীর শিক্ষার কৌশল ব্যবহার করে তৈরি করা হয়, বিশেষ করে এক ধরণের নিউরাল নেটওয়ার্ক যাকে ট্রান্সফরমার বলা হয়।
এটি পরিষ্কার করার জন্য এখানে একটি ব্রেকডাউন রয়েছে:
- বিশাল ডেটার উপর প্রশিক্ষণ : এলএলএমগুলিকে বিশাল ডেটাসেটের উপর প্রশিক্ষণ দেওয়া হয় যার মধ্যে বই, নিবন্ধ, ওয়েবসাইট এবং আরও অনেক কিছু রয়েছে। এই ব্যাপক প্রশিক্ষণ তাদের ভাষার সূক্ষ্মতা শিখতে সাহায্য করে, যার মধ্যে ব্যাকরণ, প্রসঙ্গ এবং এমনকি কিছু স্তরের যুক্তিও রয়েছে।
- ট্রান্সফরমার : বেশিরভাগ এলএলএম-এর পিছনের আর্কিটেকচারকে ট্রান্সফরমার বলা হয়। এই মডেলটি একটি বাক্যে বিভিন্ন শব্দের গুরুত্বকে ওজন করার জন্য মনোযোগের প্রক্রিয়া ব্যবহার করে, এটিকে পূর্ববর্তী মডেলগুলির তুলনায় প্রসঙ্গটি আরও ভালভাবে বোঝার অনুমতি দেয়।
- তারা যে কাজগুলি সঞ্চালন করে : একবার প্রশিক্ষিত হলে, এলএলএমরা বিভিন্ন ভাষার কাজ সম্পাদন করতে পারে। এর মধ্যে রয়েছে প্রশ্নের উত্তর দেওয়া, পাঠ্যের সংক্ষিপ্তকরণ, ভাষা অনুবাদ করা, সৃজনশীল লেখা তৈরি করা এবং কোডিং।
- জনপ্রিয় মডেল : কিছু সুপরিচিত এলএলএম-এর মধ্যে রয়েছে GPT-3, BERT, এবং T5। এই প্রাক-প্রশিক্ষিত মডেলগুলি নির্দিষ্ট কাজের জন্য সূক্ষ্মভাবে তৈরি করা যেতে পারে, যা তাদের ডেভেলপার এবং গবেষকদের জন্য বহুমুখী সরঞ্জাম তৈরি করে।
- অ্যাপ্লিকেশন : এলএলএমগুলি চ্যাটবট, ভার্চুয়াল সহকারী, স্বয়ংক্রিয় সামগ্রী তৈরি এবং আরও অনেক কিছুতে ব্যবহৃত হয়। তারা প্রযুক্তির সাথে ব্যবহারকারীর মিথস্ক্রিয়া উন্নত করতে সাহায্য করে যাতে মেশিনগুলিকে মানুষের ভাষা আরও স্বাভাবিকভাবে বুঝতে এবং প্রতিক্রিয়া জানায়।
সংক্ষেপে, বড় ভাষার মডেলগুলি কম্পিউটারের জন্য সুপারচার্জড মস্তিষ্কের মতো, যা তাদের চিত্তাকর্ষক নির্ভুলতা এবং বহুমুখিতা সহ মানব ভাষা পরিচালনা এবং তৈরি করতে সক্ষম করে।
আলিঙ্গন মুখ এবং এলএলএম
Hugging Face হল একটি কোম্পানি এবং একটি প্ল্যাটফর্ম যা প্রাকৃতিক ভাষা প্রক্রিয়াকরণ (NLP) এবং মেশিন লার্নিং এর একটি কেন্দ্র হয়ে উঠেছে। তারা ডেভেলপার এবং গবেষকদের মেশিন লার্নিং মডেল, বিশেষ করে ভাষা বোঝা এবং প্রজন্মের সাথে সম্পর্কিত যেগুলি তৈরি এবং ব্যবহার করা সহজ করে তার জন্য সরঞ্জাম, লাইব্রেরি এবং সংস্থান সরবরাহ করে।
আলিঙ্গন মুখ তার ওপেন-সোর্স লাইব্রেরির জন্য পরিচিত, বিশেষ করে Transformers , যেটি প্রি-প্রশিক্ষিত ভাষার মডেলের বিস্তৃত পরিসরে সহজে অ্যাক্সেস প্রদান করে।
হাগিং ফেস অনেক অত্যাধুনিক এলএলএম যেমন GPT-3, BERT, এবং T5 হোস্ট করে। এই মডেলগুলি বিশাল ডেটাসেটে প্রাক-প্রশিক্ষিত এবং বিভিন্ন অ্যাপ্লিকেশনের জন্য ব্যবহার করার জন্য প্রস্তুত।
প্ল্যাটফর্মটি মেশিন লার্নিংয়ে গভীর দক্ষতার প্রয়োজন ছাড়াই অ্যাপ্লিকেশনগুলিতে এই মডেলগুলিকে একীভূত করার জন্য সহজ API এবং সরঞ্জাম সরবরাহ করে।
আলিঙ্গন মুখের সরঞ্জামগুলি ব্যবহার করে, আপনি সহজেই আপনার নিজের ডেটাতে এই প্রাক-প্রশিক্ষিত এলএলএমগুলিকে সূক্ষ্ম-টিউন করতে পারেন, যা আপনাকে নির্দিষ্ট কাজ বা ডোমেনে তাদের মানিয়ে নিতে দেয়।
গবেষক এবং বিকাশকারীরা তাদের মডেল এবং বর্ধিতকরণগুলিকে আলিঙ্গন ফেস প্ল্যাটফর্মে শেয়ার করতে পারে, এনএলপি-তে উদ্ভাবন এবং প্রয়োগকে ত্বরান্বিত করে।
আলিঙ্গনমুখে শীর্ষ 5 টি এলএলএম মডেল আপনার ব্যবহার করা উচিত
আসুন হাগিং ফেস-এ কিছু শীর্ষ LLM মডেলগুলি অন্বেষণ করি যা গল্প বলার ক্ষেত্রে পারদর্শী এবং এমনকি GPT-কেও ছাড়িয়ে যায়৷
Mistral-7B-v0.1
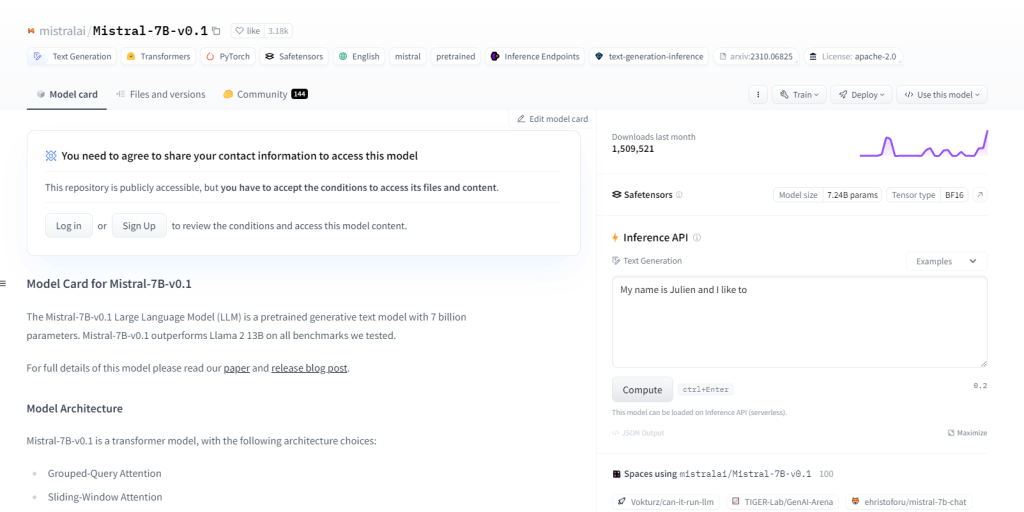
Mistral-7B-v0.1, 7 বিলিয়ন প্যারামিটার সহ একটি লার্জ ল্যাঙ্গুয়েজ মডেল (LLM), ডোমেইন জুড়ে Llama 2 13B এর মতো বেঞ্চমার্ককে ছাড়িয়ে যায়। এটি নির্দিষ্ট মনোযোগের প্রক্রিয়া এবং একটি বাইট-ফলব্যাক BPE টোকেনাইজার সহ ট্রান্সফরমার আর্কিটেকচার ব্যবহার করে। এটি টেক্সট জেনারেশন, প্রাকৃতিক ভাষা বোঝার, ভাষা অনুবাদে পারদর্শী এবং NLP প্রকল্পগুলিতে গবেষণা ও উন্নয়নের জন্য একটি বেস মডেল হিসাবে কাজ করে।
মুখ্য সুবিধা
- 7 বিলিয়ন প্যারামিটার
- Llama 213B এর মত বেঞ্চমার্ক অতিক্রম করে
- ট্রান্সফরমার আর্কিটেকচার
- BPE টোকেনাইজার
- এনএলপি প্রকল্প উন্নয়ন
- প্রাকৃতিক ভাষা বোঝা
- ভাষা অনুবাদ
- দলবদ্ধ-কোয়েরি মনোযোগ
Starling-LM-11B-আলফা
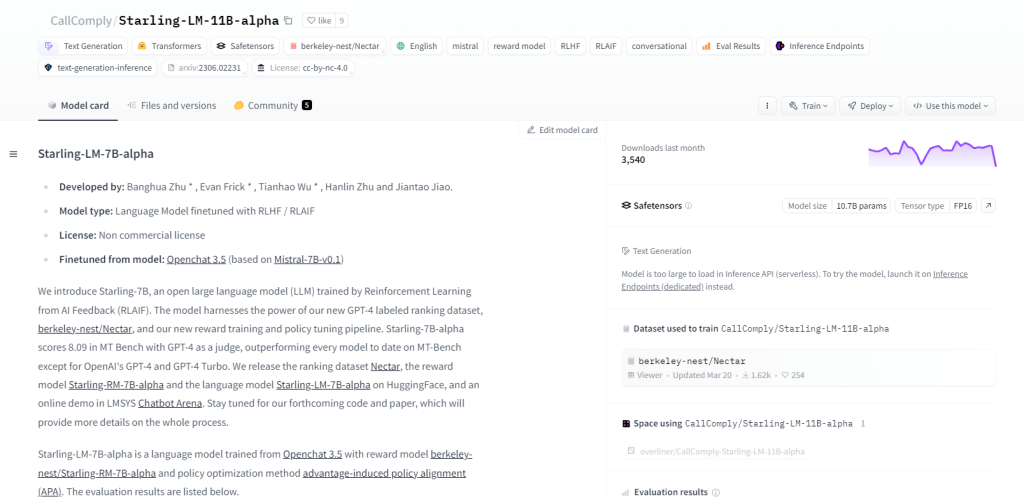
Starling-LM-11B-alpha, 11 বিলিয়ন প্যারামিটার সহ একটি বৃহৎ ভাষা মডেল (LLM), NurtureAI থেকে উদ্ভূত হয়েছে, OpenChat 3.5 মডেলটিকে এর ভিত্তি হিসেবে ব্যবহার করছে। মানব-লেবেলযুক্ত র্যাঙ্কিং দ্বারা পরিচালিত AI ফিডব্যাক (RLAIF) থেকে রিইনফোর্সমেন্ট লার্নিং এর মাধ্যমে ফাইন-টিউনিং অর্জন করা হয়। এই মডেলটি তার ওপেন-সোর্স ফ্রেমওয়ার্ক এবং NLP কাজ, মেশিন লার্নিং গবেষণা, শিক্ষা, এবং সৃজনশীল বিষয়বস্তু তৈরি সহ বহুমুখী অ্যাপ্লিকেশনগুলির সাথে মানব-মেশিন মিথস্ক্রিয়াকে নতুন আকার দেওয়ার প্রতিশ্রুতি দেয়।
মুখ্য সুবিধা
- 11 বিলিয়ন প্যারামিটার
- NurtureAI দ্বারা বিকশিত
- OpenChat 3.5 মডেলের উপর ভিত্তি করে
- RLAIF এর মাধ্যমে ফাইন টিউন করা হয়েছে
- প্রশিক্ষণের জন্য মানব-লেবেলযুক্ত র্যাঙ্কিং
- ওপেন সোর্স প্রকৃতি
- বৈচিত্র্যময় ক্ষমতা
- গবেষণা, শিক্ষা, এবং সৃজনশীল বিষয়বস্তু তৈরির জন্য ব্যবহার করুন
Yi-34B-লামা
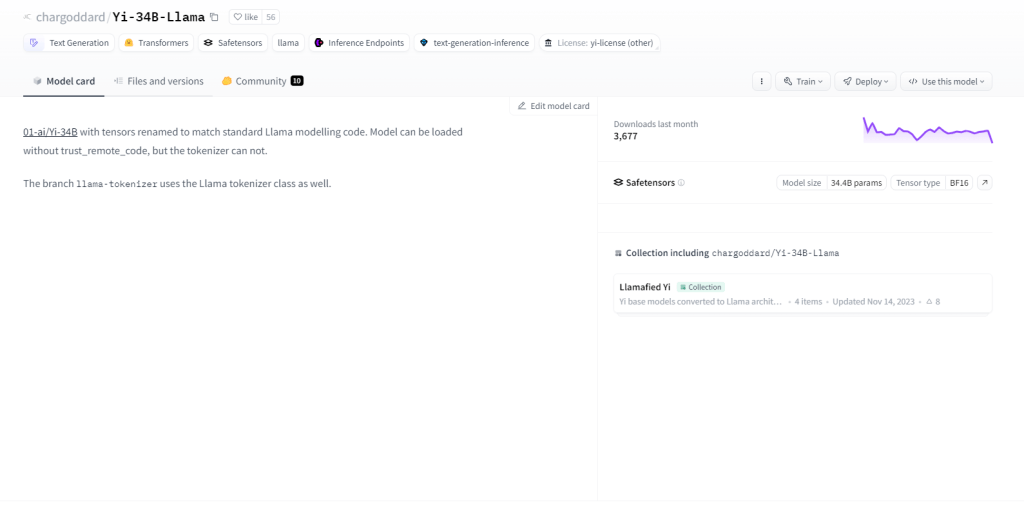
Yi-34B-Llama, এর 34 বিলিয়ন প্যারামিটার সহ, উচ্চতর শেখার ক্ষমতা প্রদর্শন করে। এটি মাল্টি-মোডাল প্রক্রিয়াকরণে, পাঠ্য, কোড এবং চিত্রগুলি দক্ষতার সাথে পরিচালনা করে। জিরো-শট লার্নিংকে আলিঙ্গন করে, এটি নির্বিঘ্নে নতুন কাজের সাথে খাপ খায়। এর রাষ্ট্রীয় প্রকৃতি এটিকে অতীতের মিথস্ক্রিয়া মনে রাখতে সক্ষম করে, ব্যবহারকারীর ব্যস্ততা বাড়ায়। ব্যবহারের ক্ষেত্রে টেক্সট জেনারেশন, মেশিন অনুবাদ, প্রশ্নের উত্তর, সংলাপ, কোড জেনারেশন এবং ইমেজ ক্যাপশন অন্তর্ভুক্ত।
মুখ্য সুবিধা
- 34 বিলিয়ন প্যারামিটার
- মাল্টি-মডেল প্রক্রিয়াকরণ
- জিরো-শট শেখার ক্ষমতা
- রাষ্ট্রীয় প্রকৃতি
- পাঠ্য প্রজন্ম
- যন্ত্রানুবাদ
- প্রশ্নের উত্তর
- ছবির ক্যাপশনিং
DeepSeek LLM 67B বেস
DeepSeek LLM 67B বেস, একটি 67-বিলিয়ন প্যারামিটার বড় ভাষা মডেল (LLM), যুক্তি, কোডিং এবং গণিতের কাজগুলিতে উজ্জ্বল। GPT-3.5 এবং Llama2 70B বেসকে ছাড়িয়ে ব্যতিক্রমী স্কোর সহ, এটি কোড বোঝার এবং প্রজন্মের ক্ষেত্রে উৎকৃষ্ট এবং অসাধারণ গণিত দক্ষতা প্রদর্শন করে। MIT লাইসেন্সের অধীনে এর ওপেন-সোর্স প্রকৃতি বিনামূল্যে অনুসন্ধান সক্ষম করে। কেস স্প্যান প্রোগ্রামিং, শিক্ষা, গবেষণা, বিষয়বস্তু তৈরি, অনুবাদ, এবং প্রশ্ন-উত্তর ব্যবহার করুন।
মুখ্য সুবিধা
- 67 বিলিয়ন প্যারামিটার
- যুক্তি, কোডিং এবং গণিতে ব্যতিক্রমী কর্মক্ষমতা
- HumanEval Pass@1 স্কোর 73.78
- অসামান্য কোড বোঝার এবং প্রজন্ম
- GSM8K 0-শটে উচ্চ স্কোর (84.1)
- ভাষার ক্ষমতায় GPT-3.5কে ছাড়িয়ে যায়
- MIT লাইসেন্সের অধীনে ওপেন সোর্স
- চমৎকার গল্প বলার এবং বিষয়বস্তু তৈরির ক্ষমতা।
Skote - Svelte অ্যাডমিন এবং ড্যাশবোর্ড টেমপ্লেট
Marcoroni-7B-v3 একটি শক্তিশালী 7-বিলিয়ন প্যারামিটার বহুভাষিক জেনারেটিভ মডেল যা পাঠ্য তৈরি, ভাষা অনুবাদ, সৃজনশীল বিষয়বস্তু তৈরি এবং প্রশ্নের উত্তর সহ বিভিন্ন কাজ করতে সক্ষম। এটি টেক্সট এবং কোড উভয় প্রক্রিয়াকরণে পারদর্শী, পূর্ব প্রশিক্ষণ ছাড়াই দ্রুত টাস্ক পারফরম্যান্সের জন্য জিরো-শট লার্নিং ব্যবহার করে। ওপেন-সোর্স এবং একটি অনুমতিমূলক লাইসেন্সের অধীনে, Marcoroni-7B-v3 ব্যাপক ব্যবহার এবং পরীক্ষা-নিরীক্ষার সুবিধা দেয়।
মুখ্য সুবিধা
- কবিতা, কোড, স্ক্রিপ্ট, ইমেল এবং আরও অনেক কিছুর জন্য পাঠ্য প্রজন্ম।
- উচ্চ-নির্ভুলতা মেশিন অনুবাদ।
- প্রাকৃতিক কথোপকথনের সাথে আকর্ষক চ্যাটবট তৈরি করা।
- প্রাকৃতিক ভাষার বর্ণনা থেকে কোড জেনারেশন।
- ব্যাপক প্রশ্ন-উত্তর করার ক্ষমতা।
- সংক্ষিপ্ত সারাংশে দীর্ঘ পাঠ্যের সারসংক্ষেপ।
- আসল অর্থ সংরক্ষণ করার সময় কার্যকরী প্যারাফ্রেজিং।
- পাঠ্য বিষয়বস্তুর জন্য অনুভূতি বিশ্লেষণ।
মোড়ক উম্মচন
Hugging Face-এর বৃহৎ ভাষার মডেলের সংগ্রহ ডেভেলপার, গবেষক এবং উত্সাহীদের জন্য একটি গেম-চেঞ্জার। এই মডেলগুলি তাদের বৈচিত্র্যময় স্থাপত্য এবং ক্ষমতার জন্য প্রাকৃতিক ভাষা বোঝার এবং প্রজন্মের সীমানা ঠেলে একটি বড় ভূমিকা পালন করে। প্রযুক্তির বিকাশের সাথে সাথে এই মডেলগুলির প্রয়োগ এবং প্রভাব অবিরাম। বৃহৎ ভাষার মডেলগুলির সাথে অন্বেষণ এবং উদ্ভাবনের যাত্রা চলছে, সামনে উত্তেজনাপূর্ণ উন্নয়নের প্রতিশ্রুতি।







